When creating a small Python script, the question that eventually comes up is where the code will be hosted and run. For some small scripts, you might be able just to run the code locally. But, what if you want the code to be run on a regular schedule, even when your laptop is off? Or, what if you want the script to be part of an endpoint that other scripts can access?
One option would be to set up a server and running the code there. You could spin up a droplet on Digital Ocean, set up the Python environment, and run your scripts there. But, what if, you do not want to have to set up and manage servers?
This is where serverless functions can help! Serverless functions are scripts that you can set up without needing to manage the underlying infrastructure. Additionally, these systems auto-scale so you can easily run the function a few times a year or thousands of times per day without you needing to figure out how to scale.
AWS's Lambda is a great serverless function system that tightly integrates with the rest of the AWS ecosystem. AWS Lambda allows you to create serverless functions in various environments, including Python, NodeJS, and Go. Even better, the AWS free tier includes 1 million Lambda requests per month!
Writing Your First Python Lambda Function
For the most part, Python code within AWS Lambda is almost the same as writing normal Python scripts. However, within Lambda, you will need to specify a handler function which is then called by the environment. In most of my Lambda functions, I call this something similar to handler or lambda_handler. This looks like this:
For the handler function, we have two parameters: event and context.
The "event" parameter is an object that contains data that was passed to the Lambda function. For example, if the Lambda was attached to an endpoint, then we could access the data sent to the endpoint with something like event['body'].
The "context" parameter is an object that contains data about the Lambda function itself and its runtime environment.
Let's go ahead and write a very basic Lambda function that will accept a value and then return its square root.
Creating Your Lambda Function
To get started, you will need to sign in to your AWS account.
Once in your AWS console, you can either click on "Services" to go to "Compute"->"Lambda" or use their search bar to search for Lambda.
Once inside Lambda, you will find your Lambda dashboard as shown here:
Click on the "Functions" page from within the menu to get to your functions.

Next, click on the "Create function" button in the top right.
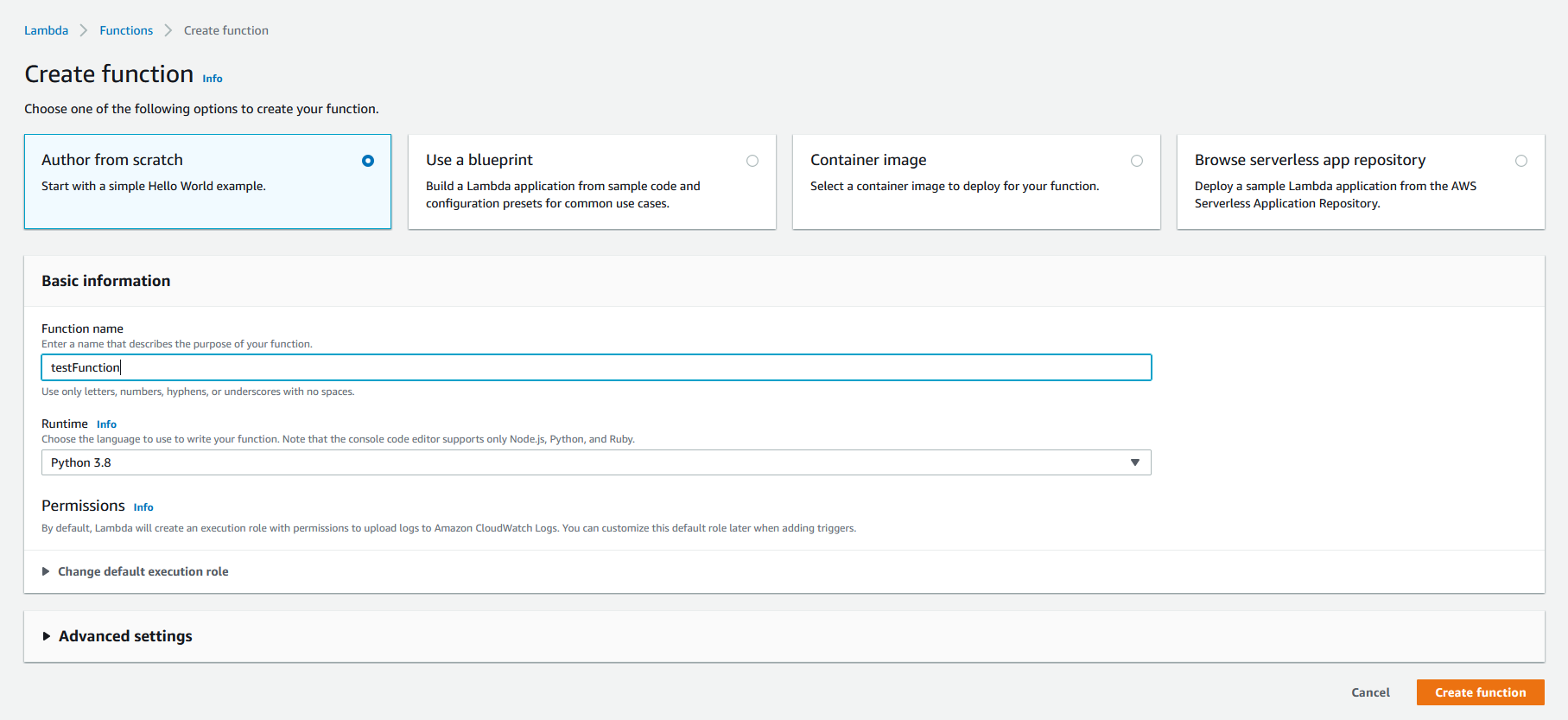
Use the "Author from scratch" option. Name your function anything you want. For the runtime, select a version of Python.
