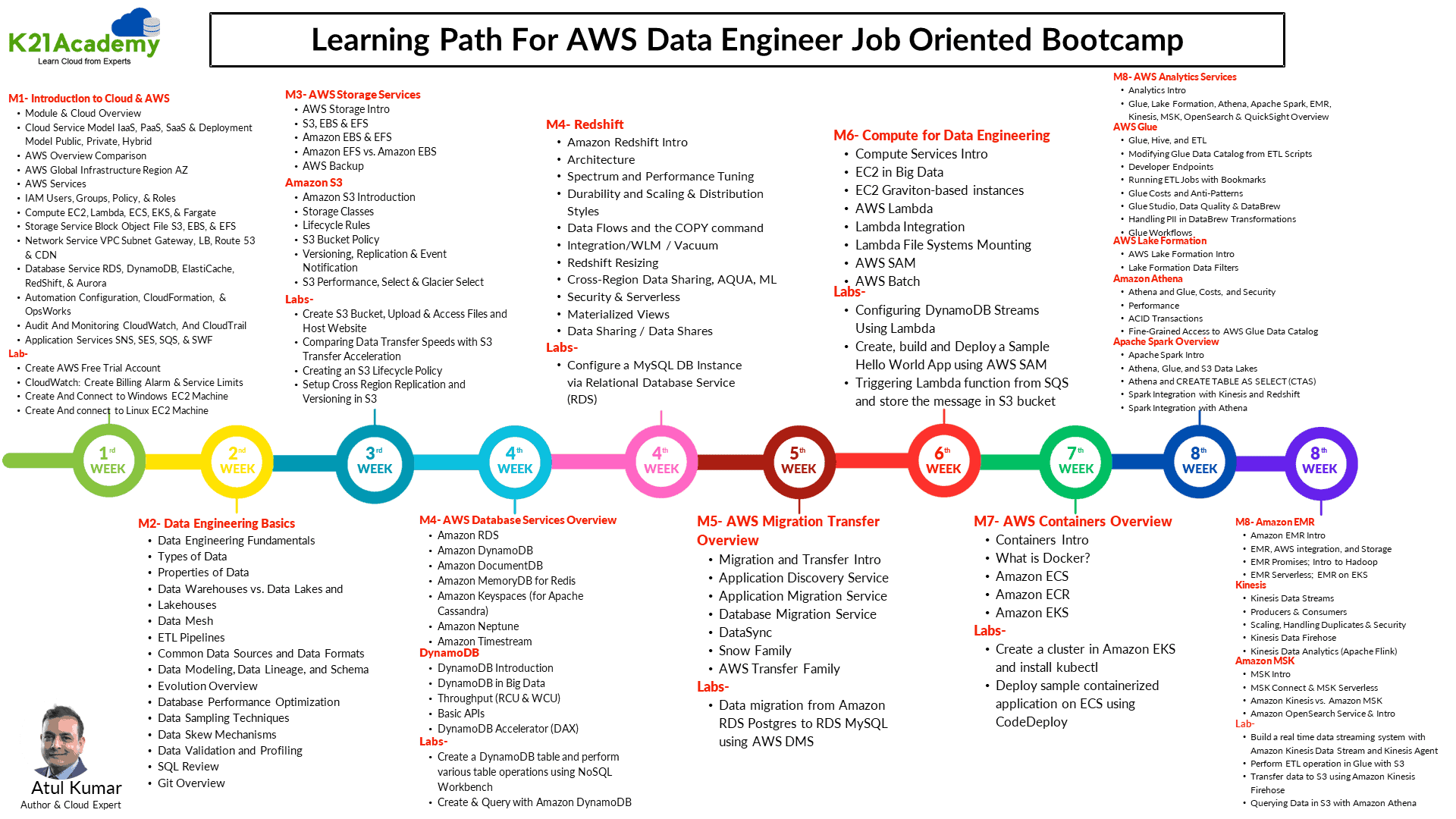
Hands-On Labs & Projects for Jobs & Certification Bootcamp
In this era, there will be a lot of competition for AWS data engineering jobs due to new developments like automated data analysis, the integration of AI, and the merging of software and data teams. Strong abilities in SQL, Python, AWS services, and data engineering principles are necessary for AWS data engineers. The Data Engineering concepts greatly improve employment possibilities by providing advantages like more job options and higher compensation. Although salaries vary depending on experience and region, this sector is well regarded for paying well.
Following the step-by-step activity guides in this blog will thoroughly prepare you for the AWS DATA Jobs and help you with the skills needed for AWS Data Engineering job roles and certifications.
List of labs that are part of our Data Engineering on AWS Cloud Training Bootcamp:
1. Hands-On Labs For AWS Data Engineer
- Lab 1: Create an AWS Free Trial Account
- Lab 2: Set Service Limits and Billing Alarms with CloudWatch
- Lab 3: Create And Connect To Windows EC2 Machine
- Lab 4: Create And Connect To Linux EC2 Machine
1.2 Ingestion and Changeover of Data
- Lab 1: Create a live streaming data system using Kinesis Agent and Amazon Kinesis Data Stream.
- Lab 2: Setting Up Lambda for DynamoDB Stream Configuration
- Lab 3: Recognizing Stateful and Stateless Firewalls
- Lab 4: Using Amazon DMS, move data from RDS Postgres to RDS MySQL.
- Lab 5: Execute an ETL process in Glue using S3.
- Lab 6: Use Amazon Kinesis Firehose to move data to S3
- Lab 7: Install Kubectl and build a cluster in Amazon EKS.
- Lab 8: Install a sample containerized application using CodeDeploy on ECS.
- Lab 9: Using AWS Step Functions to Create a Workflow with Different States
- Lab 10: Adding SNS events for S3 buckets and creating and subscribing to SNS topics
- Lab 11: The lambda function is triggered by SQS, and the message is stored in an S3 bucket.
- Lab 12: Create, develop, and launch a Hello World example application with AWS SAM.
- Lab 1: Create a DynamoDB table and use the NoSQL Workbench to execute different table operations.
- Lab 2: Data Transfer Speed Comparison Using S3 Transfer Acceleration
- Lab 3: S3 Lifecycle Policy Creation
- Lab 4: Configure S3 for cross-region replication and versioning.
1.4 Data Support and Operations
- Lab 1: Using Amazon Step Functions to Create a Serverless Workflow
- Lab 2: Data S3 Querying Using Amazon Athena
- Lab 3: SNS and CloudWatch for Automating the Creation of EBS Snapshots
- Lab 4: Setting Up CloudWatch Logs for SQS using a Lambda Function Trigger
- Lab 5: Creating CloudWatch Dashboards and Alarms and Monitoring Resources with CloudWatch
1.5 Data Governance and Security
- Lab 1: How to Interpret and Set Up Layered Security in an AWS VPC
- Lab 2: Creating IAM Roles
- Lab 3: How to set up a VPC Endpoint service from beginning to end
- Lab 4: How to use AWS Lambda to extract secrets from AWS Secrets Manager
- Lab 5: Creating IAM Policies
- Lab 6: Using KMS for Encryption and Decryption
- Lab 7: Alerts from AWS Access Control using CloudWatch and CloudTrail
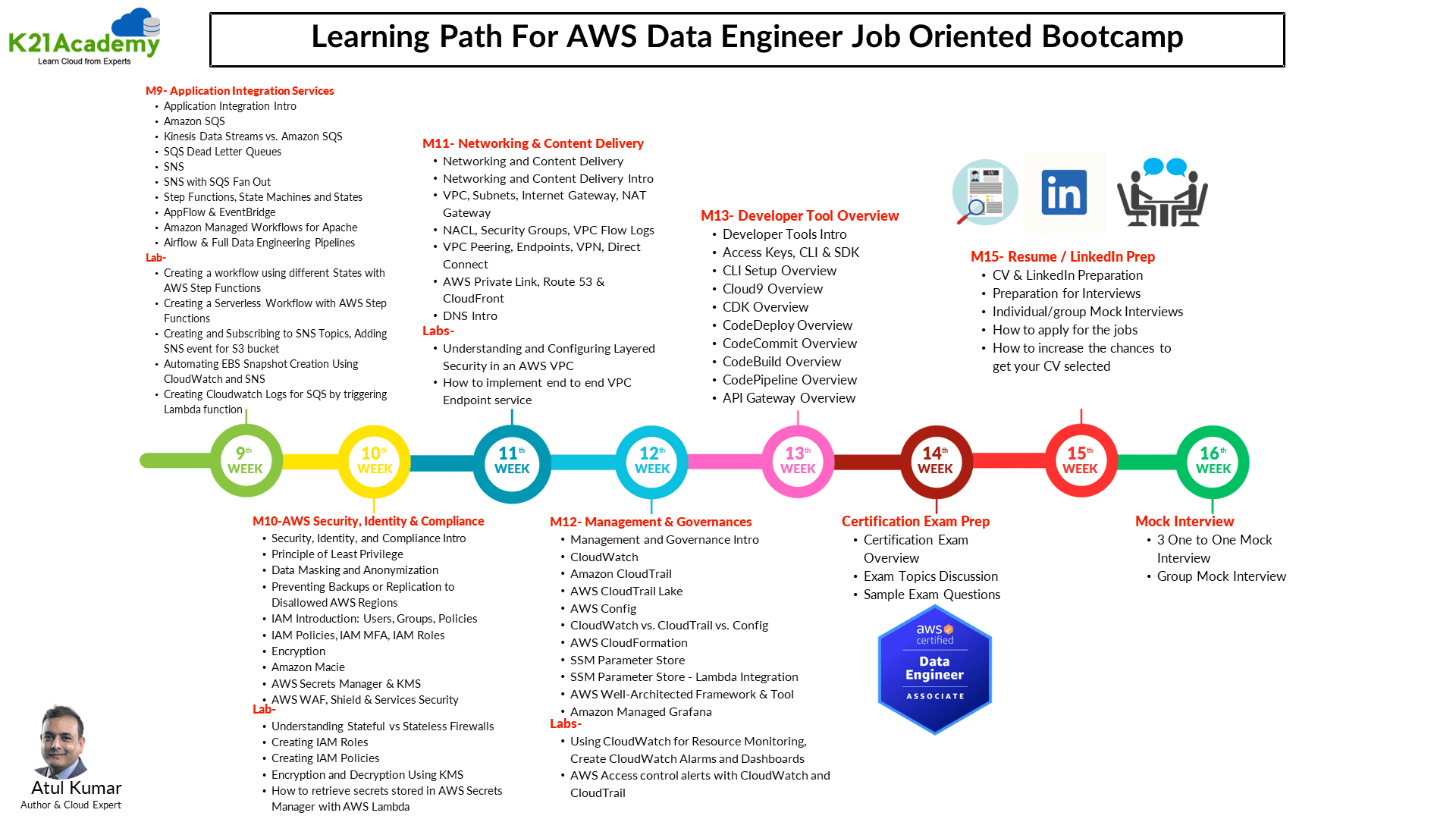
2. Real-time Projects for Experience
These projects help you get real-time hands-on and for Experience and you can add them to your resume.
- Project 1: Initial Data Handling and ETL Configuration with AWS Glue
- Project 2: Complex Data Processing and Enhanced Analysis Techniques with AWS Glue
- Project 3: Real-Time Data Analysis with ACID-Compliant Transactions in Amazon Athena
- Project 4: Setting Up and Executing Your First Amazon EMR Data Processing Workflow
- Project 5: Migrate from MySQL to Amazon RDS with AWS DMS
3. Conclusion
Let’s start with hands-on labs and project work in AWS Data Engineering to master scalable data solutions and optimize analytics pipelines for enhanced insights and decision-making.
Hands-On Labs For AWS Data Engineer
1.1 AWS Basic Labs
Lab 1: Create an AWS Free Trial Account
Create a free trial account to get started with AWS. This interactive lab walks you through the first steps of setting up an AWS account, which provides you with a wealth of cloud services to work with your experiments and development.
To get a hands-on feel for all its services, new customers can sign up for a free 12-month trial membership with Amazon Web Services (AWS). We can utilize many services from Amazon, albeit with certain restrictions, to gain practical experience and expand our understanding of AWS cloud services in addition to ordinary business use.
All of the services available with the AWS Free Tier account have a usage cap on how much we may use without incurring fees. We’ll examine how to sign up for an AWS FREE Tier Account in this section.
Check out our step-by-step blog post on How to build an Amazon Free Tier Account to learn how to build a free AWS account.

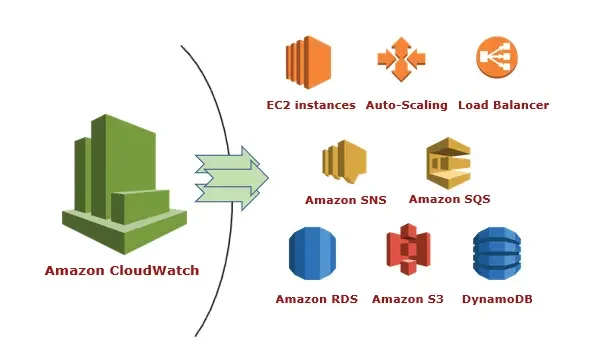
Lab 2: Set Service Limits and Billing Alarms with CloudWatch
Explore the monitoring service offered by AWS, CloudWatch. To successfully control costs, this lab focuses on setting up billing alarms and monitoring service restrictions to make sure your applications function properly within predetermined parameters.
Amazon CloudWatch can be used to enable AWS billing notifications. Your whole AWS account activity is tracked by the CloudWatch service from Amazon Web Services. AWS account usage activities can be detected via CloudWatch, which also offers an infrastructure for monitoring apps, logs, metrics collection, and other service metadata in addition to billing notifications.
You can configure your alarms using a variety of metrics provided by AWS CloudWatch. For instance, you can program an alarm to sound when the CPU or memory utilization of a running instance surpasses 90% or when the invoice amount surpasses $100. With an AWS free tier account, we receive 1,000 email notifications and 10 alarms every month.

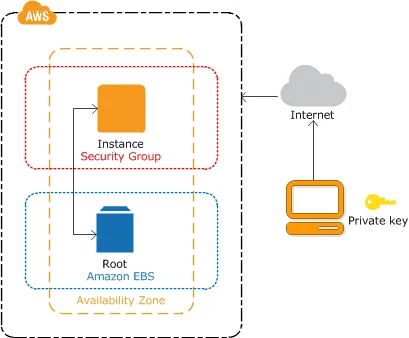
Lab 3: Create And Connect To Windows EC2 Machine
We have different methods for creating and connecting to the Windows EC2 machine for Windows users and Mac users:
- Windows Users: Sign in to the AWS Management Console, go to the EC2 dashboard, create a new instance with a Windows AMI, configure it, and connect via Remote Desktop Connection to the instance’s public IP or DNS name.
- Mac Users: Access the AWS Management Console, create a new Windows EC2 instance, customize the parameters, and get a remote desktop client like Microsoft Remote Desktop from the Mac App Store. Connect to the EC2 instance using the client’s public IP address or DNS name, as well as the username and password you’ve provided.
Launch a Windows instance to gain hands-on experience with Elastic Compute Cloud (EC2). Discover the subtleties of creating instances and establish a smooth connection to virtual computers running Windows.
