Automatic scaling in Azure App Service
Automatic scaling is a new scale-out option that automatically handles scaling decisions for your web apps and App Service Plans. It's different from the pre-existing Azure autoscale, which lets you define scaling rules based on schedules and resources. With automatic scaling, you can adjust scaling settings to improve your app's performance and avoid cold start issues. The platform prewarms instances to act as a buffer when scaling out, ensuring smooth performance transitions. You're charged per second for every instance, including prewarmed instances.
A comparison of scale-out and scale in options available on App Service:
How automatic scaling works
You enable automatic scaling for an App Service Plan and configure a range of instances for each of the web apps. As your web app starts receiving HTTP traffic, App Service monitors the load and adds instances. Resources may be shared when multiple web apps within an App Service Plan are required to scale-out simultaneously.
Here are a few scenarios where you should scale-out automatically:
- You don't want to set up autoscale rules based on resource metrics.
- You want your web apps within the same App Service Plan to scale differently and independently of each other.
- Your web app is connected to a databases or legacy system, which may not scale as fast as the web app. Scaling automatically allows you to set the maximum number of instances your App Service Plan can scale to. This setting helps the web app to not overwhelm the backend.
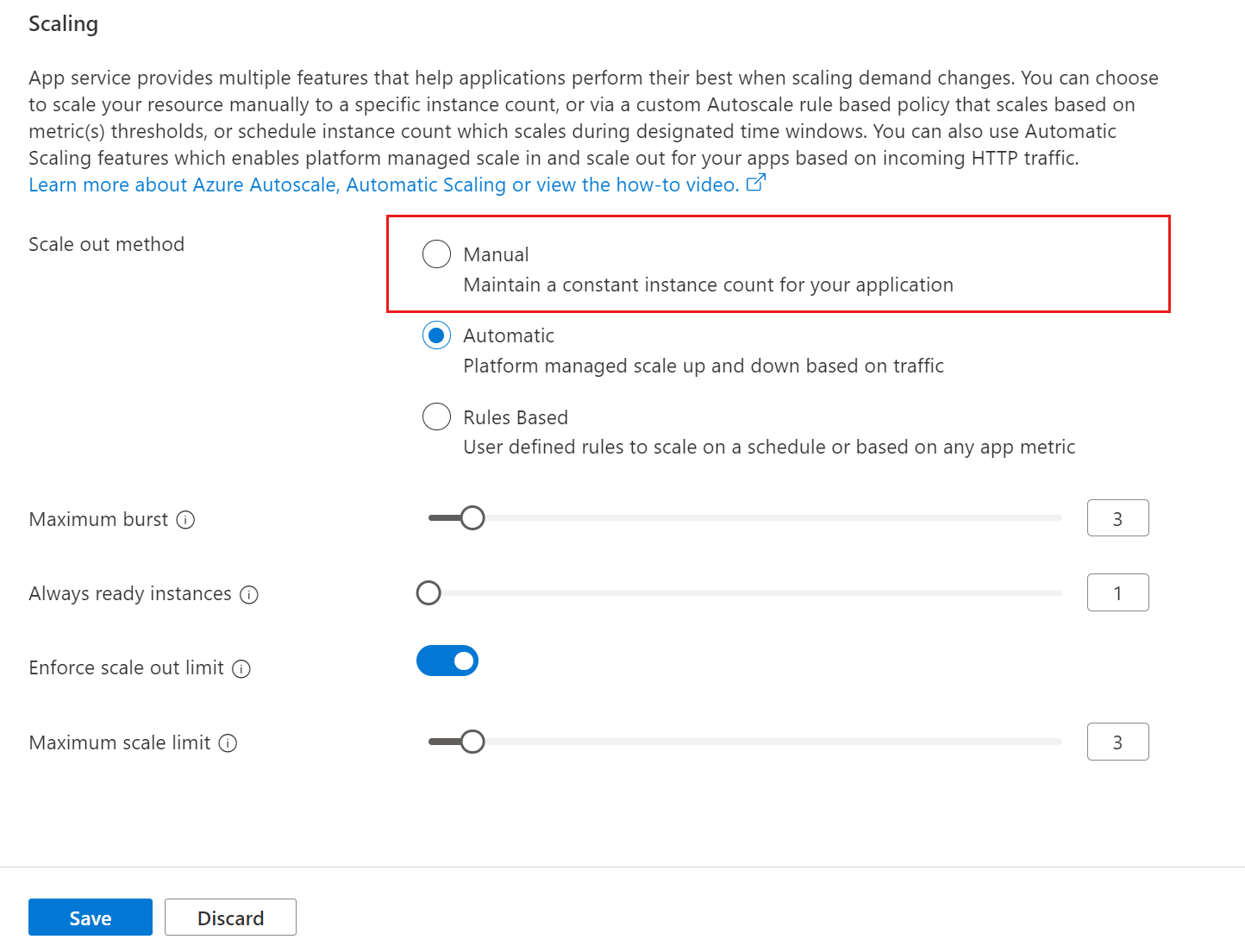
Enable automatic scaling
Maximum burst is the highest number of instances that your App Service Plan can increase to based on incoming HTTP requests. For Premium v2 & v3 plans, you can set a maximum burst of up to 30 instances. The maximum burst must be equal to or greater than the number of workers specified for the App Service Plan.
To enable automatic scaling, navigate to the web app's left menu and select scale-out (App Service Plan). Select Automatic, update the Maximum burst value, and select the Save button.
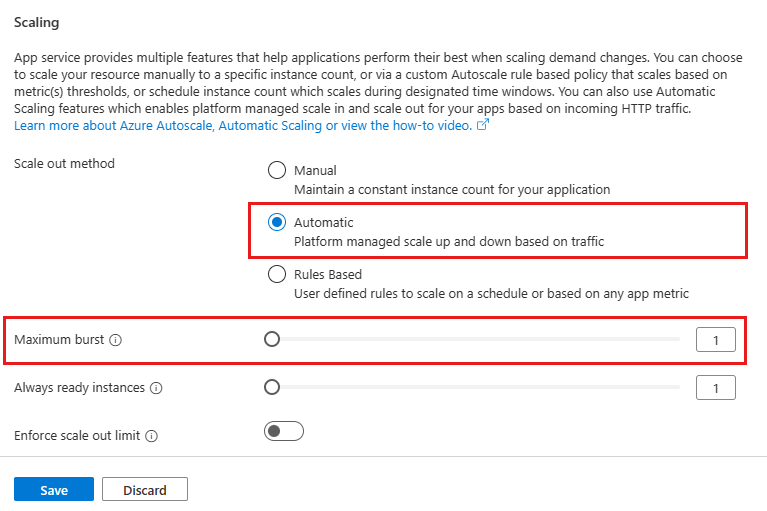
Set minimum number of web app instances
Always ready instances is an app-level setting to specify the minimum number of instances. If load exceeds what the always ready instances can handle, additional instances are added (up to the specified maximum burst for the App Service Plan).
To set the minimum number of web app instances, navigate to the web app's left menu and select scale-out (App Service Plan). Update the Always ready instances value, and select the Save button.
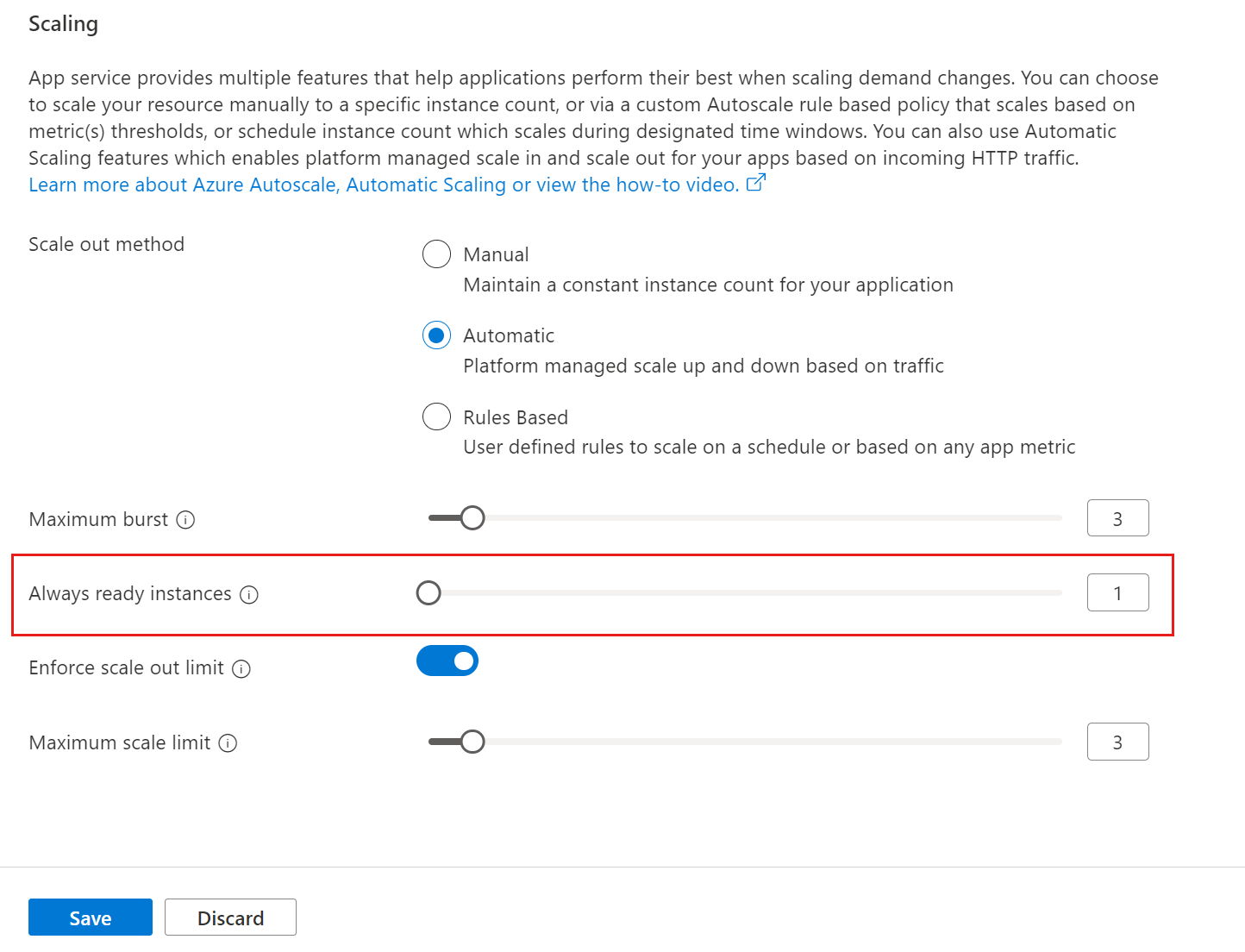
Set maximum number of web app instances
The maximum scale limit sets the maximum number of instances a web app can scale to. The maximum scale limit helps when a downstream component like a database has limited throughput. The per-app maximum can be between 1 and the maximum burst.
To set the maximum number of web app instances, navigate to the web app's left menu and select scale-out (App Service Plan). Select Enforce scale-out limit, update the Maximum scale limit, and select the Save button.
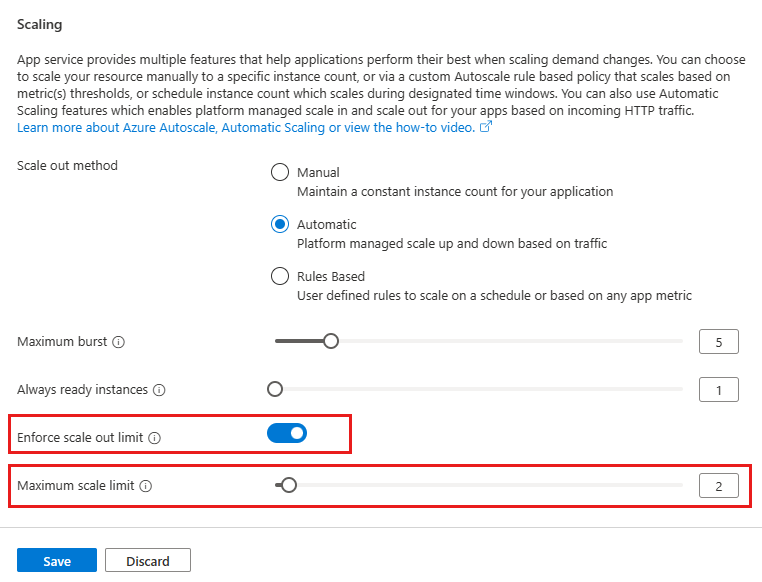
Update prewarmed instances
The prewarmed instance setting provides warmed instances as a buffer during HTTP scale and activation events. Prewarmed instances continue to buffer until the maximum scale-out limit is reached. The default prewarmed instance count is 1 and, for most scenarios, this value should remain as 1.
You can't change the prewarmed instance setting in the portal, you must instead use the Azure CLI.
Disable automatic scaling
To disable automatic scaling, navigate to the web app's left menu and select scale-out (App Service Plan). Select Manual, and select the Save button.