If this function were interacting with other parts of the AWS ecosystem, we'd want to set up permissions or an AWS role. But, for this example, we can keep the defaults.
Next, click the final "Create function" button.
Once created, you will be taken to the function's overview and code. Here you can review any triggers or layers attached to the function. For this one, we will not be using these.
Scroll down to the code section and open the default lambda_function.py file. Copy and paste our basic Python code from above into the file. Then, click the "Deploy" button.
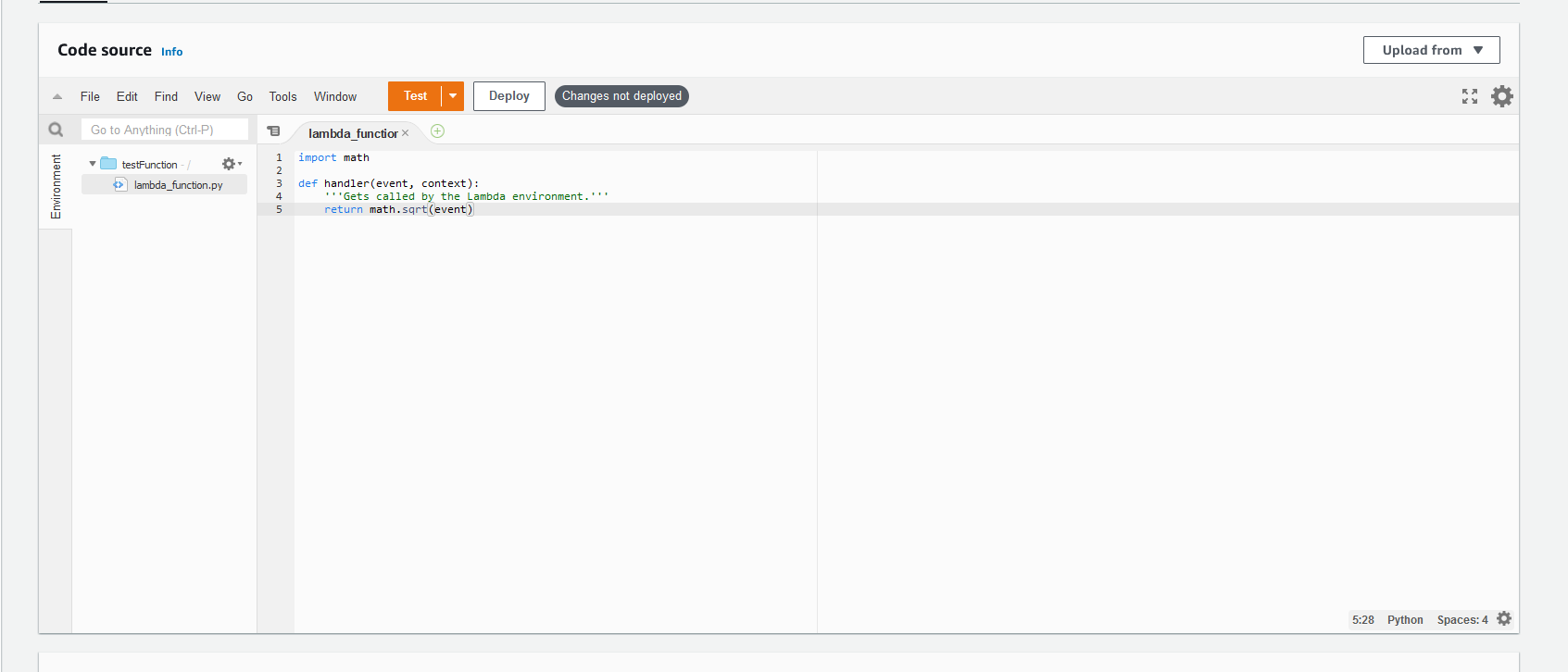
Next, scroll down to the "Runtime settings" section.

We want to edit the "Handler" field. This is how Python will try to import your function. So, it should be the file name followed by the function name. In this case, it should be updated to lambda_function.handler because we kept the default file but used our function called handler.
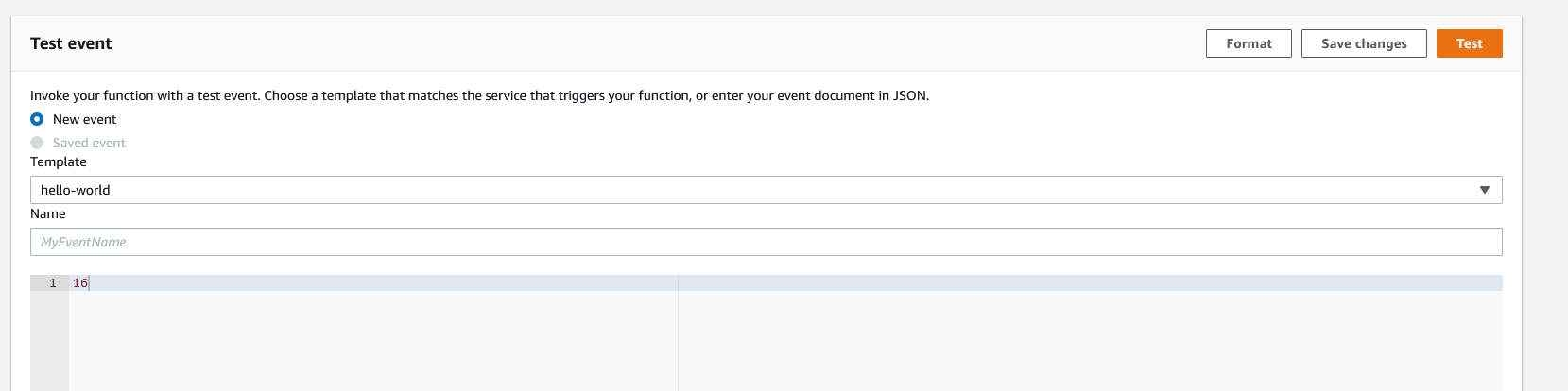
Now, scroll back up to the top and switch to the "Test" tab. Replace the example JSON with any number, such as 16. Next, click the "Test" button.
A box will appear with the execution results, which will include the square root value. This area will also display some information about the request, such as duration time.
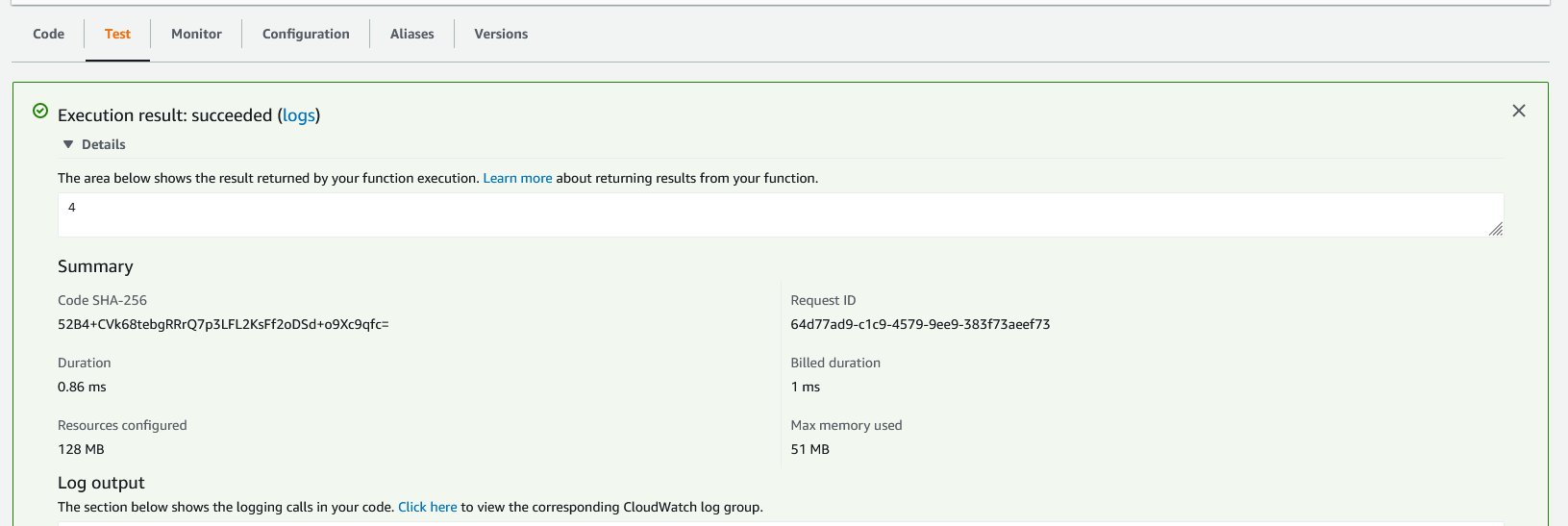
Congratulations! Your very first Lambda function has been created.
Next Steps
While it's useful to explore how the function works, you probably want to do a lot more with your Lambda function. In the next article in this series, I'll look at setting up a Lambda function on a recurring schedule. In future articles, I'll look at safely passing credentials to it and add other Python libraries to it.
Be sure to subscribe below to get notified when the next article is published!