SQL Stretch Database
It migrates our cold data transparently and securely to the Microsoft Azure Cloud. Stretch database divides the data into two types. One is the hot data, which is frequently accessed, and the second one is cold data, which is infrequently accessed. Also, we can define policies or criteria for hard data and cold data.
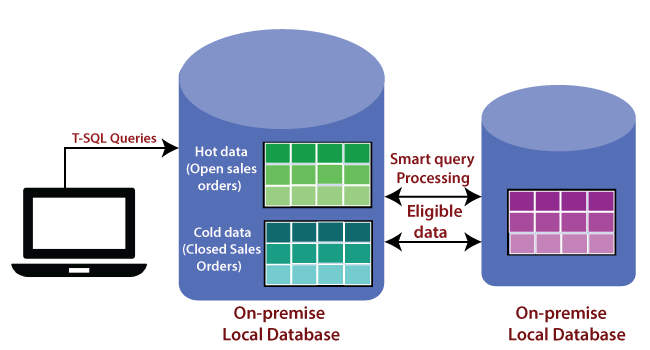
For example - if we have a sales order table, all those open and in Program Sales orders can be hot data, and all the closed sales orders can be cold data. The cold data will be transparently migrated to Azure SQL Stretch Database. However, it doesn't mean that we need to change our application in such a way that for open sales orders, we need to go to Azure SQL Stretch Database.
We can use the same queries in our application to fetch the data and based on the location of data, and the query will be automatically sent to Stretch Database.
Advantages of SQL Stretch Database
- It provides cost-effective availability for cold data that benefits from the low cost of Azure rather than scaling expensive on-premises storage.
- It doesn't require changes to the existing queries or applications. The position of the data is transparent to the application.
- It reduces the on-premises maintenance and storage for our data. Backups for our on-premises data run faster and finish within the maintenance window. Backups for the cloud portion of our data run automatically.
- It keeps our data secure even during migration. It provides encryption for our data in motion. Row-level security and other advanced SQL Server security feature also work with Stretch Database to protect our data.
SQL Data Warehouse
Microsoft SQL Data Warehouse within Azure is a cloud-based at scale-out database capable of processing massive volume of data, both relational and non-relational and SQL Data Warehouse is based on massively parallel processing architecture.
In this architecture, requests are received by the control node, optimized, and passed on to the compute nodes to do work in parallel. SQL data warehouse stores the data in Premium locally redundant storage, and linked to computing nodes for query extraction.
Components of SQL Data Warehouse
Data Warehouse units: Allocation of resources to our SQL Data Warehouse is measured in Data Warehouse Units (DWUs). DWUs is a measure of underlying resources like CPU, memory, IOPS, which are allocated to our SQL Data Warehouse.
Data Warehouse units provide a measure of three precise metrics that are highly correlated with data warehouse workload performance.
- Scan/Aggregation: Scan/Aggregation takes the standard data warehousing query. It scans a large number of rows and then performs a complex aggregation. It is an I/O and CPU intensive operation.
- Load: This metric measures the ability to ingest data into the service. This metric is designed to stress the network and CPU aspects of the service.
- Create Table As Select (CTAS): CTAS measures the ability to copy a table. It involves reading data from storage, distributing it across the nodes of the appliance, and writing it to storage again. It is a CPU, IO, and network-intensive operation.
No comments:
Post a Comment