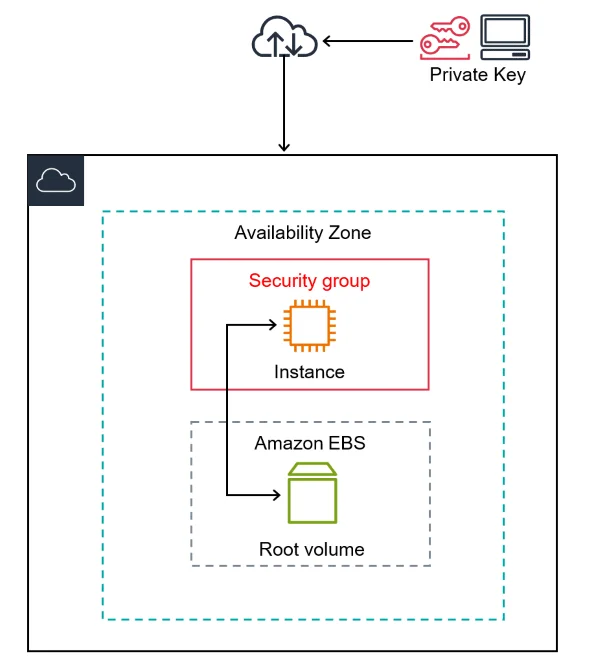
Lab 4: Create And Connect To Linux EC2 Machine
For Windows and Mac users:
To launch and connect to a Linux EC2 instance:
- Sign in to the AWS Console: Access the AWS Management Console and click on the EC2 dashboard.
- Launch Instance: Select a Linux AMI, select the instance settings, and start the instance.
Connect with SSH:
- Windows users should download an SSH client such as PuTTY and enter their public IP/DNS and username (“ec2-user” or “ubuntu”).
- Mac Users: To create a connection, open Terminal and run the SSH command using the public IP, DNS, and username.
By launching a Linux instance, you can expand your knowledge of EC2. Learn about AWS’s Linux environment, from creation to effective instance connection and management.
1.2 Ingestion and Transformation of Data
In this module, there are a total of 12 labs covered, which will guide you through the hands-on practice of ingestion and transformation of data in the AWS Data Engineering Course.
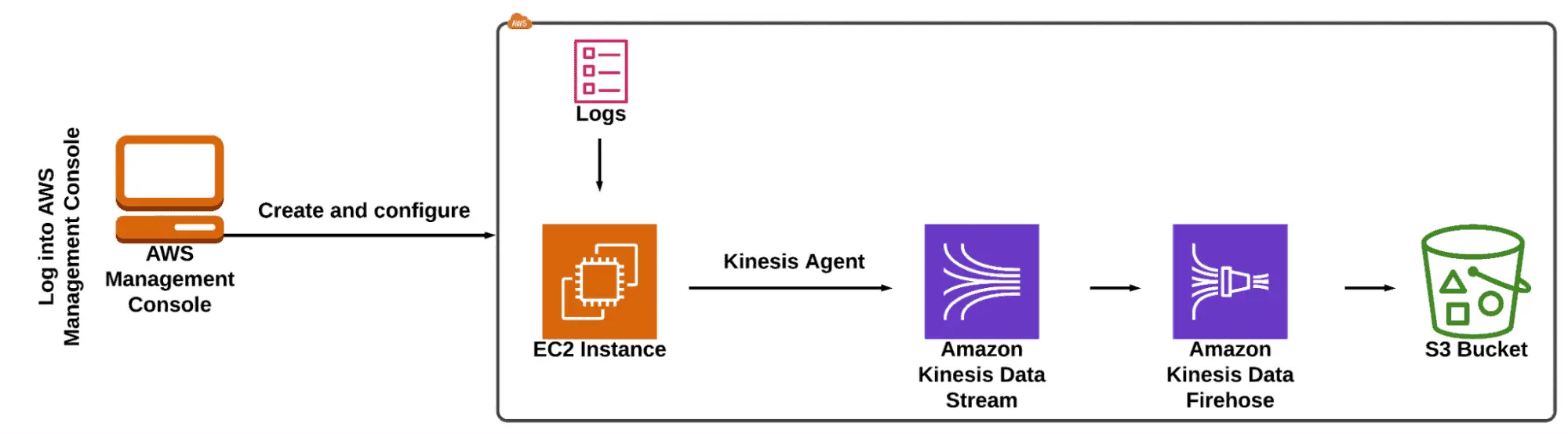
Lab 1: Create a live streaming data system using the Kinesis Agent and Amazon Kinesis Data Stream.
This lab walks you through setting up an example website on an EC2 Linux instance, using the Apache web server, and logging website traffic in real-time. Kinesis Data Streams, Kinesis Agent, Kinesis Firehose, and S3 are then used to stream these logs to AWS S3 for storage and analysis.
Data streaming technology allows customers to consume, process, and analyze large amounts of data from several sources. Kinesis data streams are one such scalable and long-lasting real-time streaming solution. A Kinesis data stream is an ordered sequence of data records that may be written to and read from in real-time.
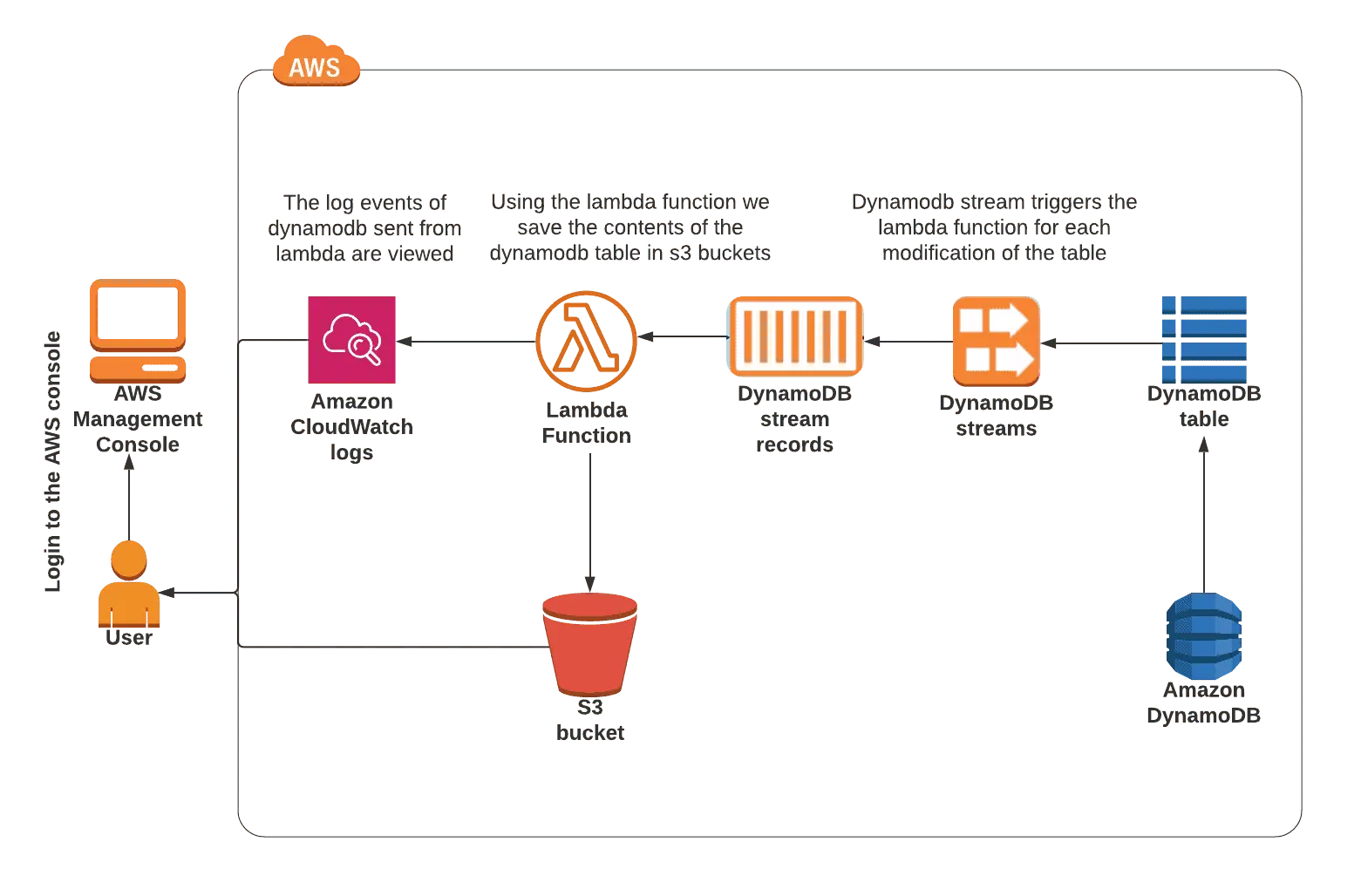
Lab 2: Setting Up Lambda for DynamoDB Stream Configuration
In this lab, you will learn how to create an Amazon DynamoDB table, set up DynamoDB streams, and start a Lambda function that will dump the table’s contents into a text file, which you can then move to an S3 bucket.
With Amazon DynamoDB, you may have a fully managed NoSQL database service. AWS handles all of the operations, maintenance, administrative overhead, and scaling.
S3, Lambda, and Amazon DynamoDB will be used in practice.
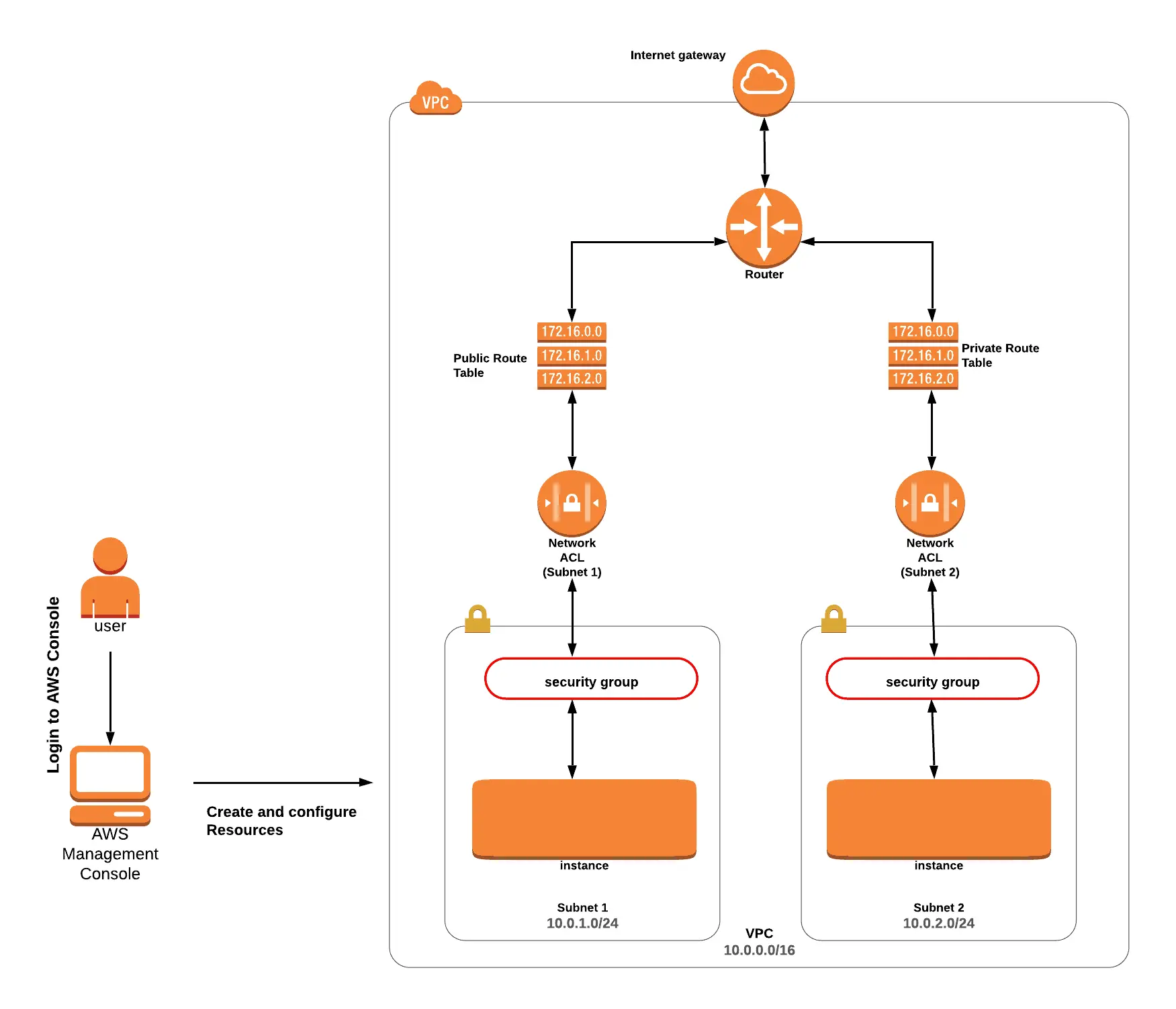
Lab 3: Recognizing Stateful and Stateless Firewalls
This lab explains the differences between stateless (Network ACL) and stateful (Security Group) firewalls.
Using EC2 and VPC, you will practice in the lab.
Lab 4: Using Amazon DMS, move data from RDS Postgres to RDS MySQL.
This experiment demonstrates how to use AWS DMS to move a database from RDS Postgres to RDS MySQL.
Relational databases can be operated on AWS using the fully managed solution known as Amazon RDS. Six different database engines are supported, including free and open-source alternatives like MariaDB, PostgreSQL, and MySQL.
Amazon Relational Database Service (Amazon RDS) is a relational database service that provides high availability and performance.
PostgreSQL is an object-relational database management system, whereas MySQL is a relational database management system.
The AWS Database Migration Service (AWS DMS) enables you to transfer databases to AWS quickly and securely.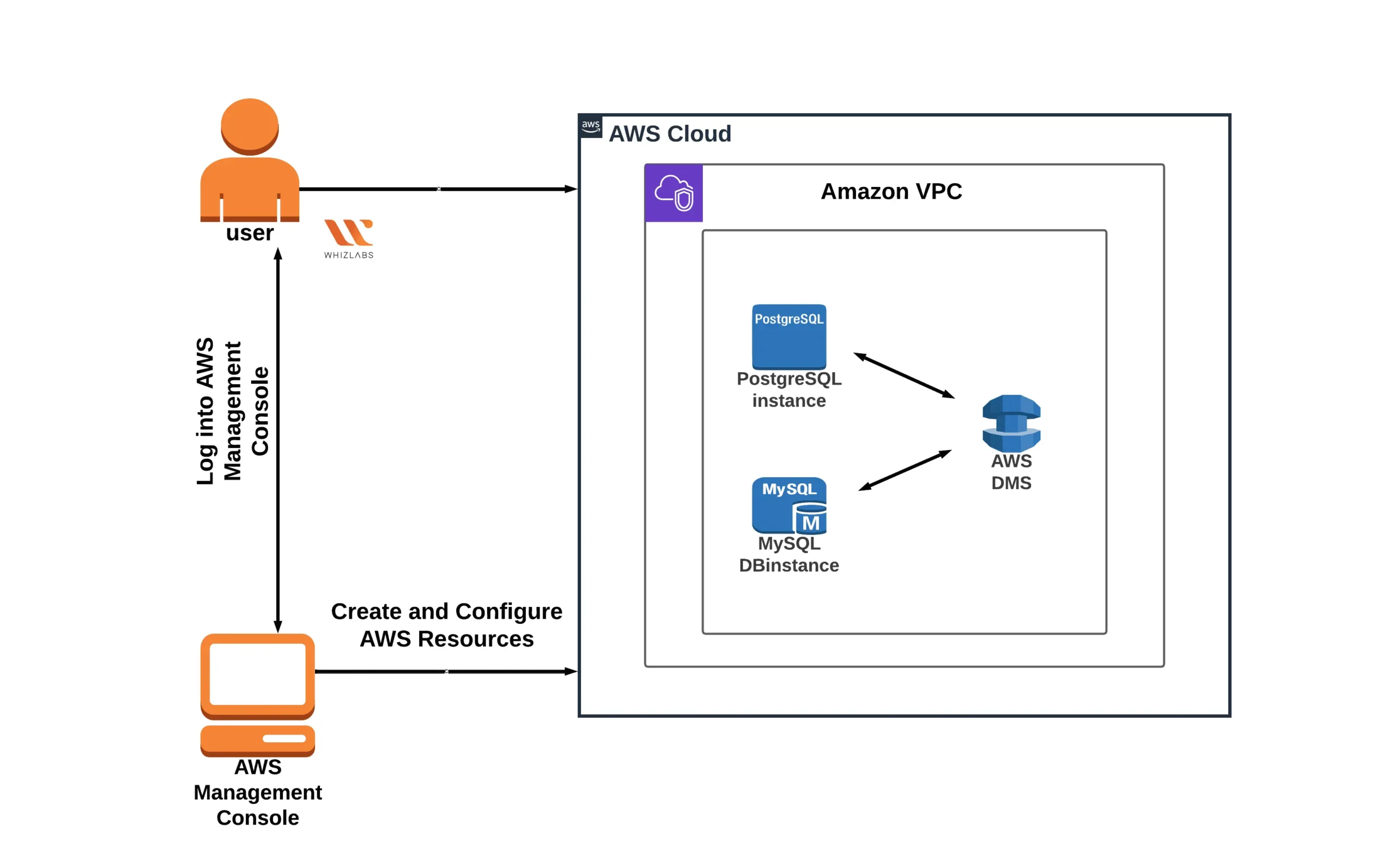
Lab 5: Execute an ETL process in Glue using S3.
This lab shows you how to use Amazon S3 as a data source and conduct ETL operations in AWS Glue.
You will practice creating a reference table in the Glue Data catalog’s databases using the AWS Glue crawler and executing aggregation on top of the tables using ETL jobs.
AWS Glue is a serverless data integration service that allows you to easily discover, prepare, move, and combine data from many sources for analytics, machine learning (ML), and application development. It is a completely managed service that handles provisioning, configuring, and managing the underlying infrastructure, allowing you to focus on your data.
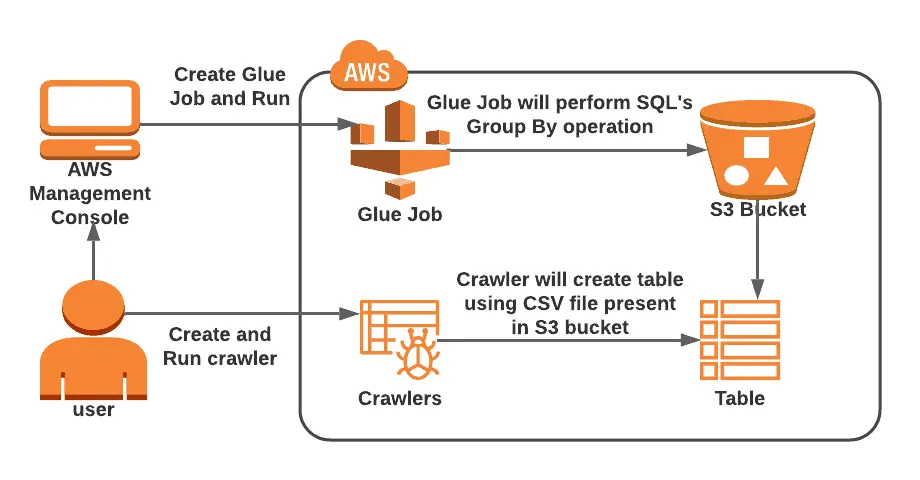 Lab 6: Use Amazon Kinesis Firehose to move data to S3
Lab 6: Use Amazon Kinesis Firehose to move data to S3
You will learn how to construct delivery streams for Amazon Kinesis Data Firehose in this lab.
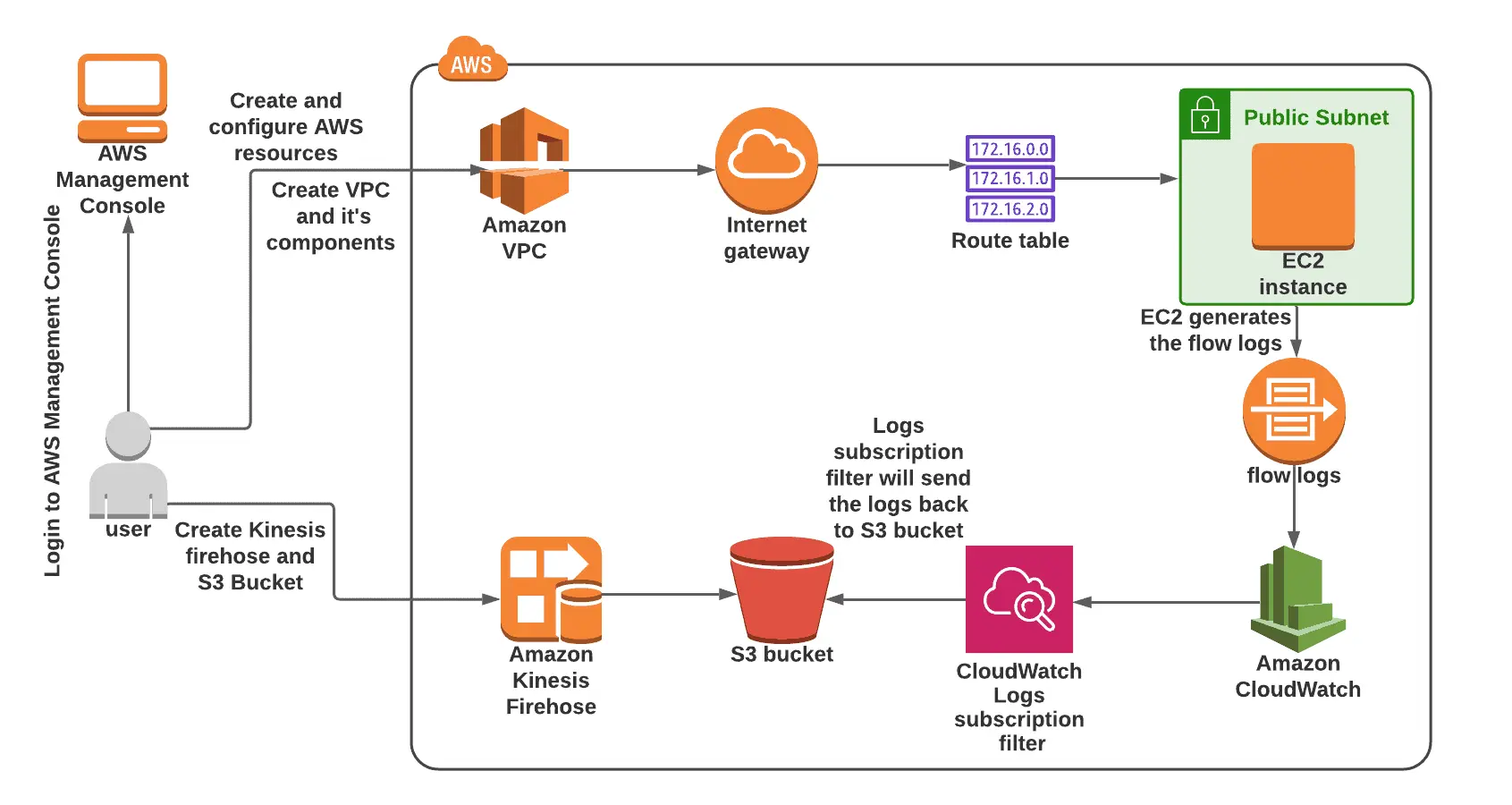
Using an EC2 instance-generated VPC flow and the Kinesis Firehose delivery stream, you will practice sending sample data to an Amazon S3 bucket.
Amazon Kinesis Data Firehose is a fully managed service that streams real-time data to Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon OpenSearch Service, Amazon OpenSearch Serverless, Splunk, and any custom HTTP endpoint.
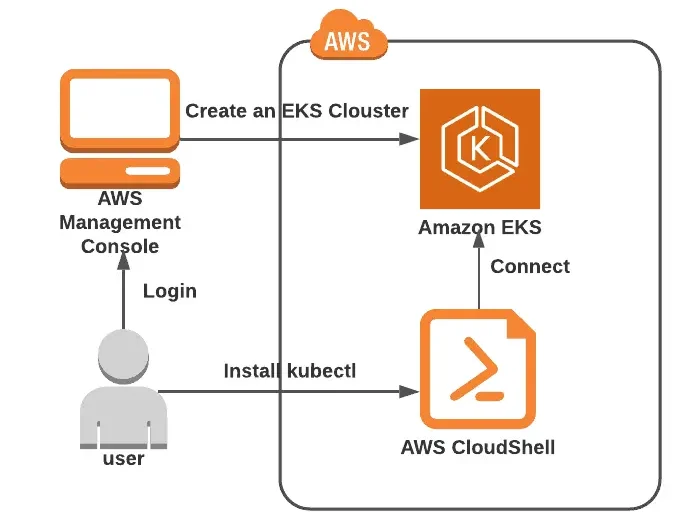
Lab 7: Install Kubectl and build a cluster in Amazon EKS.
This lab explains how to build an EKS cluster and helps you become familiar with all of its parts.
You will install Kubectl to obtain the cluster IP and practice utilizing the AWS Elastic Kubernetes Service cluster.
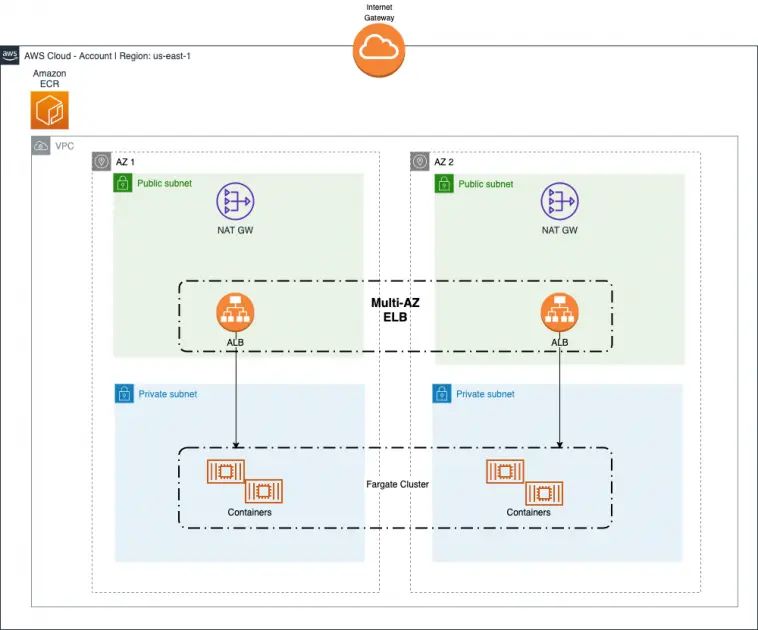
Lab 8: Install a sample containerized application using CodeDeploy on ECS.
To provide you with hands-on experience, this lab walks you through the process of deploying sample containerized apps on Amazon ECS using AWS CodeDeploy. You’ll gain a better grasp of containerized application deployment on AWS and become acquainted with the deployment methodology by following along.
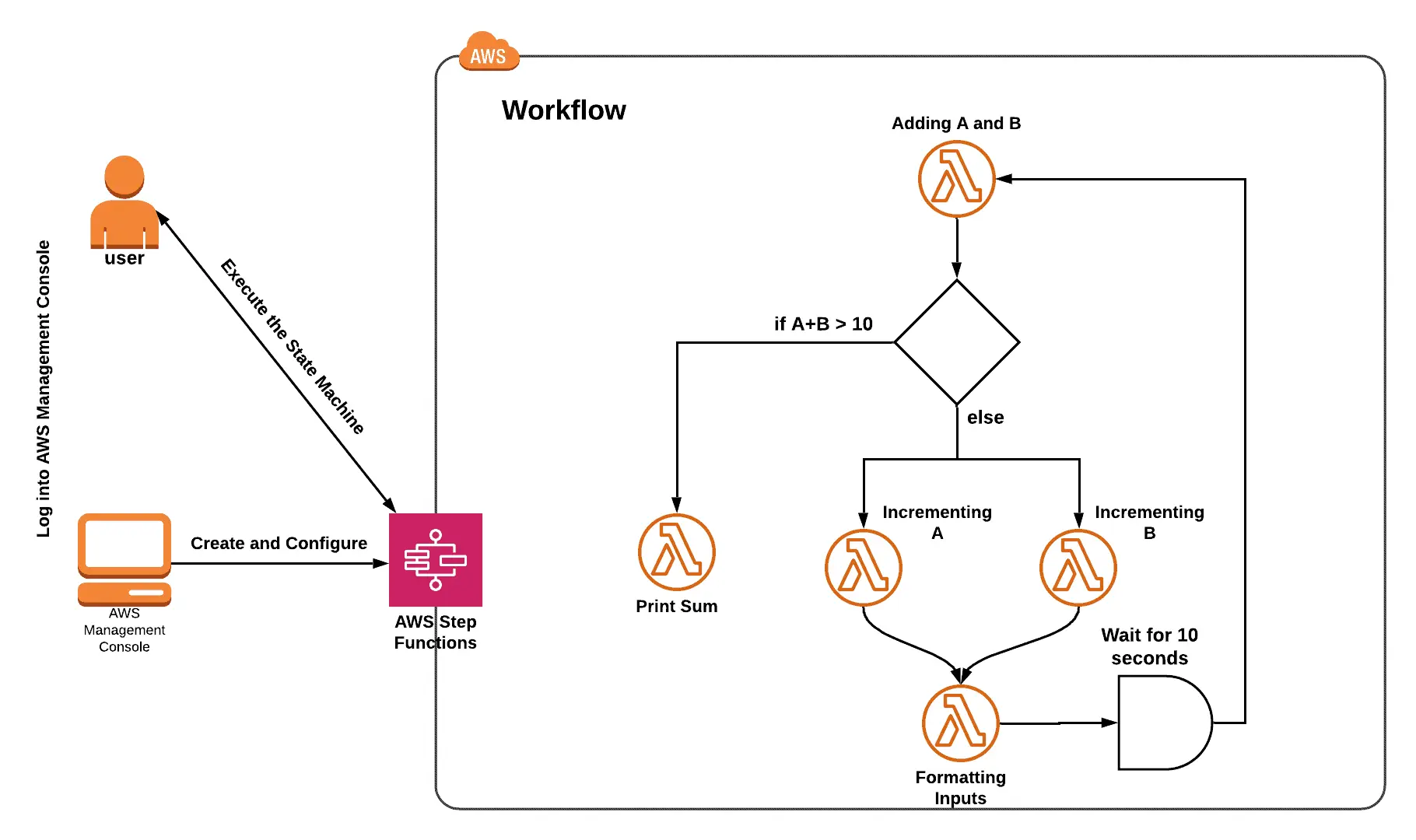
Lab 9: Using AWS Step Functions to Create a Workflow with Different States
You will learn how to create and execute a step function in this lab, along with how to interact with various workflow state types.
You’ll get some experience with AWS Step Functions.
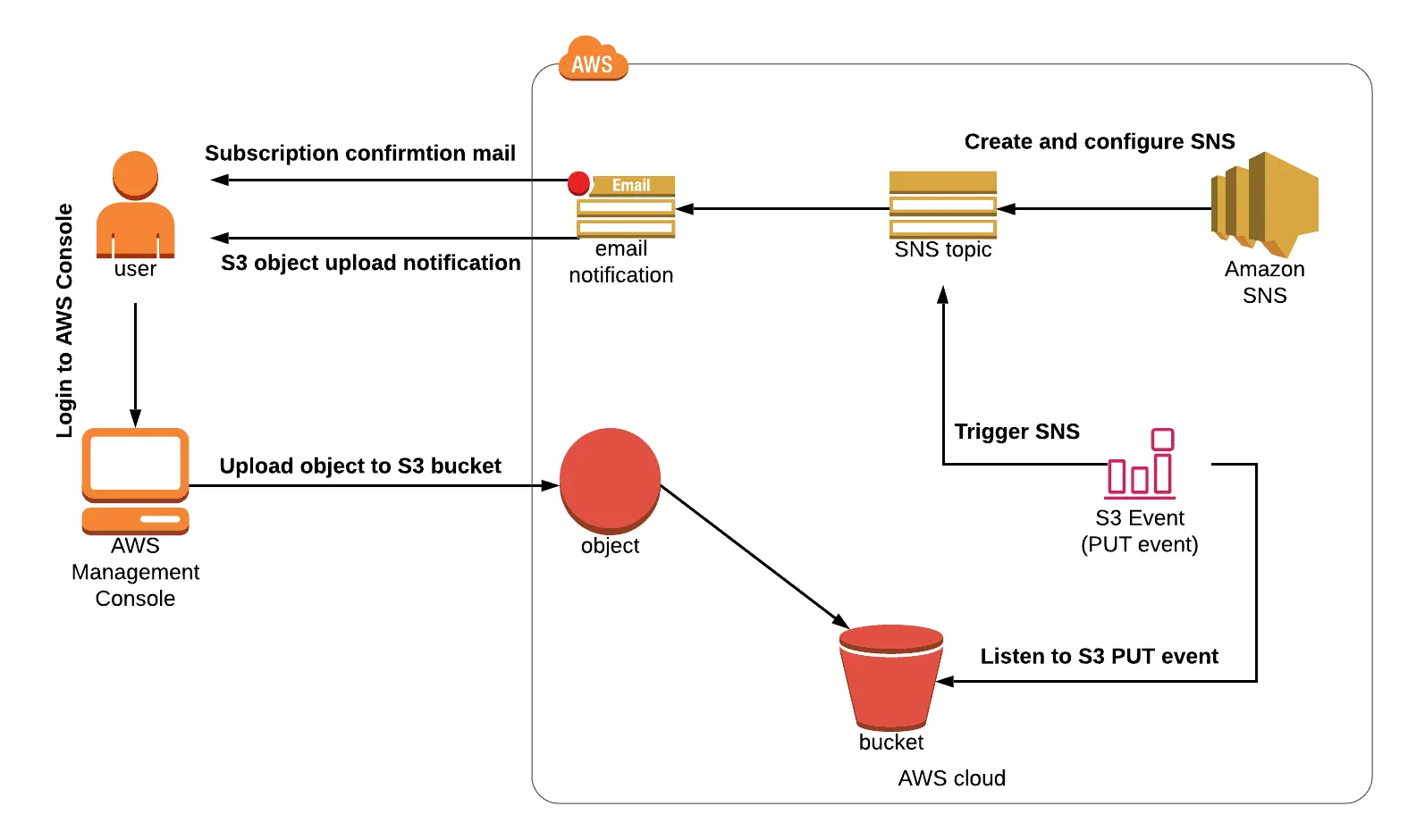
Lab 10: Adding SNS events for S3 buckets and creating and subscribing to SNS topics
You will learn how to create and subscribe to an Amazon SNS topic in this experiment.
Using Amazon Simple Notification Service (Amazon SNS) or Amazon Simple Queue Service (Amazon SQS), you can subscribe to receive notifications from Amazon S3.
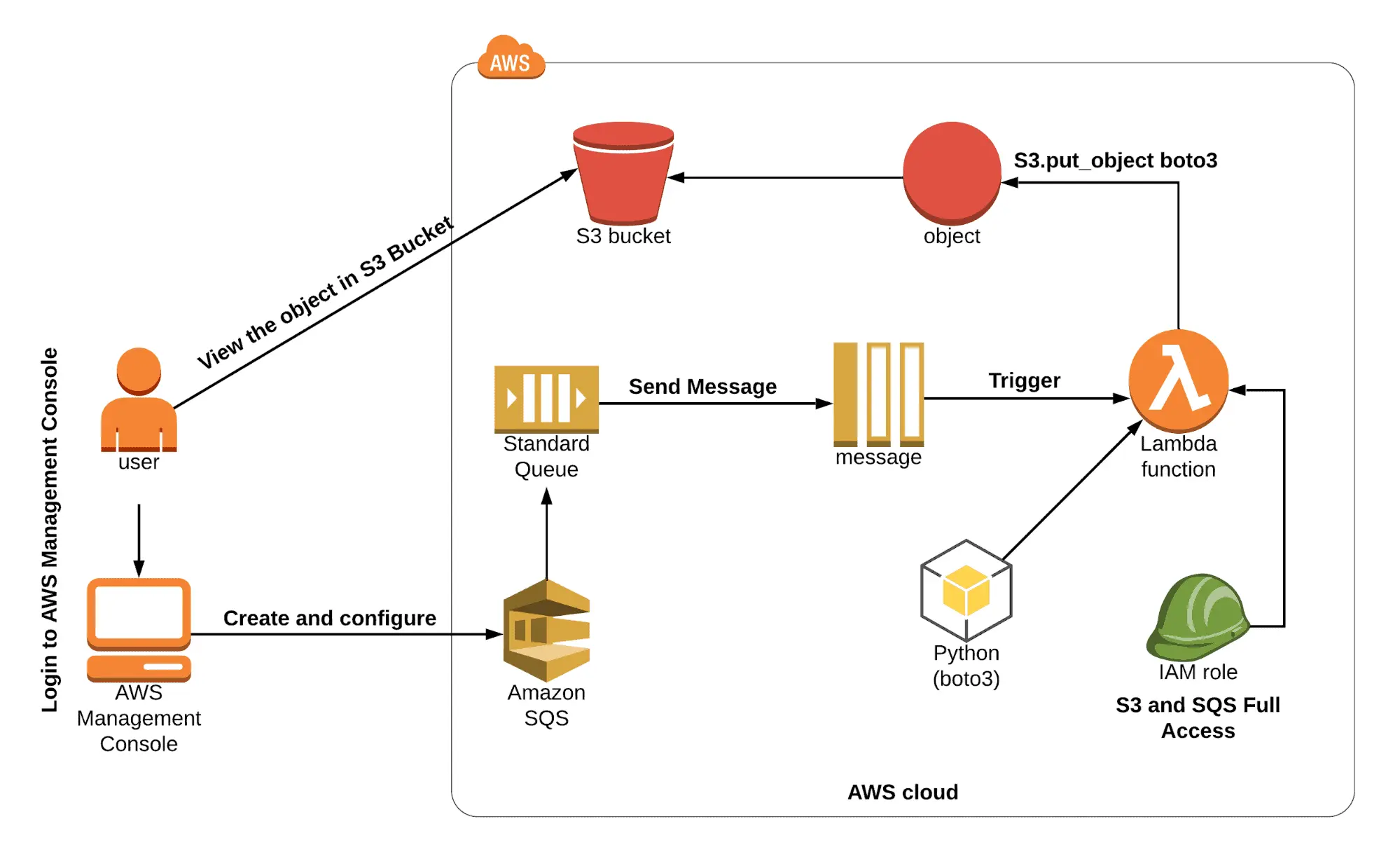
Lab 11: The lambda function is triggered by SQS, and the message is stored in an S3 bucket.
This lab demonstrates how to set up an SQS queue and send a message that will cause a lambda function to be called, storing the message in an S3 bucket.
AWS Lambda is a computational service that enables you to run code without having to provision or manage servers. Lambda runs your code on a high-availability compute infrastructure and manages all compute resources, including server and operating system maintenance, capacity provisioning, automatic scaling, and logging.
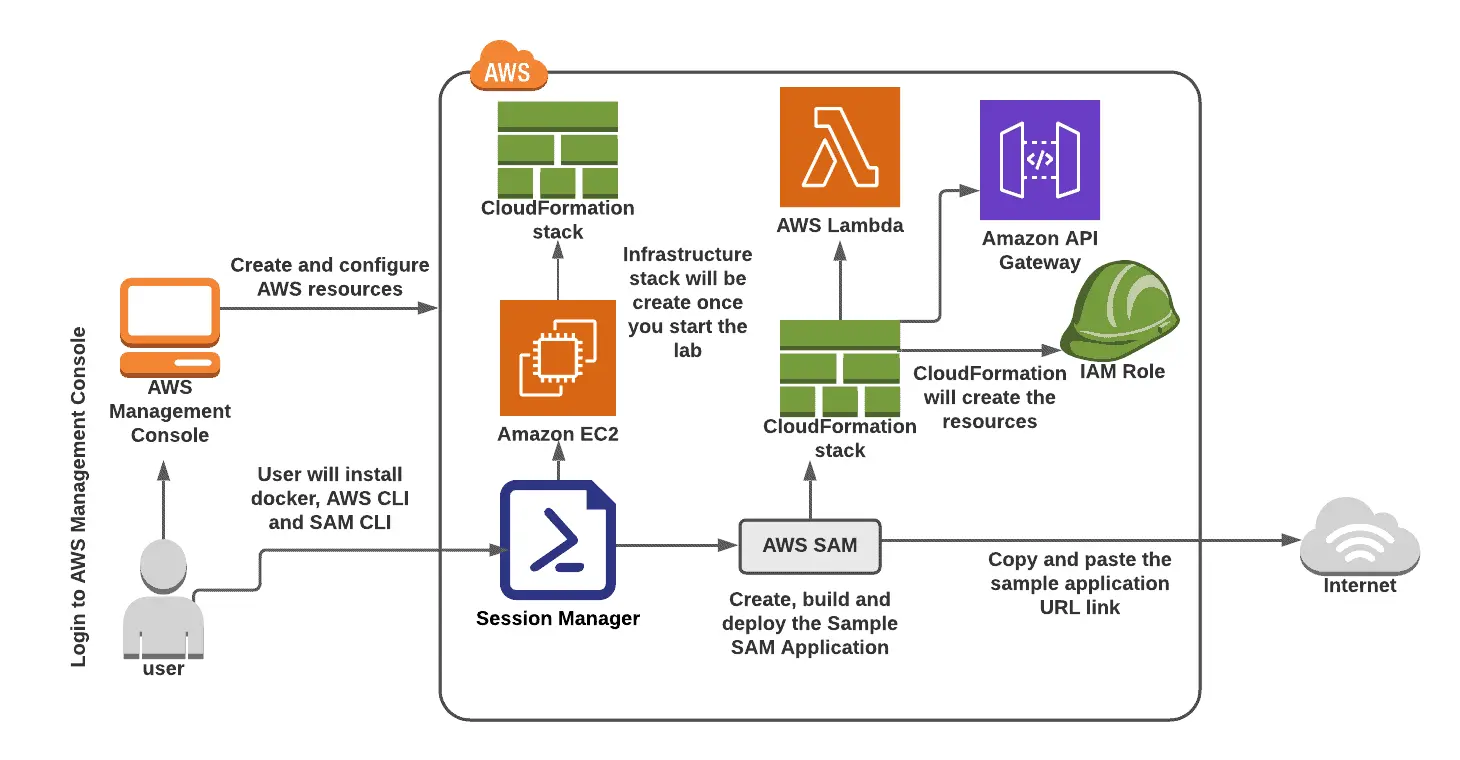
Lab 12: Create, develop, and launch a Hello World example application with AWS SAM.
You are guided through the process of creating, building, and deploying the sample node in this lab. The AWS Serverless Application Model (SAM) is used in the Hello World application written in JS.
AWS SAM consists of two components: AWS SAM templates and the AWS SAM Command Line Interface (AWS SAM CLI). AWS SAM templates offer a shorthand syntax for defining Infrastructure as Code (IaC) in serverless applications.
1.3 Management of Data Stores
There are a total of 4 labs in this module, which will guide you through hands-on practice in the management of data stores in the data engineering exam course.
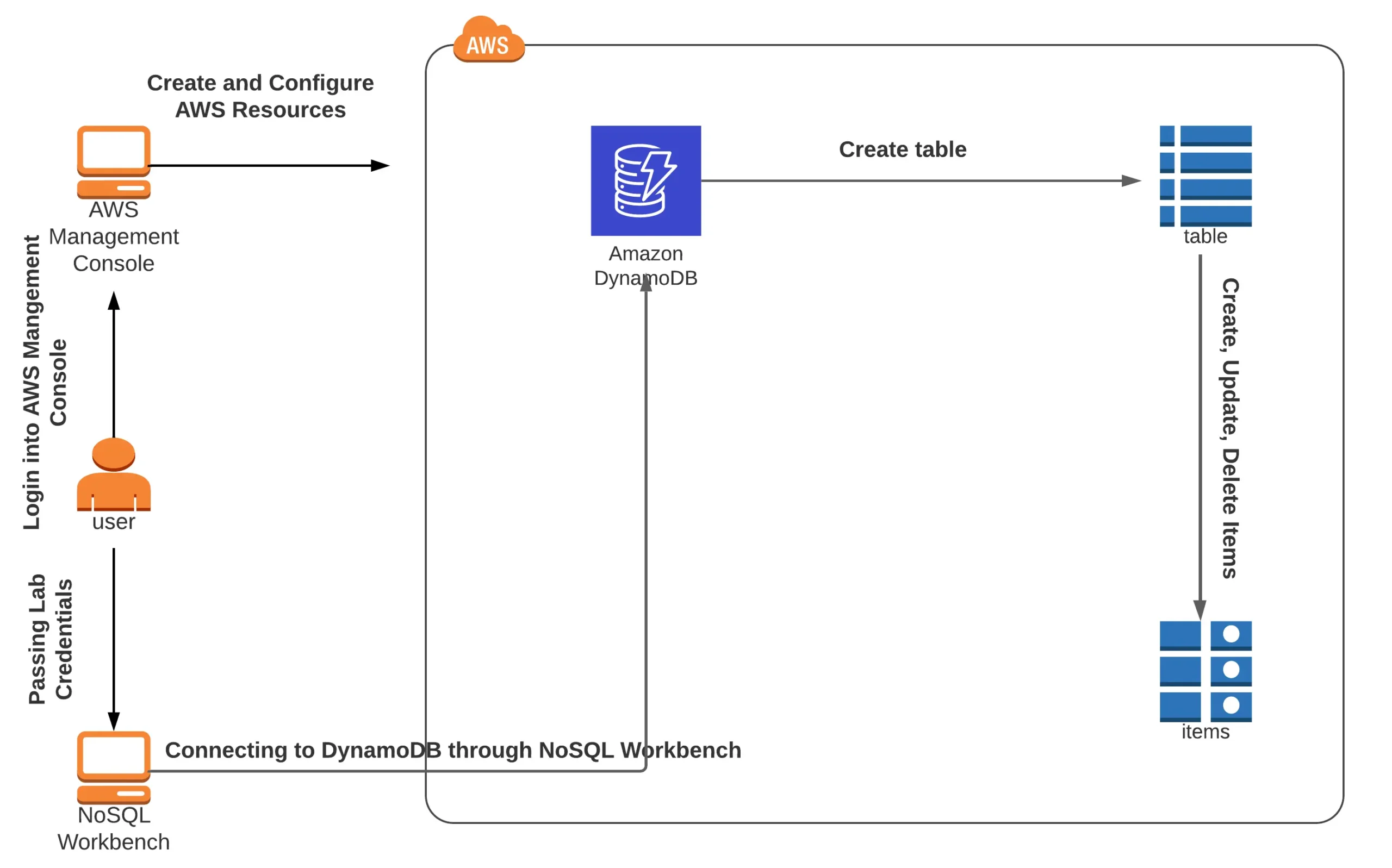
Lab 1: Create a DynamoDB table and use the NoSQL Workbench to execute different table operations.
In this lab, you will learn how to use the NoSQL Workbench and DynamoDB Console. With NoSQL Workbench, you will create a DynamoDB table, execute CRUD operations, and see the changes in the DynamoDB console. Furthermore, you will be generating a DynamoDB table within the console, adding entries, and viewing the reflections within the NoSQL Workbench.
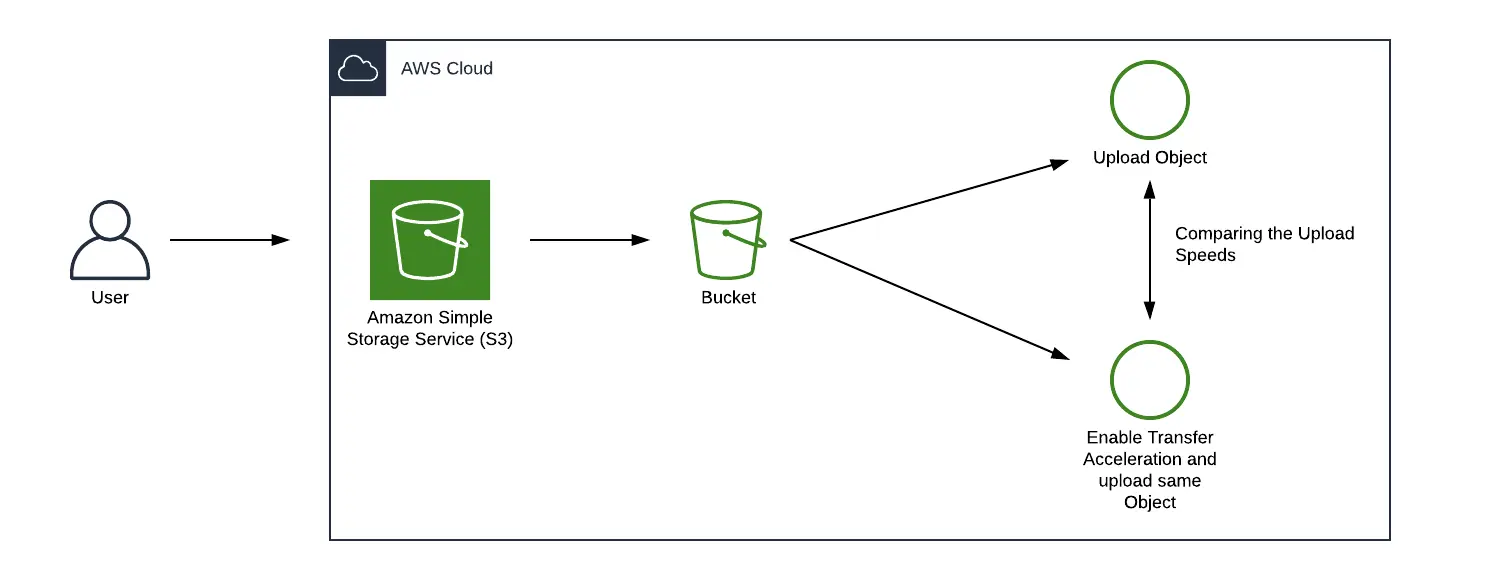
Lab 2: Data Transfer Speed Comparison Using S3 Transfer Acceleration
This lab shows you how to set up an S3 bucket and compare file upload speeds using Transfer Accelerated Upload and Direct Upload.
You’ll get some experience with Amazon S3.
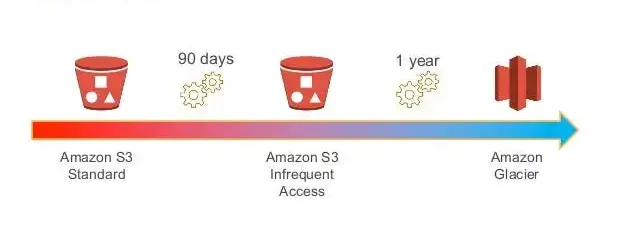
Lab 3: S3 Lifecycle Policy Creation
The procedures to build a lifecycle rule for an object in an S3 bucket are demonstrated in this lab.
To specify what steps you want Amazon S3 to take—such as moving objects to a different storage class, archiving them, or deleting them after a predetermined amount of time—you may use lifecycle rules.
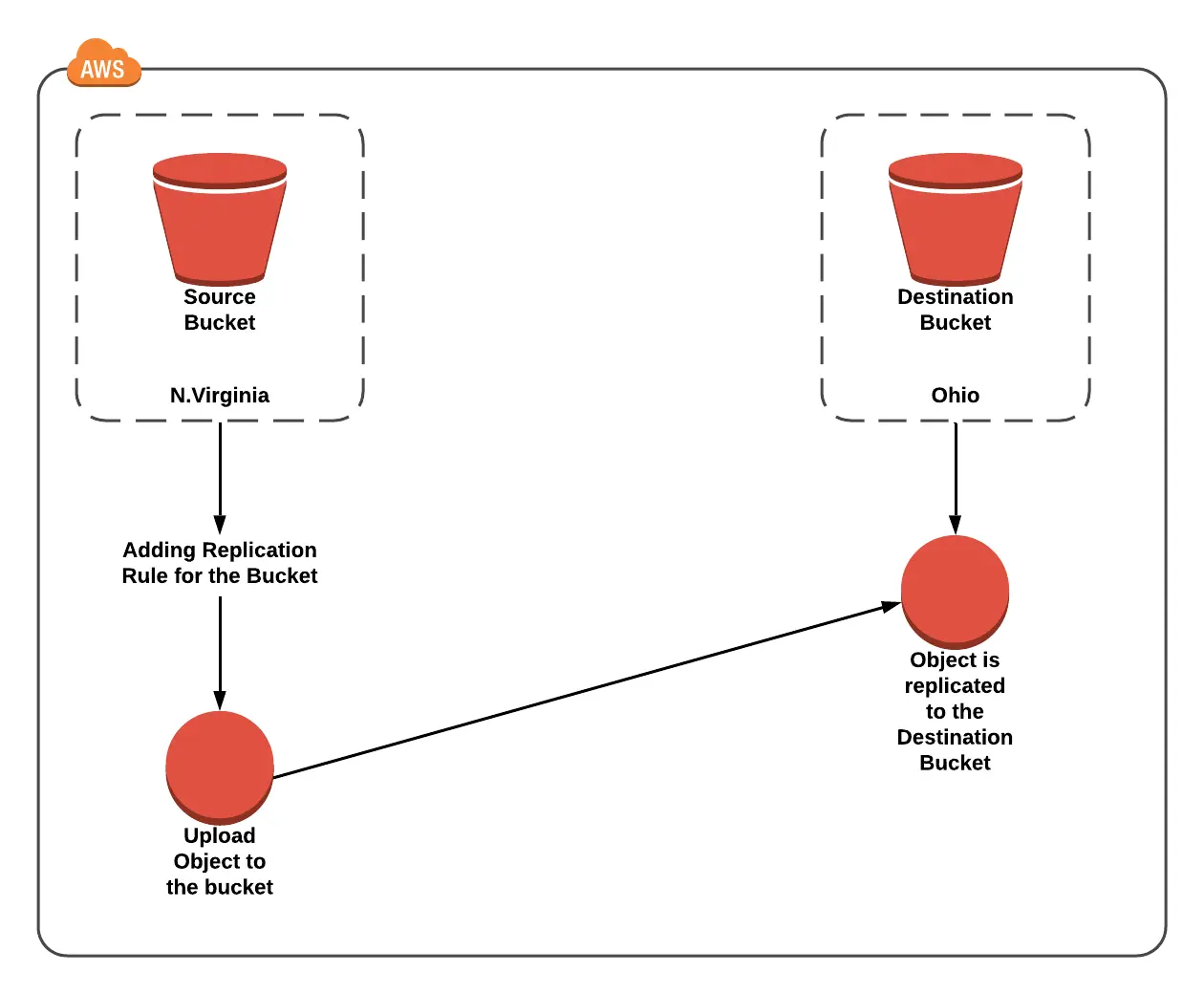
Lab 4: Configure S3 for cross-region replication and versioning.
Using Amazon S3, this lesson explains how to implement versioning and cross-region replication. To achieve this, the procedures need to utilize an S3 bucket.
1.4 Data Support and Operations
There are a total of 5 labs in this module, which will provide you with hands-on practice in data support and operations in the data engineering exam course.
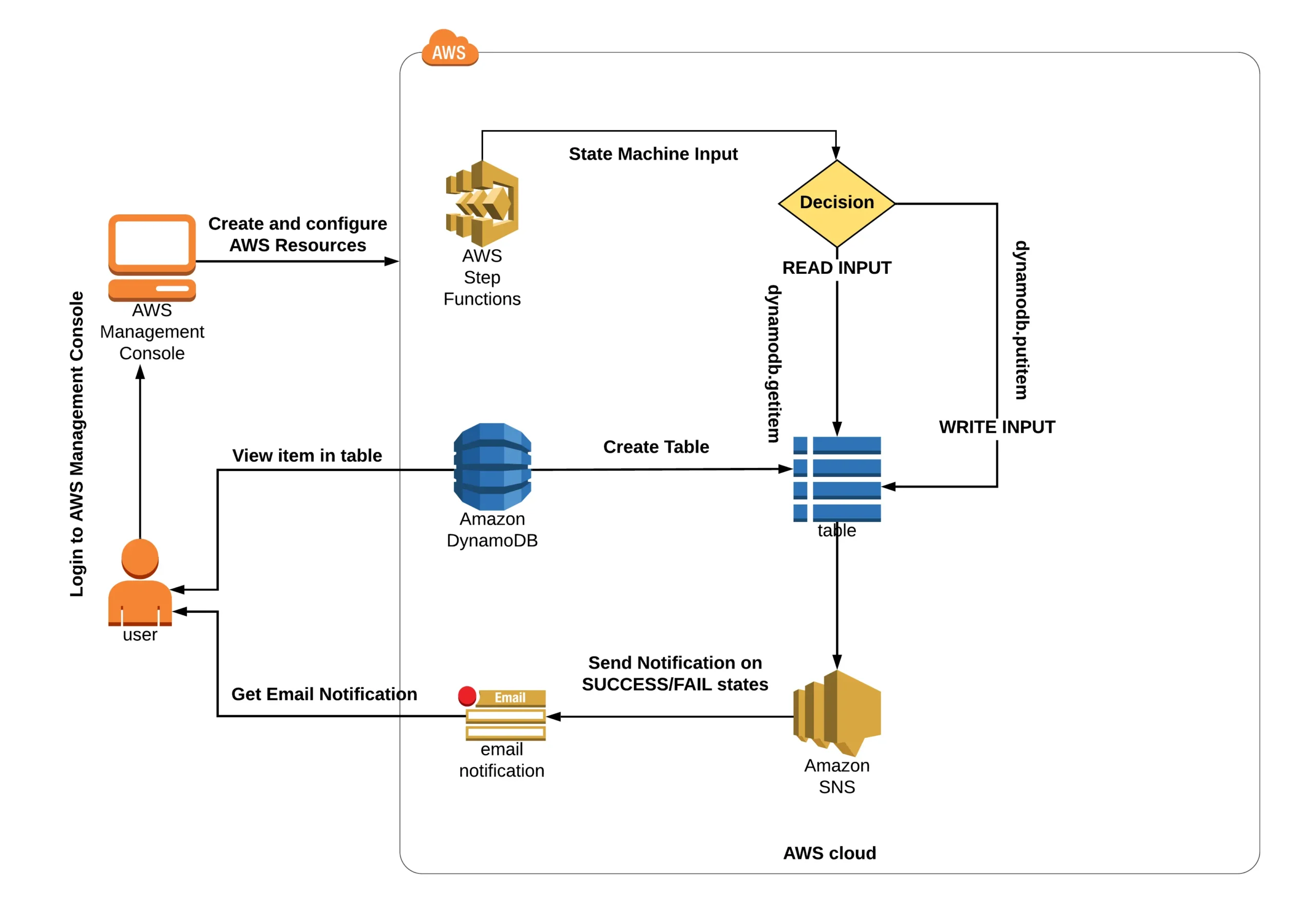
Lab 1: Using Amazon Step Functions to Create a Serverless Workflow
You can construct a function step-by-step with the help of this tutorial. It includes defining the function, completing put and get requests in DynamoDB, and sending out SNS messages to update the status of the operation.
