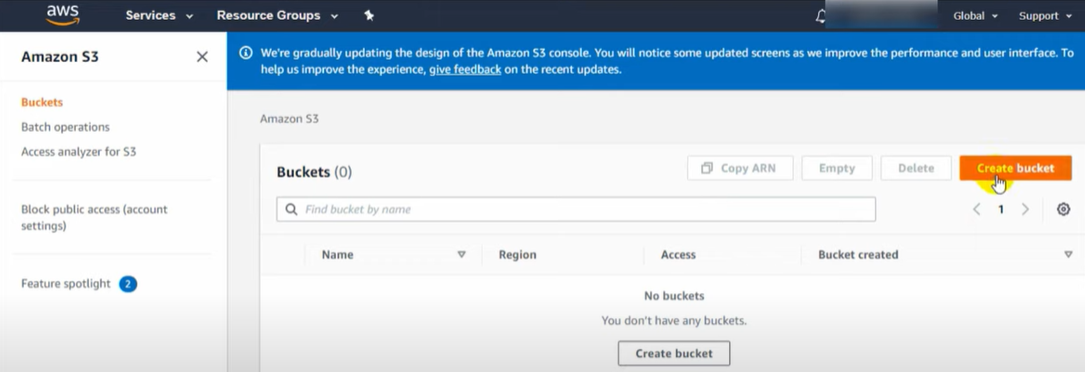
AWS offers a wide range of storage services that can be provisioned depending on your project requirements and use case. AWS storage services have different provisions for highly confidential data, frequently accessed data, and the not so frequently accessed data. You can choose from various storage types namely, object storage, file storage, block storage services, backups, and data migration options. All of which fall under the AWS Storage Services list.
AWS Glacier: From the aforementioned list, AWS Glacier, is the backup and archival storage provided by AWS. It is an extremely low cost, long term, durable, secure storage service that is ideal for backups and archival needs. In a lot of its operation AWS Glacier is similar to S3, and, it interacts directly with S3, using S3-lifecycle policies. However, the main difference between AWS S3 and Glacier is the cost structure. The cost of storing the same amount of data in AWS Glacier is significantly less as compared to S3. Storage costs in Glacier can be as little as $1 for one petabyte of data per month.
AWS Glacier Terminology
1. Vaults: Vaults are virtual containers that are used to store data. Vaults in AWS Glacier are similar to buckets in S3.
- Each Vault has its specific access policies(Vault lock/access policies). Thus providing you with more control over who has what kind of access to your data.
- Vaults are region-specific.
2. Archives: Archives are the fundamental entity type stored in Vaults. Archives in AWS Glacier are similar to Objects in S3. Virtually you have unlimited storage capacity on AWS Glacier and hence, can store an unlimited number of archives in a vault.
3. Vault Access Policies: In addition to the basic IAM controls AWS Glacier offers Vault access policies that help managers and administrators have more granular control of their data.
- Each vault has its own set of Vault Access Policies.
- If either of Vault Access Policy or IAM control doesn’t pass for some user action. The user is not declared unauthorized.
4. Vault Lock Policies: Vault lock policies are exactly like Vault access policies but once set, they cannot be changed.
- Specific to each bucket.
- This helps you with data compliance controls. For example- Your business administrators might want some highly confidential data to be only accessible to the root user of the account, no matter what. Vault lock policy for such a use case can be written for the required vaults.
Features of AWS Glacier
- Given the extremely cheap storage, provided by AWS Glacier, it doesn’t provide as many features as AWS S3. Access to data in AWS Glacier is an extremely slow process.
- Just like S3, AWS Glacier can essentially store all kinds of data types and objects.
- Durability: AWS Glacier, just like Amazon S3, claims to have a 99.9999999% of durability (11 9’s). This means the possibility of losing your data stored in one of these services one in a billion. AWS Glacier replicates data across multiple Availability Zones for providing high durability.
- Data Retrieval Time: Data retrieval from AWS Glacier can be as fast as 1-5 minutes (high-cost retrieval) to 5-12 hours(cheap data retrieval).
- AWS Glacier Console: The AWS Glacier dashboard is not as intuitive and friendly as AWS S3. The Glacier console can only be used to create vaults. Data transfer to and from AWS Glacier can only be done via some kind of code. This functionality is provided via:
- AWS Glacier API
- AWS SDKs
- Region-specific costs: The cost of storing data in AWS Glacier varies from region to region.
- Security:
- AWS Glacier automatically encrypts your data using the AES-256 algorithm and manages its keys for you.
- Apart from normal IAM controls AWS Glacier also has resource policies (vault access policies and vault lock policies) that can be used to manage access to your Glacier vaults.
- Infinite Storage Capacity: Virtually AWS Glacier is supposed to have infinite storage capacity.
Data Transfer In Glacier
1. Data Upload:
- Data can be uploaded to AWS Glacier by creating a vault from the Glacier console and using one of the following methods:
- Write code that uses AWS Glacier SDK to upload data.
- Write code that uses AWS Glacier API to upload data.
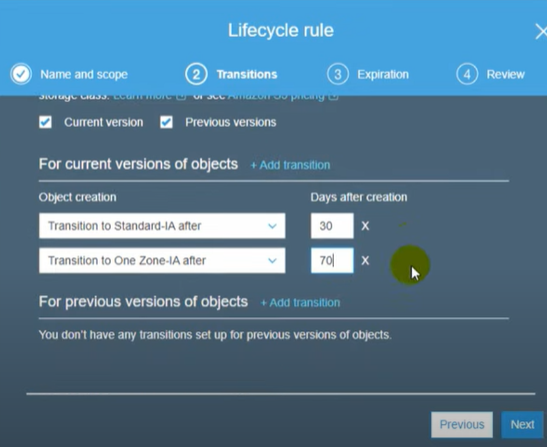
- S3 Lifecycle policies: S3 lifecycle policies can be set to upload S3 objects to AWS Glacier after some time. This can be used to backup old and infrequently access data stored in S3.
2. Data Transfer between regions:
AWS Glacier is a region-specific service. Data in one region can be transferred to another from the AWS console. This cost of suck a data transfer is $0.02.
3. Data Retrieval
As mentioned before, AWS Glacier is a backup and data archive service, given its low cost of storage, AWS Glacier data is not readily available for consumption.
- Data retrieval from Glacier can only be done via some sort of code, using AWS Glacier SDK or the Glacier API.
- Data Retrieval in AWS Glacier is of three types:
- Expedited:
- This mode of data retrieval is only suggested for urgent requirements of data.
- A single expedited retrieval request can only be used to retrieve 250MB of data at max.
- This data is then provided to you within 1-5 minutes.
- The cost of expedited retrieval is $0.03 per GB and 0.01 per request.
- Standard:
- This data retrieval mode can be used for any size of data, full or partial archive.
- This data is then provided to you within 3-5 hours.
- The cost of standard retrieval is $0.01 per GB and $0.05 per 1000 requests.
- Bulk:
- This data retrieval is suggested for mass retrieval of data (petabytes of data).
- It is the cheapest data retrieval option offered by AWS Glacier
- This data is then provided to you within 5-12 hours.
- The cost of bulk retrieval is 0.0025 per GB and 0.025 per 1000 requests
- Expedited: