- RTO is the time it takes after a disruption to restore a business process to its service level.
- RPO is the acceptable amount of data loss measured in time before the disaster occurs.
- Disaster Recovery With AWS
Backup and Restore – storing backup data on S3 and recover data quickly and reliably.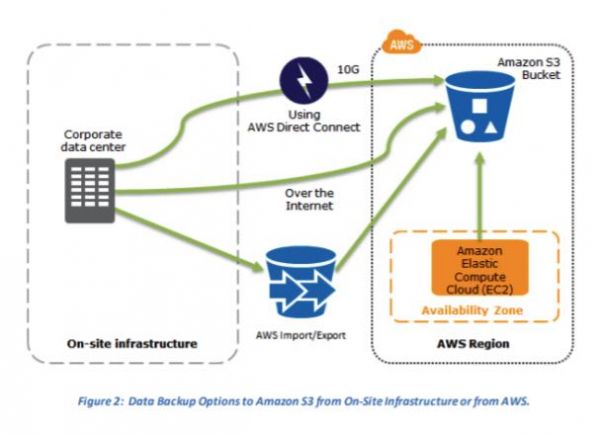
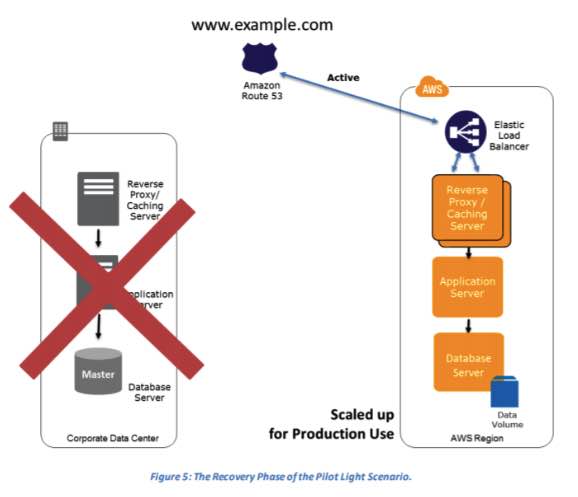
Pilot Light for Quick Recovery into AWS – quicker recovery time than backup and restore because core pieces of the system are already running and are continually kept up to date.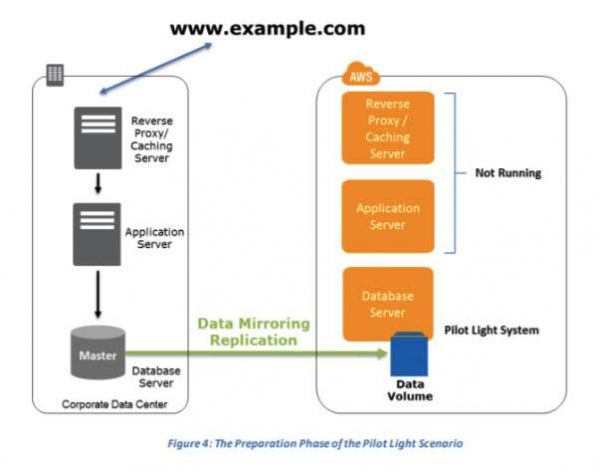
Warm Standby Solution – a scaled-down version of a fully functional environment is always running in the cloud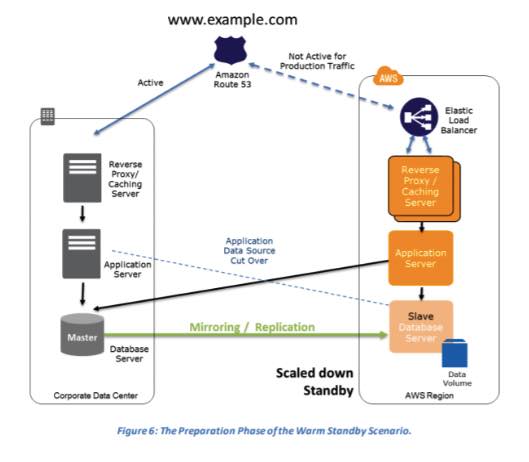
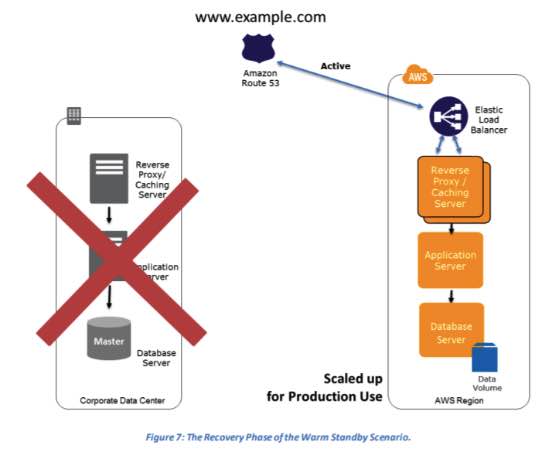
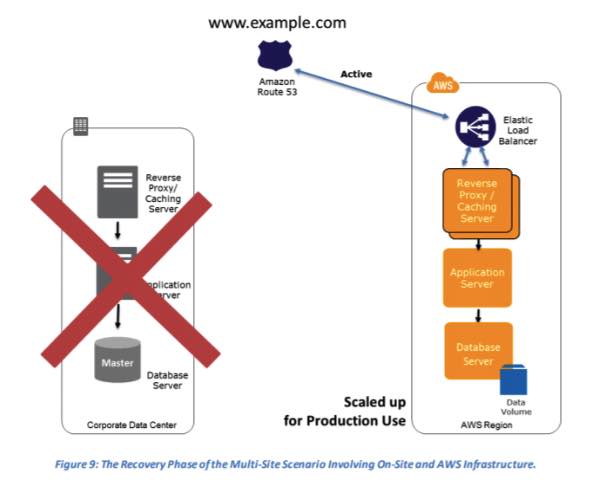
Multi-Site Solution – run your infrastructure on another site, in an active-active configuration.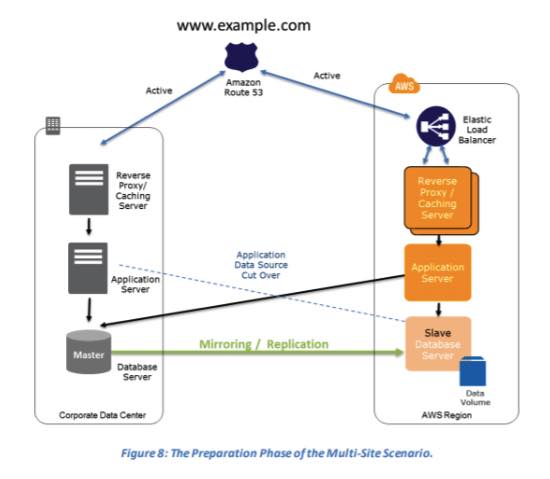
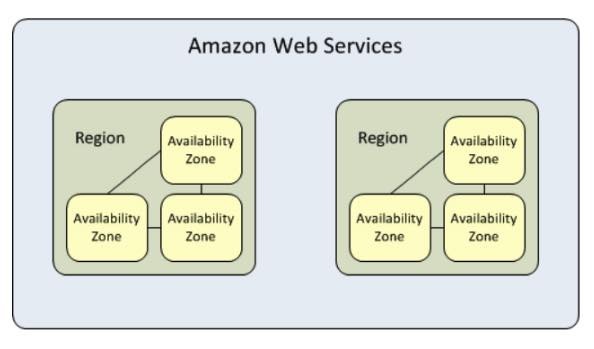
- AWS Production to an AWS DR Solution Using Multiple AWS Regions – take advantage of AWS’ multiple availability zones
- S3 as a destination for backup data that might be needed quickly to perform a restore.
- Import/Export for transferring very large data sets by shipping storage devices directly to AWS.
- Glacier for longer-term data storage where retrieval times of several hours are adequate.
- Server Migration Service for performing agentless server migrations from on-premises to AWS.
- Database Migration Service and Schema Conversion Tool for moving databases from on-premises to AWS and automatically converting SQL schema from one engine to another.
- Storage Gateway copies snapshots of your on-premises data volumes to S3 for backup. You can create local volumes or EBS volumes from these snapshots.
- Preconfigured servers bundled as Amazon Machine Images (AMIs).
- Elastic Load Balancing (ELB) for distributing traffic to multiple instances.
- Route 53 for routing production traffic to different sites that deliver the same application or service.
- Elastic IP address for static IP addresses.
- Virtual Private Cloud (Amazon VPC) for provisioning a private, isolated section of the AWS cloud.
- Direct Connect for a dedicated network connection from your premises to AWS.
- Relational Database Service (RDS) for scale of a relational database in the cloud.
- DynamoDB for a fully managed NoSQL database service to store and retrieve any amount of data and serve any level of request traffic.
- Redshift for a petabyte-scale data warehouse service that analyzes all your data using existing business intelligence tools.
- CloudFormation for creating a collection of related AWS resources and provision them in an orderly and predictable fashion.
- Elastic Beanstalk is a service for deploying and scaling web applications and services developed.
- OpsWorks is an application management service for deploying and operating applications of all types and sizes.