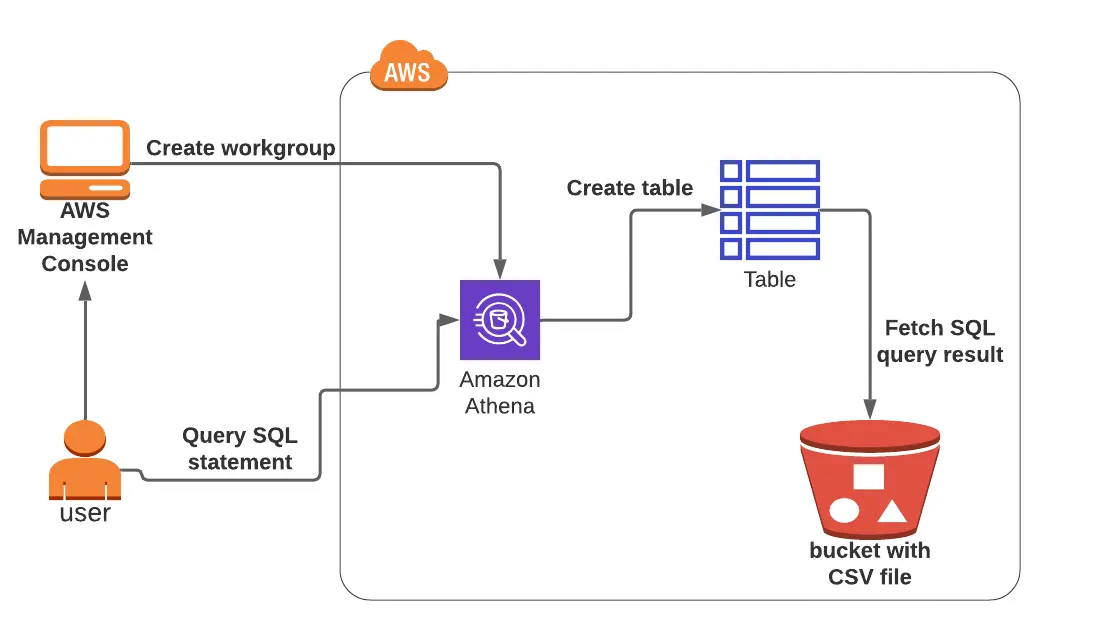
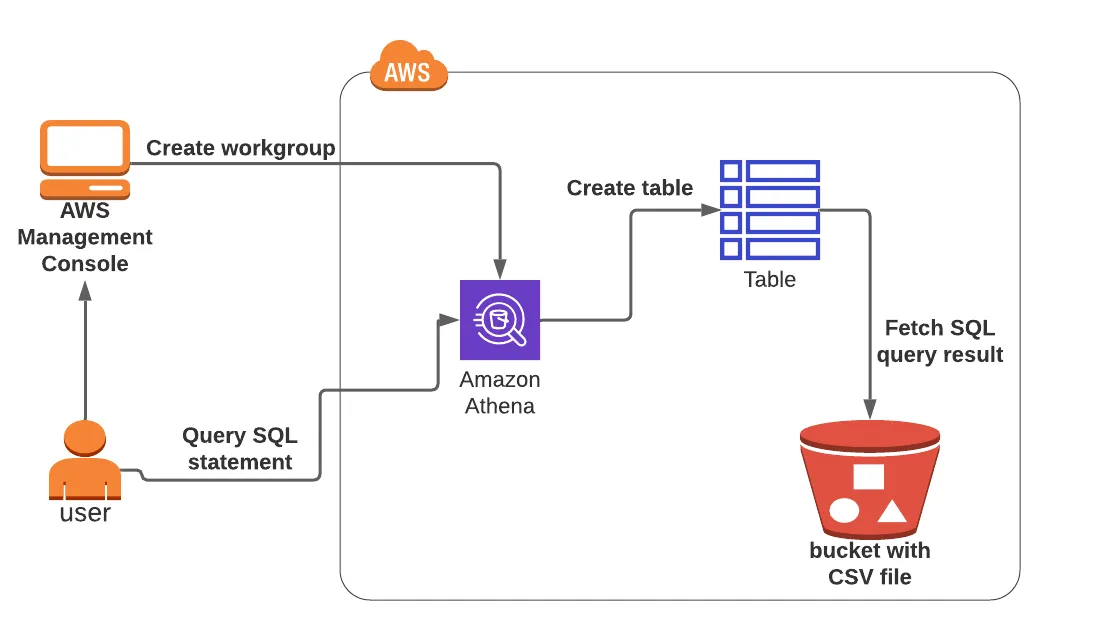
Lab 2: Data S3 Querying Using Amazon Athena
SQL statements can be used in this lab to query and evaluate data kept in an S3 bucket. The lab’s objective is to teach users how to create tables in Amazon Athena, set up the required parameters, and run SQL queries.
You will practice creating a table with a CSV file from the S3 bucket and running an SQL query using Amazon Athena.
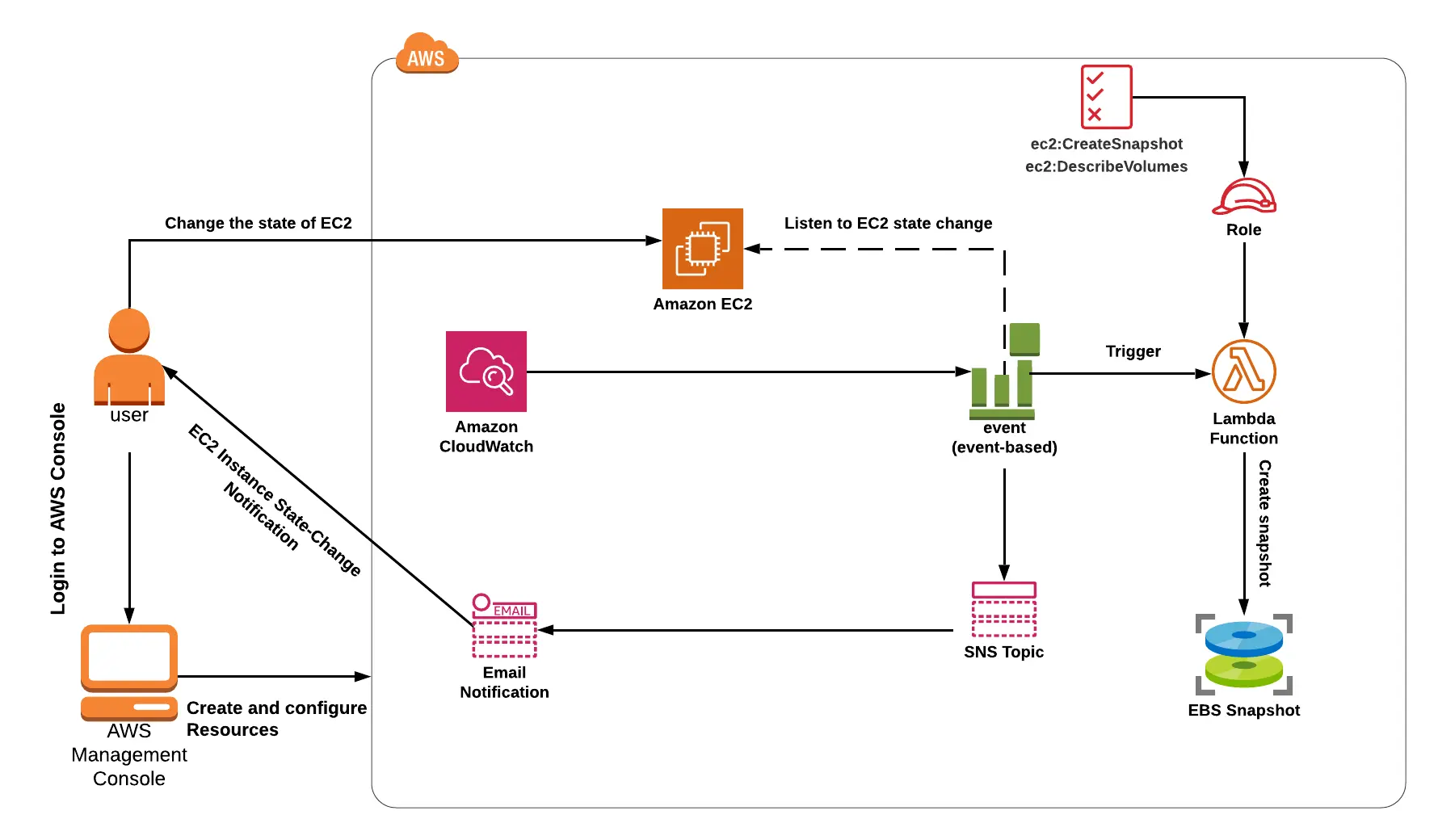
Lab 3: SNS and CloudWatch for Automating the Creation of EBS Snapshots
This lab shows you how to use SNS and CloudWatch to automate the creation of EBS snapshots.
You can back up the data on your Amazon EBS volumes by creating point-in-time copies, also known as Amazon EBS snapshots. A snapshot is an incremental backup, which means we only preserve the blocks on the device that have changed since your last snapshot.
SNS and CloudWatch will be used in practice.
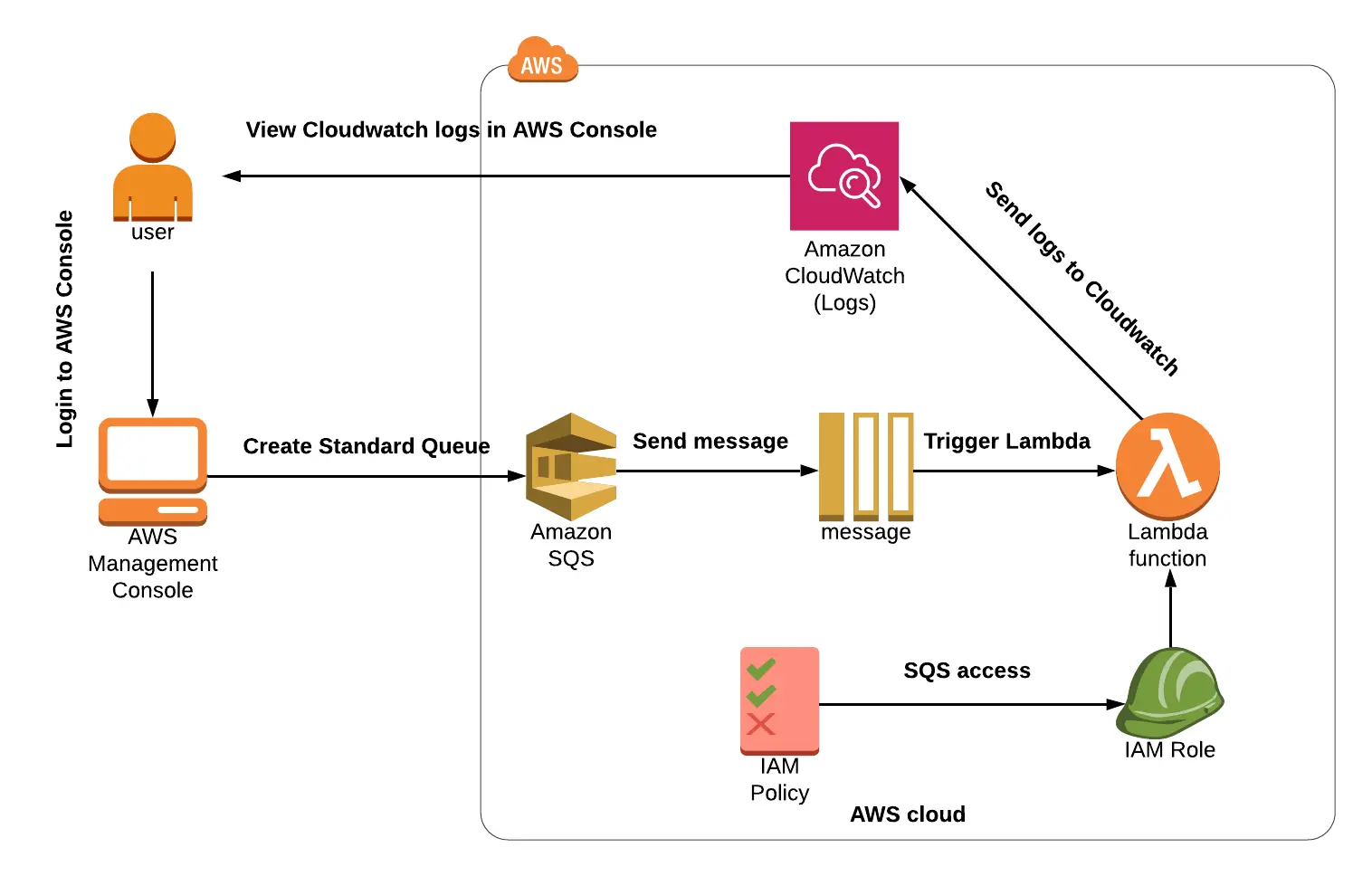
Lab 4: Setting Up CloudWatch Logs for SQS using a Lambda Function Trigger
This lab shows you how to use a Lambda function to create CloudWatch logs for SQS.
CloudWatch Logs allows you to centralize logs from all of your systems, apps, and AWS services into a single, scalable service. You can then simply browse them, search for specific error codes or patterns, filter them by field, or safely archive them for later research.
You will practice utilizing CloudWatch and Lambda with SQS.
Lab 5: Creating CloudWatch Dashboards and Alarms and Monitoring Resources with CloudWatch
The various CloudWatch functionalities that are utilized for resource monitoring are walked through in this lab. To efficiently manage your resources and set up notifications for crucial indicators, you will learn how to construct CloudWatch alarms and dashboards.
1.5 Data Governance and Security
There are a total of 7 labs in this module, which will guide you with hands-on practice in data governance and security in the data engineering exam course.
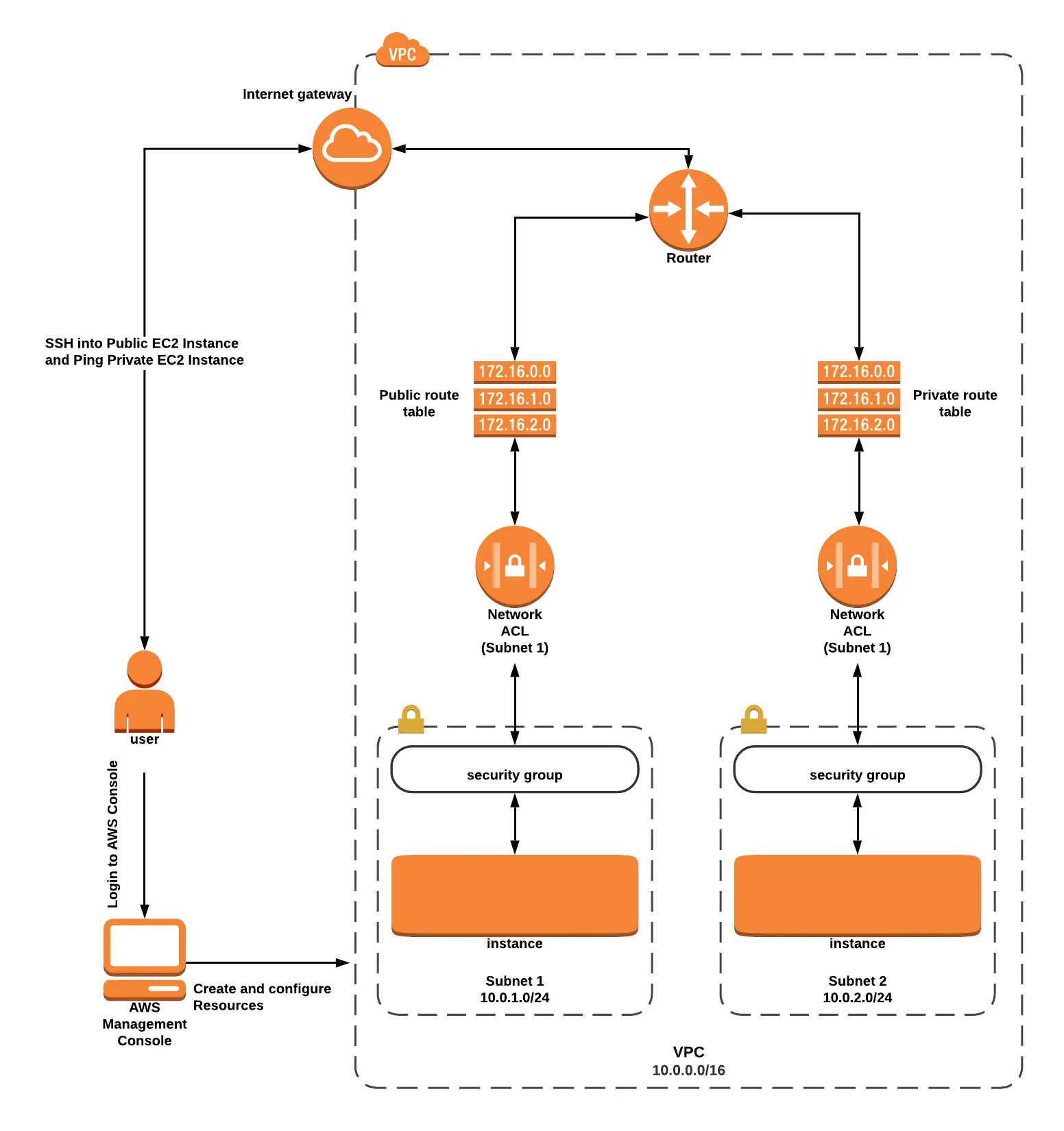
Lab 1: How to Interpret and Set Up Layered Security in an AWS VPC
This experiment demonstrates how to launch two EC2 instances (one in a public subnet and the other in a private subnet) and configure multi-layered security in an AWS VPC.
Using Amazon VPC and Amazon EC2 services, you will practice it.
To learn more about VPC: Amazon Virtual Private Cloud (AWS VPC)
Lab 2: Creating IAM Roles
The processes for creating IAM roles are shown in this lab.
You can create an IAM identity in your account with particular rights called an IAM role. An AWS identity with authorization policies dictating what the identity can and cannot do in AWS is what distinguishes an IAM role from an IAM user.
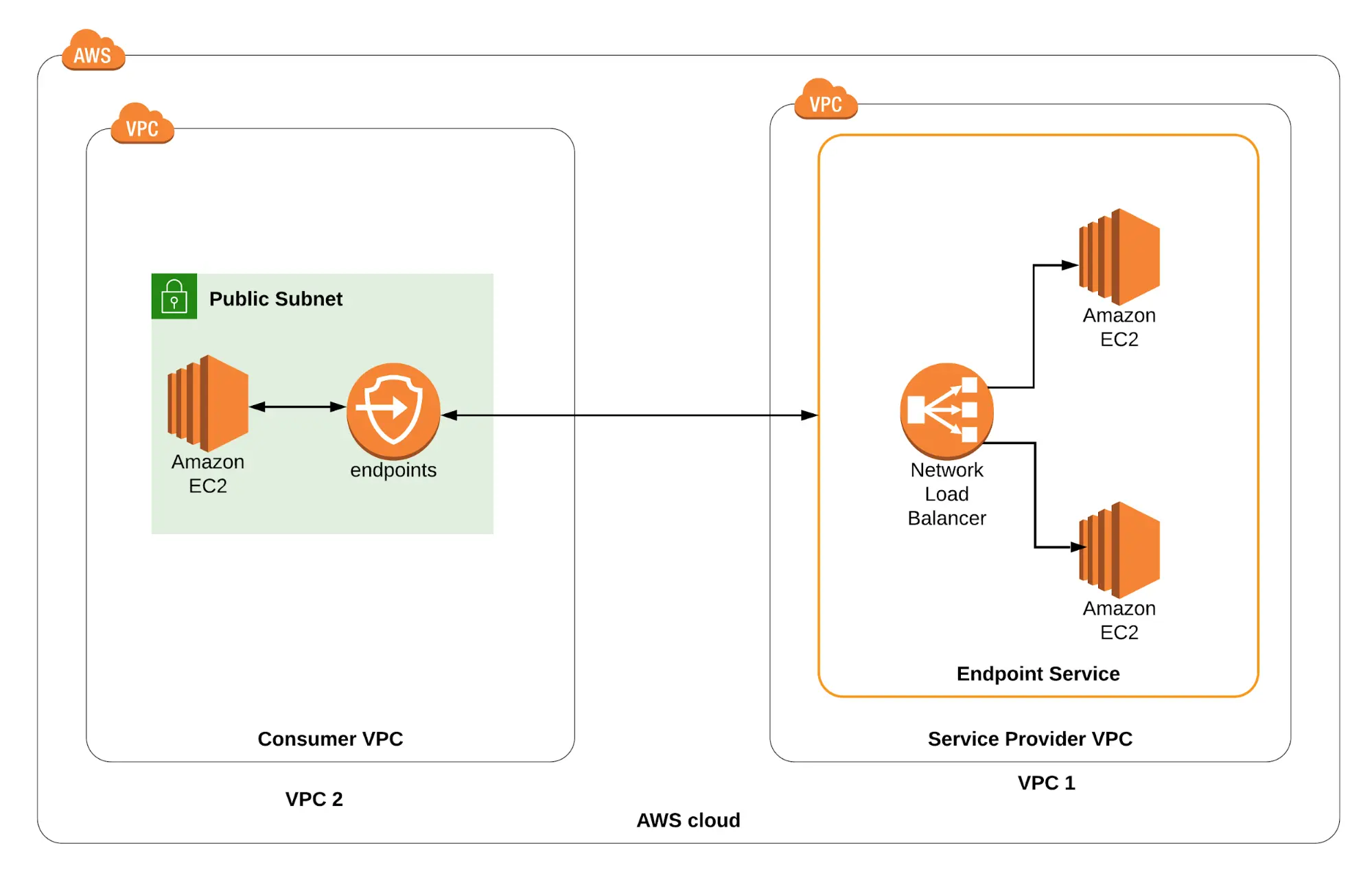
Lab 3: How to set up a VPC Endpoint service from beginning to end
This experiment demonstrates how to use Endpoint service to establish an end-to-end connection between two VPCs (service provider and customer).
In the lab, you will practice utilizing VPC, ELB, and EC2.
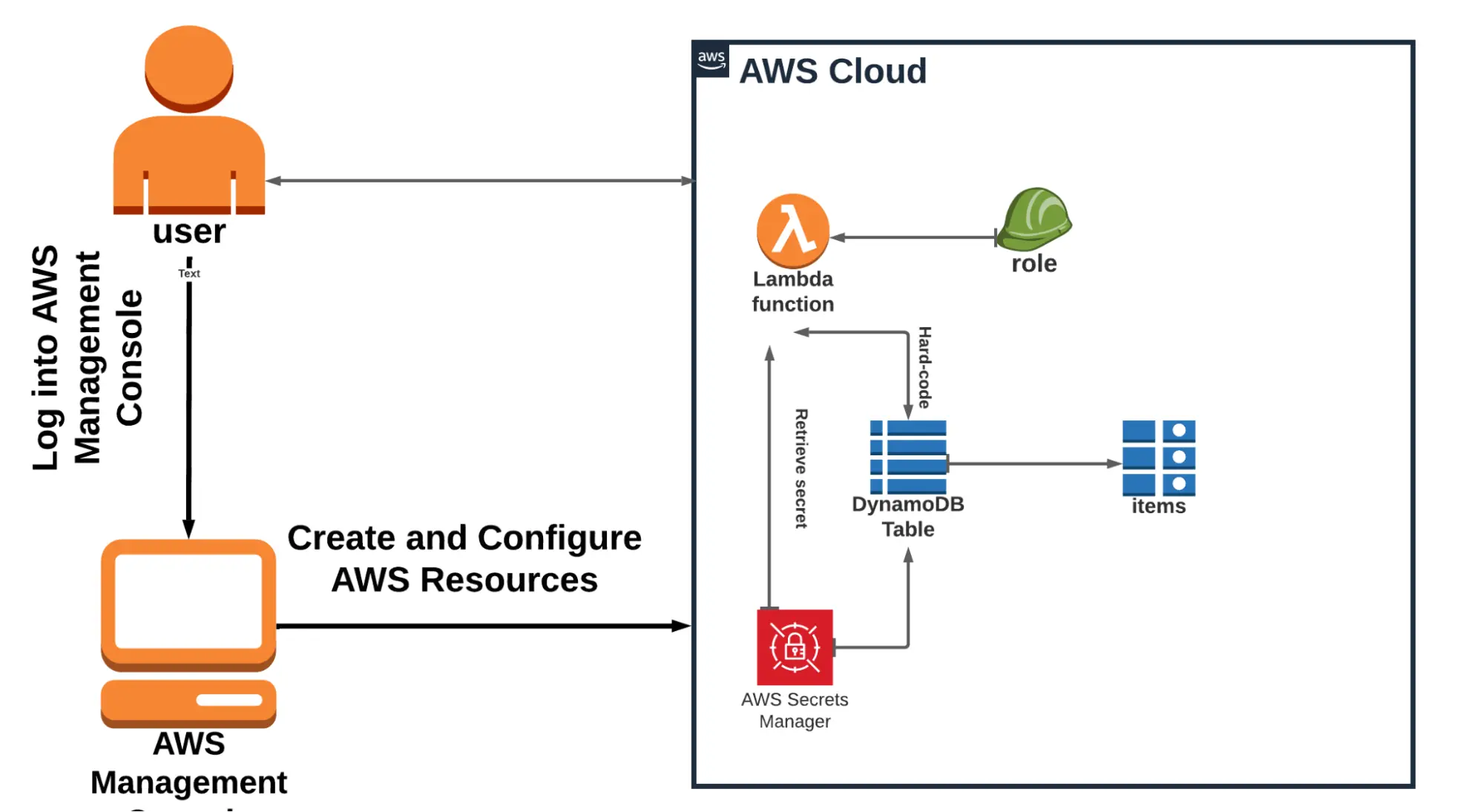
Lab 4: How to use AWS Lambda to extract secrets from AWS Secrets Manager
This lab demonstrates how to use AWS Lambda to extract secrets from AWS Secrets Manager.
Without requiring an SDK, you may retrieve and cache AWS Secrets Manager secrets in Lambda functions by utilizing the AWS Parameters and Secrets Lambda Extension. It takes less time to retrieve a secret from the cache than it does from Secrets Manager. Using a cache can lower your costs because calling Secrets Manager APIs has a cost.
Lab 5: Creating IAM Policies
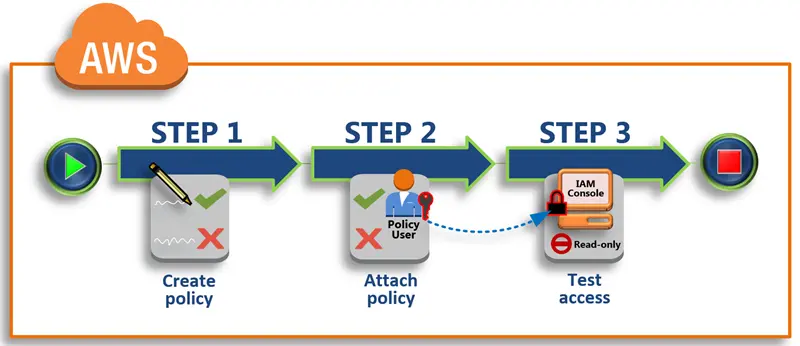
This lab guides you through the process of creating IAM policies for various AWS services, including DynamoDB, S3, and EC2.
An entity that establishes the permissions for an identity or resource is called a policy. To build customer-controlled policies in IAM, you can utilize the AWS Management Console, AWS CLI, or AWS API.
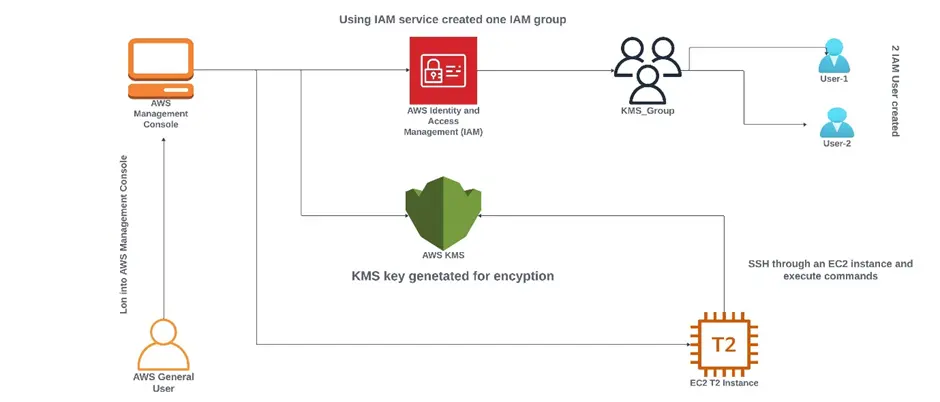
Lab 6: Using KMS for Encryption and Decryption
This lab walks you through the steps to encrypt decrypt, and re-encrypt the data.
Use a client-side encryption library, such as the Amazon S3 encryption client the AWS Encryption SDK, or the server-side encryption features of an AWS service to encrypt application data.
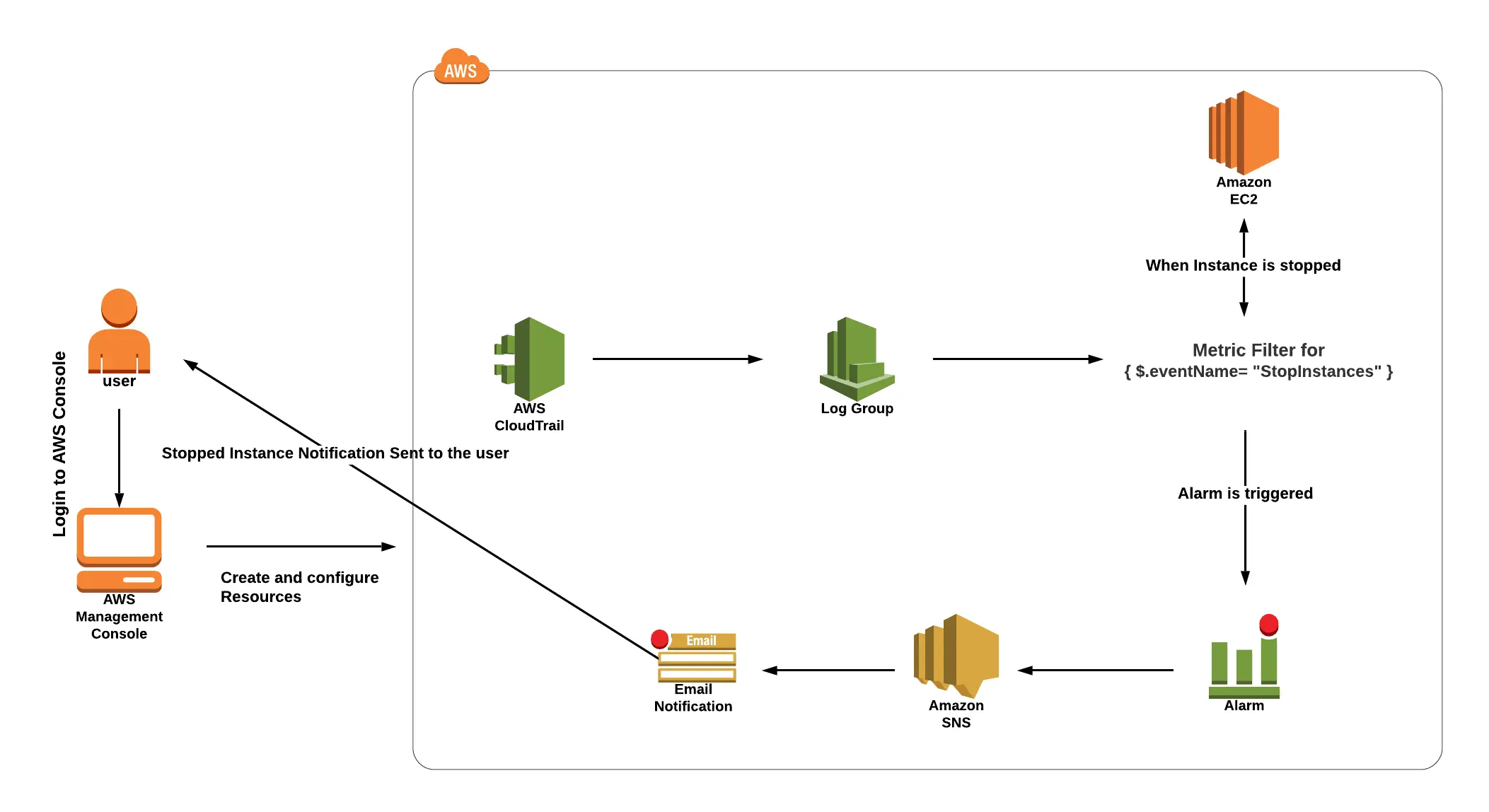
Lab 7: Alerts from AWS Access Control using CloudWatch and CloudTrail
To get an alarm from CloudWatch via SNS topic, this lab guides you through the process of setting a Cloudtrail and CloudWatch log group as well as a metric filter.
