The AWS S3 – Cross-region replication (CRR) allows you to replicate or copy your data in two different regions. But why do you need to set up CRR? There are many possible scenarios where setting up cross-region replication will prove helpful. Some of them are enlisted below:
- Improving latency and enhancing availability: If you are running a big organization with customers all around the world then making objects available to them with low latency is of great importance. By setting up cross-region replication you can enable your customers to get objects from S3 buckets which are nearest to their geographic location.
- Disaster recovery: Having your data in more than one region will help you prepare and handle data loss due to some unprecedented circumstances.
- To meet compliance requirements: Sometimes just to meet compliance requirements you will need to have a copy of your data in more than one region and cross-region replication can help you achieve that.
- Owner override: With AWS S3 object replication in place you can maintain the same copy of data under different ownership. You can change the ownership to the owner of the AWS destination bucket even if the source bucket is owned by someone else.
Setting up CRR:
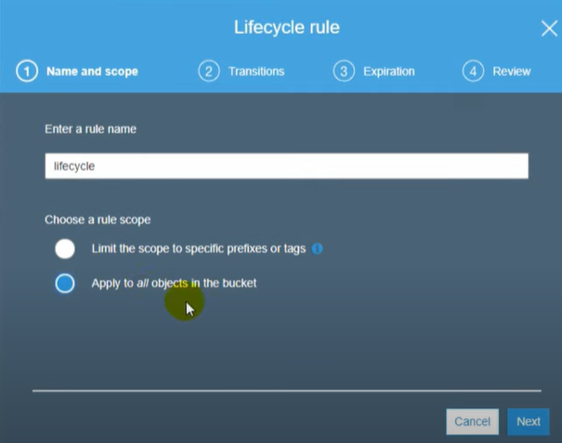
Follow the below steps to set up the CRR:
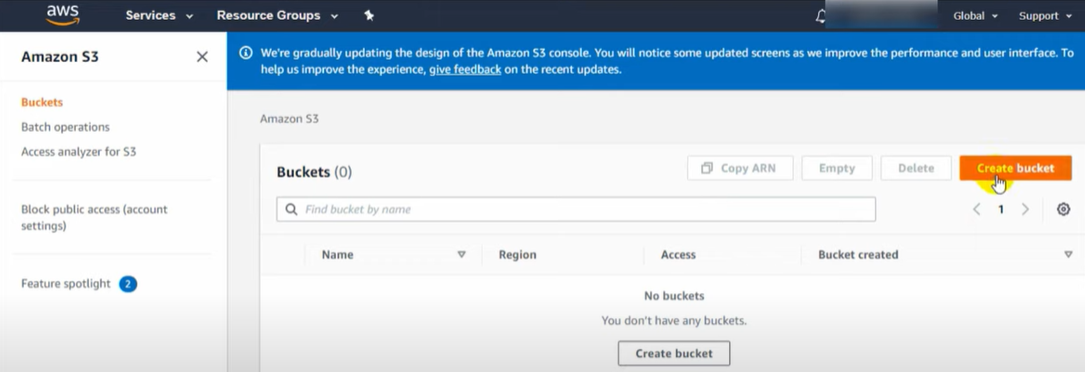
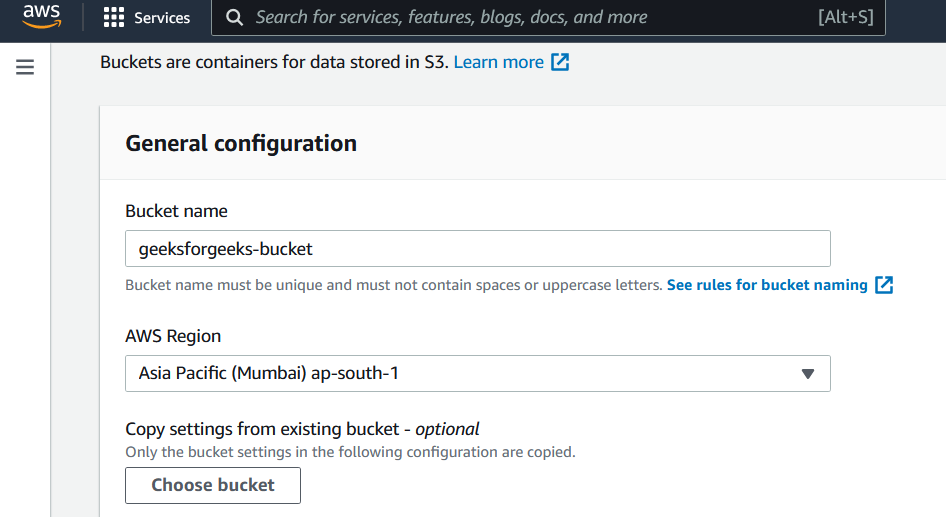
- Go to the AWS s3 console and create two buckets.
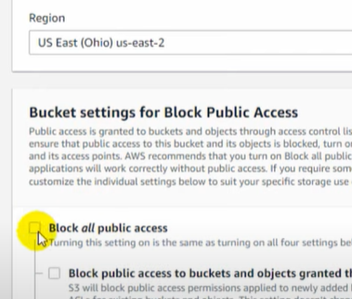
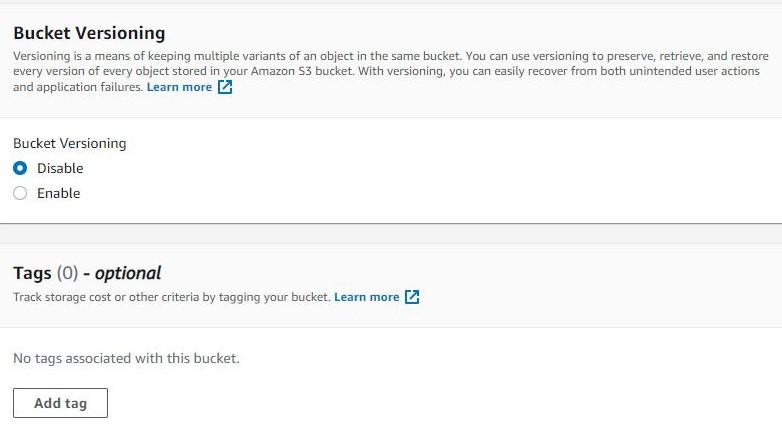
- Let’s name our source bucket as source190 and keep it in the Asia Pacific (Mumbai) ap-south 1 region. Do not forget to enable versioning. Also, note that the S3 bucket name needs to be globally unique and hence try adding random numbers after bucket name.

Source bucket: source190
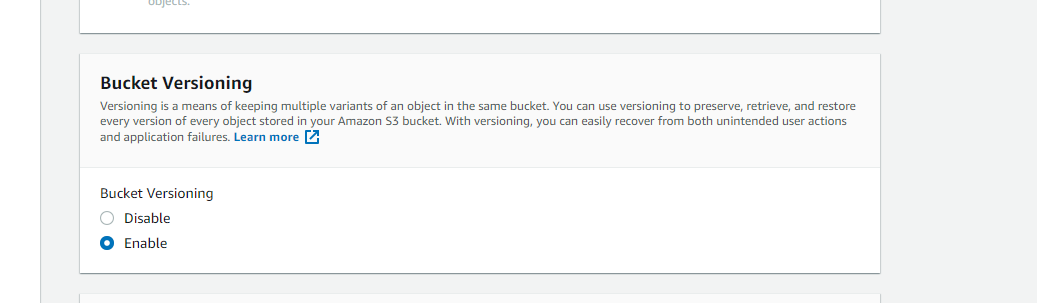
- Now following the same steps create a destination bucket: destination190 with versioning enabled but choose a different region this time.
- Now click on your source bucket and head over to the management tab:
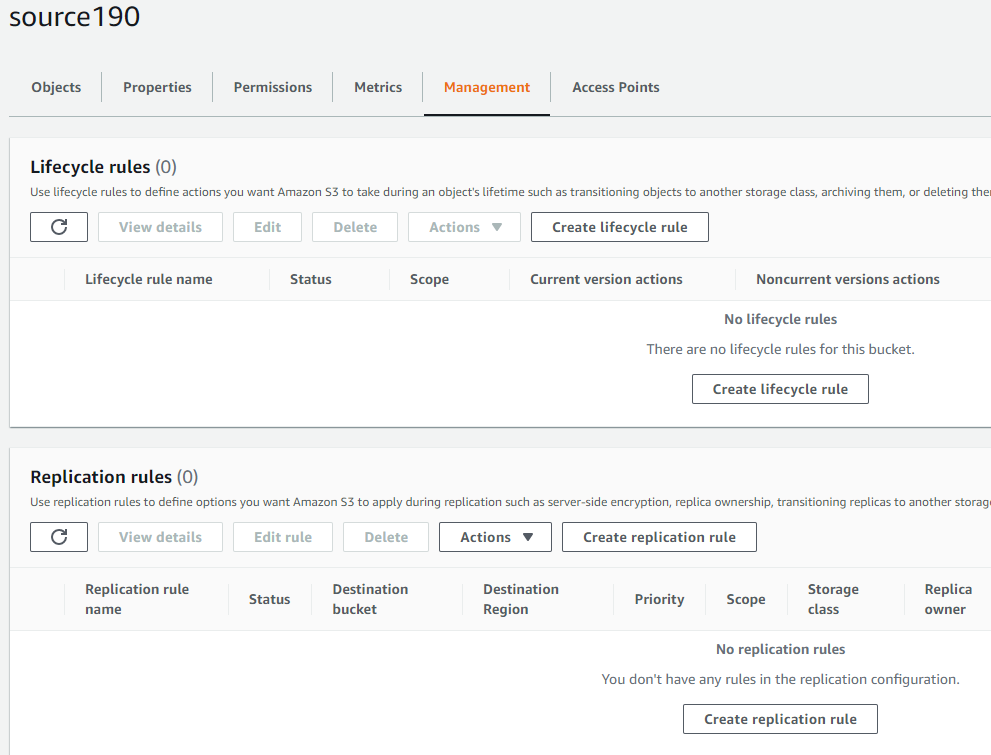
- Now, click on “Create a replication rule” and give your replication rule a name as “ replicate190”
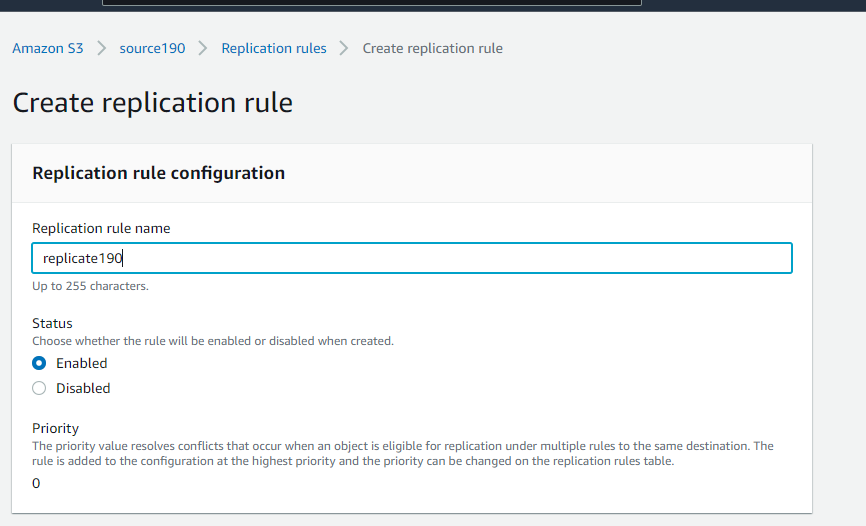
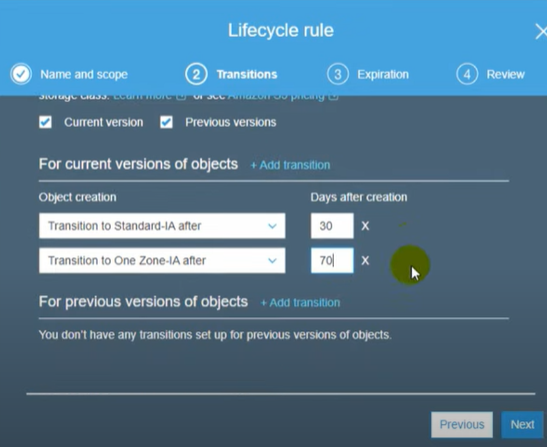
- Choose the destination bucket as “destination190”.

Set destination bucket
Notice that you have an option to choose a destination bucket in another account.
- In order to replicate objects from the source bucket to the destination bucket, you need to create an IAM role. So just create one by clicking on “create a new role”.

Create IAM role
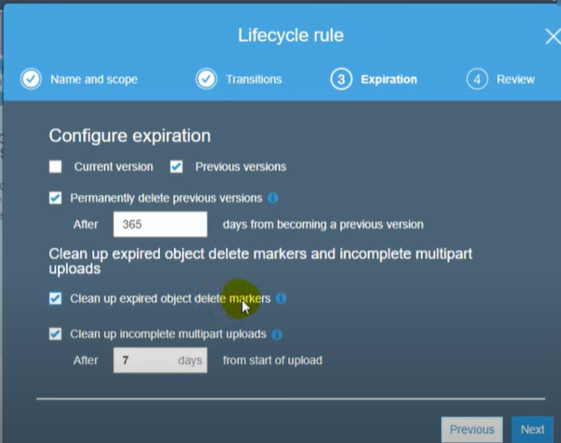
- If you want your S3 objects to be replicated within 15 minutes you need to check the “Replication Time Control (RTC) box. But you will be charged for this. So we will move forward without enabling that for now and click on save.
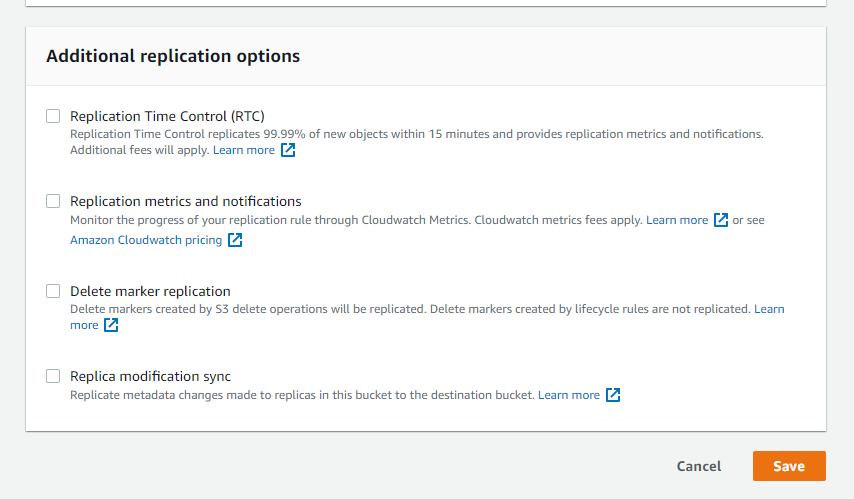
As soon as you click on save, a screen will pop up asking if you want to replicate existing objects in the S3 bucket. But that will incur charges so we will proceed without replicating existing objects and click on submit.
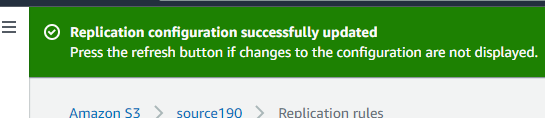
- After completing this setup you can see a screen saying “Replication configuration successfully updated”.
It’s time to test! Now go to the source bucket: source190 and upload a file.