Real-time Projects
This part of the blog covers around 5 real-time Projects that will help you gain practical experience and Hands-On practice for the AWS Data Engineering exam and will also guide you for the AWS Data Engineering Job roles.
Project 1: Initial Data Handling and ETL Configuration with AWS Glue
In this project, you will learn the basics of setting up AWS Glue for your data handling needs. We will cover how to configure AWS Glue to perform ETL (Extract, Transform, Load) tasks, starting with data discovery, cataloging, and preparation. By the end of this project, you will have a foundational understanding of AWS Glue, enabling you to efficiently prepare and transform data for analytical or operational purposes.
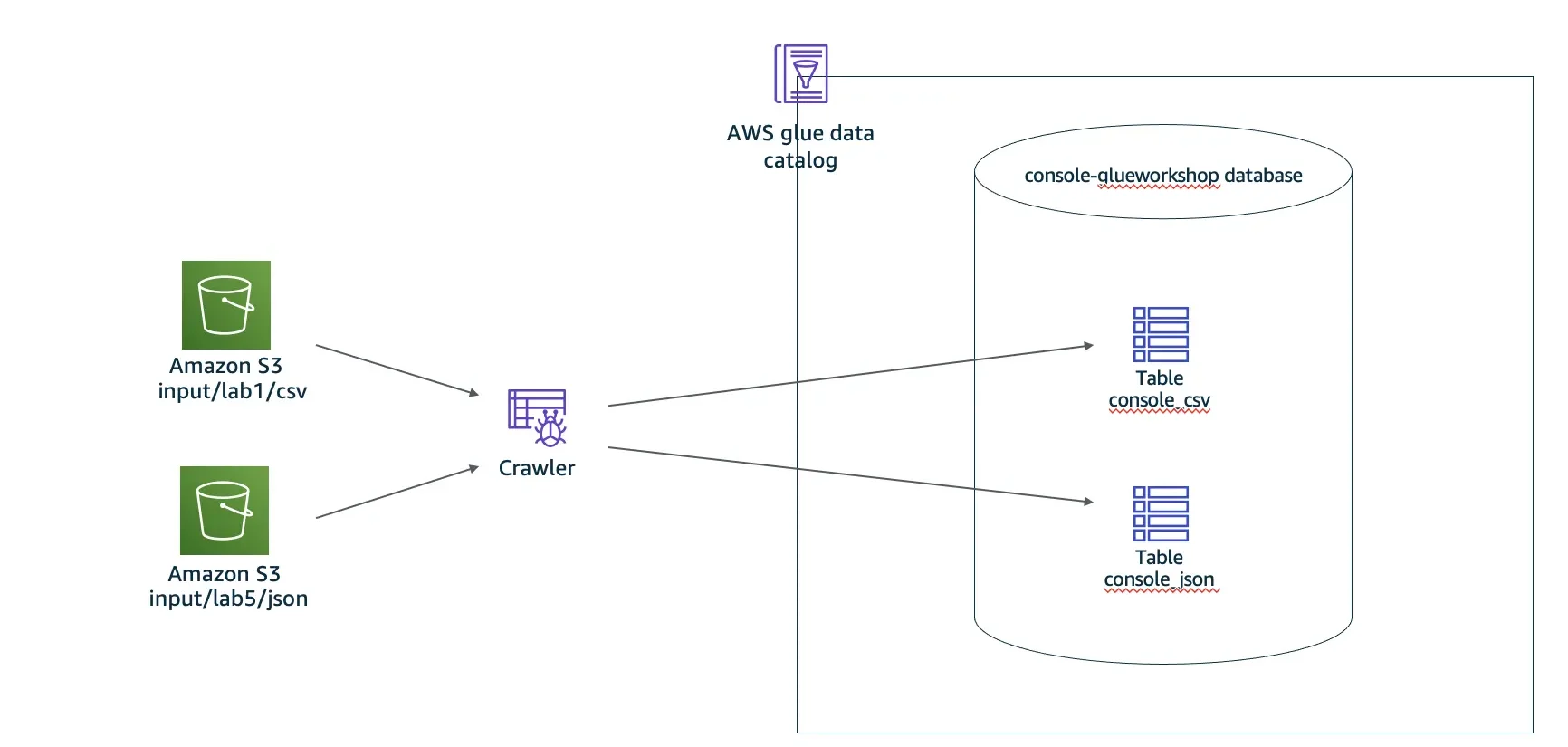
Project 2: Complex Data Processing and Enhanced Analysis Techniques with AWS Glue
This project delves into advanced data processing and analysis techniques using AWS Glue. We will explore complex ETL operations, optimizing job performance, and integrating AWS Glue with other analytics services for enhanced data analysis. Achieving mastery over these advanced techniques will allow you to handle large-scale data processing tasks and derive deeper insights from your data.
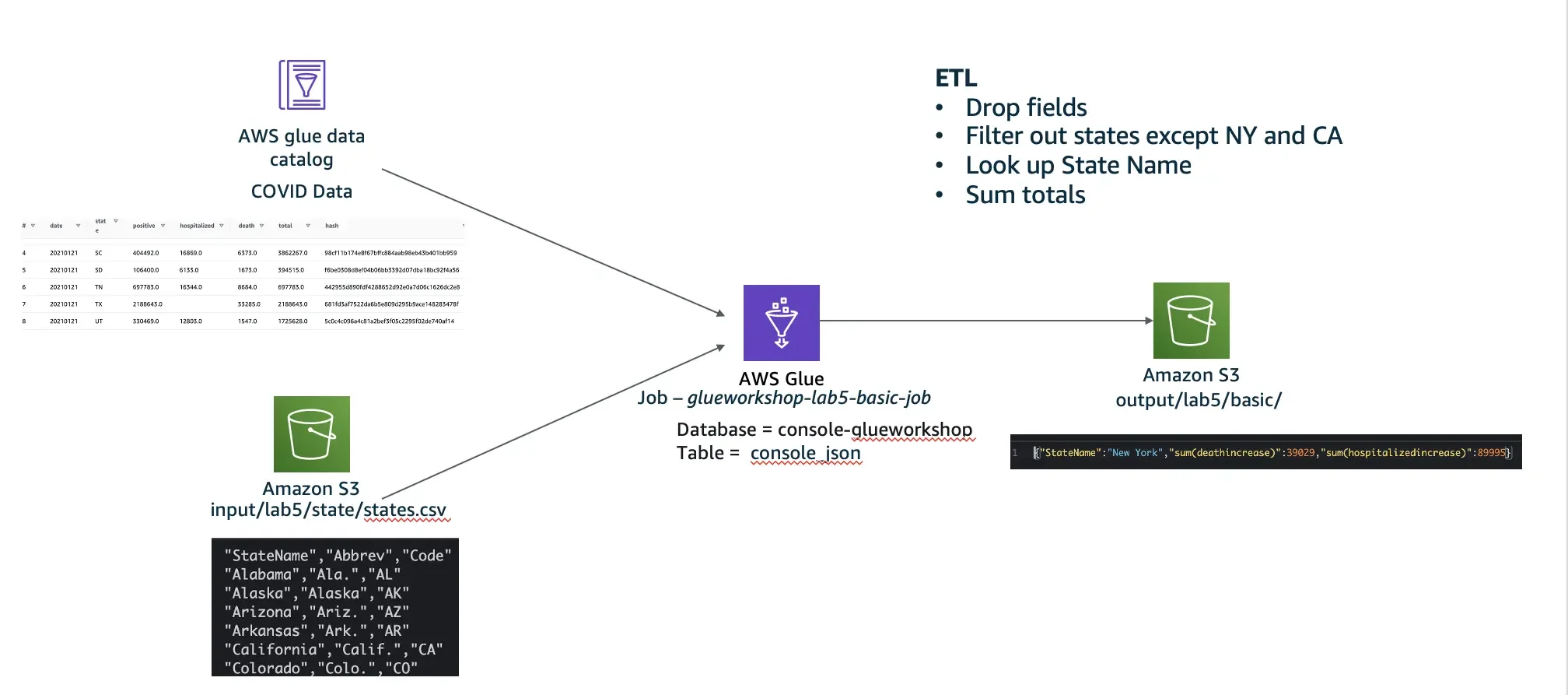
Project 3: Real-Time Data Analysis with ACID-Compliant Transactions in Amazon Athena
Focusing on Amazon Athena, this project introduces the concept of performing real-time data analysis while maintaining ACID-compliant transactions. We will cover how to query and analyze data stored in Amazon S3, ensuring data integrity and consistency with ACID transactions. By the end of this project, you will be able to implement robust, real-time analytical solutions that support transactional data operations.
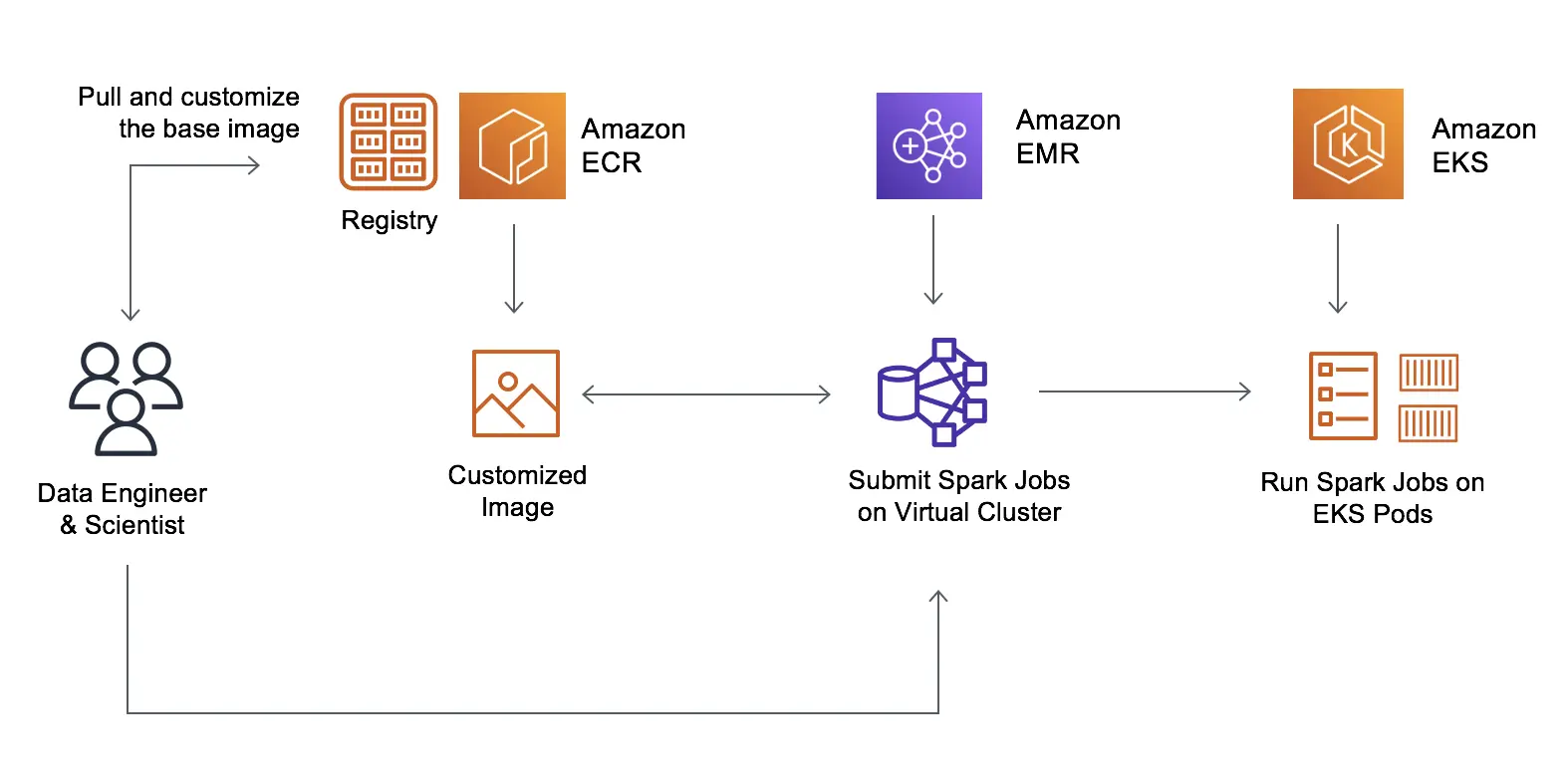 Project 4: Setting Up and Executing Your First Amazon EMR Data Processing Workflow
Project 4: Setting Up and Executing Your First Amazon EMR Data Processing Workflow
In this project, we will guide you through the process of setting up your first Amazon EMR cluster and executing a data processing workflow. From selecting the right hardware and software configurations to running and monitoring your first jobs, you will learn the essentials of leveraging Amazon EMR for scalable data processing. This project will equip you with the skills to harness the power of Amazon EMR for big data analytics.
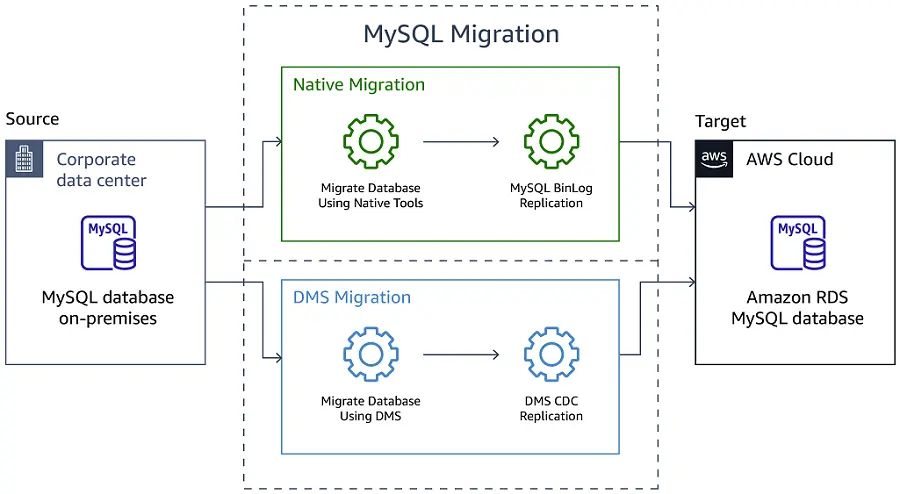
Project 5: Migrate from MySQL to Amazon RDS with AWS DMS
This project is focused on migrating databases from MySQL to Amazon RDS using the AWS Database Migration Service (DMS). We will cover the steps required for a successful migration, including the preparation of your MySQL database, configuring AWS DMS for migration, and performing the migration to Amazon RDS. Upon completion, you will have achieved a seamless transition to a fully managed database service, enhancing the scalability, performance, and availability of your database applications.
 Each project is designed to build upon your knowledge and skills in using AWS services for data processing, analysis, and management, empowering you to create efficient, scalable, and robust solutions in the cloud.
Each project is designed to build upon your knowledge and skills in using AWS services for data processing, analysis, and management, empowering you to create efficient, scalable, and robust solutions in the cloud.
No comments:
Post a Comment