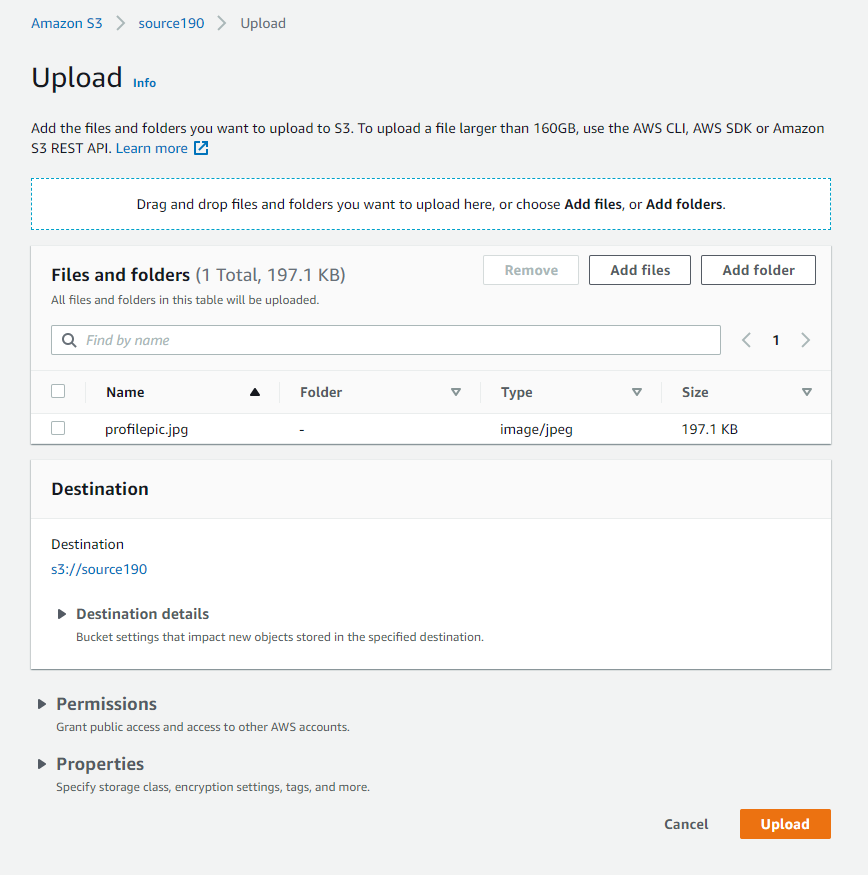
Now head over to our destination bucket: destination190 to check if the uploaded file is replicated to our destination bucket. You can see that our uploaded file is successfully copied to the destination bucket:
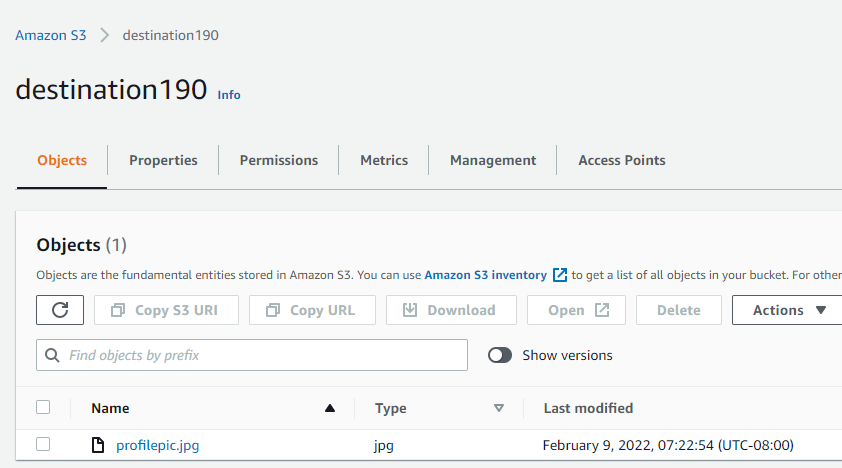
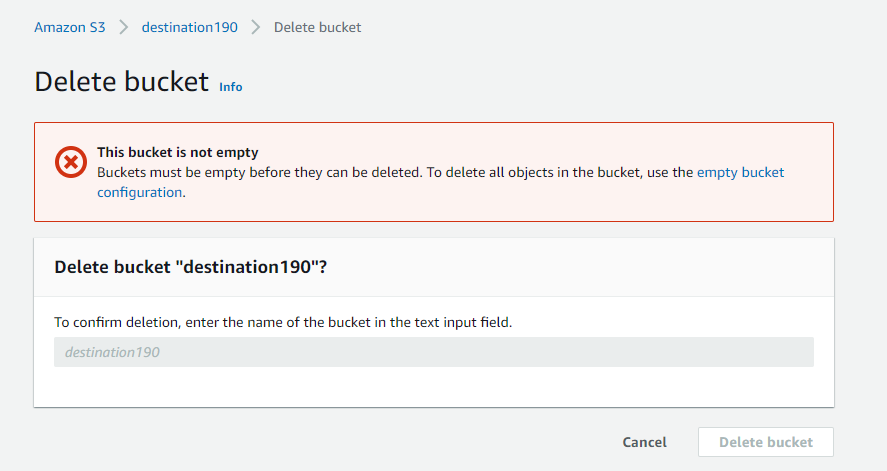
Note: Do not forget to empty your buckets and then delete them, if you do not have any further use. Also, you cannot delete a bucket if it is not empty.
Some important points about CRR:
For cross-region replication you must have:
- Source bucket and destination bucket in different regions (for the same region you can use the same region replication or SRR).
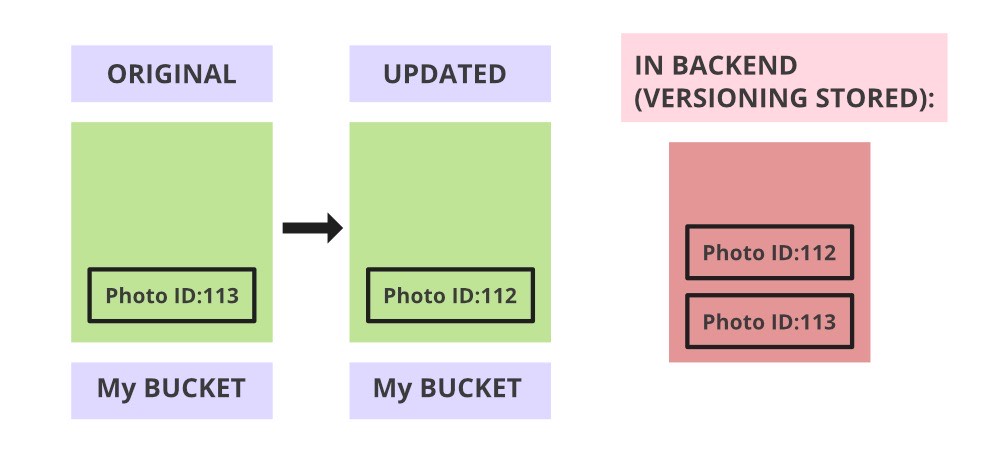
- Versioning is enabled in both the source as well as destination bucket.
When objects are replicated to a different region then:
- Object metadata, Access control list (ACL), and object tags are also replicated.
- The objects which were already present in the source bucket before setting up replication will not be replicated or copied to the destination bucket by default but you can perform a one-time batch operations job but that will incur additional charges.
- If your source bucket is acting as a destination bucket for another bucket or there are objects replicated in the source bucket from another bucket, then those objects will not be replicated to the destination bucket.
You can also enable bi-directional CRR by making the source bucket also the destination bucket for the destination bucket and vice versa.
Lastly, it is not necessary to have a destination bucket in the same account. AWS Cross-Region Replication can also be implemented in cross accounts ( given that the owner of the source bucket have the permission to copy data in the destination bucket)