- AWS Database Migration Service supports homogeneous migrations such as Oracle to Oracle, as well as heterogeneous migrations between different database platforms, such as Oracle or Microsoft SQL Server to Amazon Aurora.
- You can use Database Migration Service for one-time data migration into RDS and EC2-based databases.
- You can also continuously replicate your data with high availability (enable multi-AZ) and consolidate databases into a petabyte-scale data warehouse by streaming data to Amazon Redshift and Amazon S3.
- Continuous replication can be done from your data center to the databases in AWS or the reverse.
- Replication between on-premises to on-premises databases is not supported.
- The service provides an end-to-end view of the data replication process, including diagnostic and performance data for each point in the replication pipeline.
- Supports transaction commit date partitioning in CDC Mode when you select Amazon S3 as a target. You can write data from a single source table to a time-hierarchy folder structure in Amazon S3.
|
- Oracle
- Microsoft SQL Server non-Web and Express editions
- MySQL
- MariaDB
- PostgreSQL
- MongoDB
- SAP Adaptive Server Enterprise (ASE)
- IBM Db2 for Linux, UNIX, and Windows
- Azure SQL Database
- Amazon DocumentDB
- Amazon S3
| - Oracle
- Microsoft SQL Server non-Web and Express editions
- MySQL
- MariaDB
- PostgreSQL
- SAP Adaptive Server Enterprise (ASE)
- Amazon Aurora with MySQL or PostgreSQL compatibility
- Amazon Aurora Serverless
- Amazon Redshift
- Amazon S3
- Amazon DynamoDB
- Amazon Elasticsearch Service
- Amazon Kinesis Data Streams
- Amazon DocumentDB (with MongoDB compatibility)
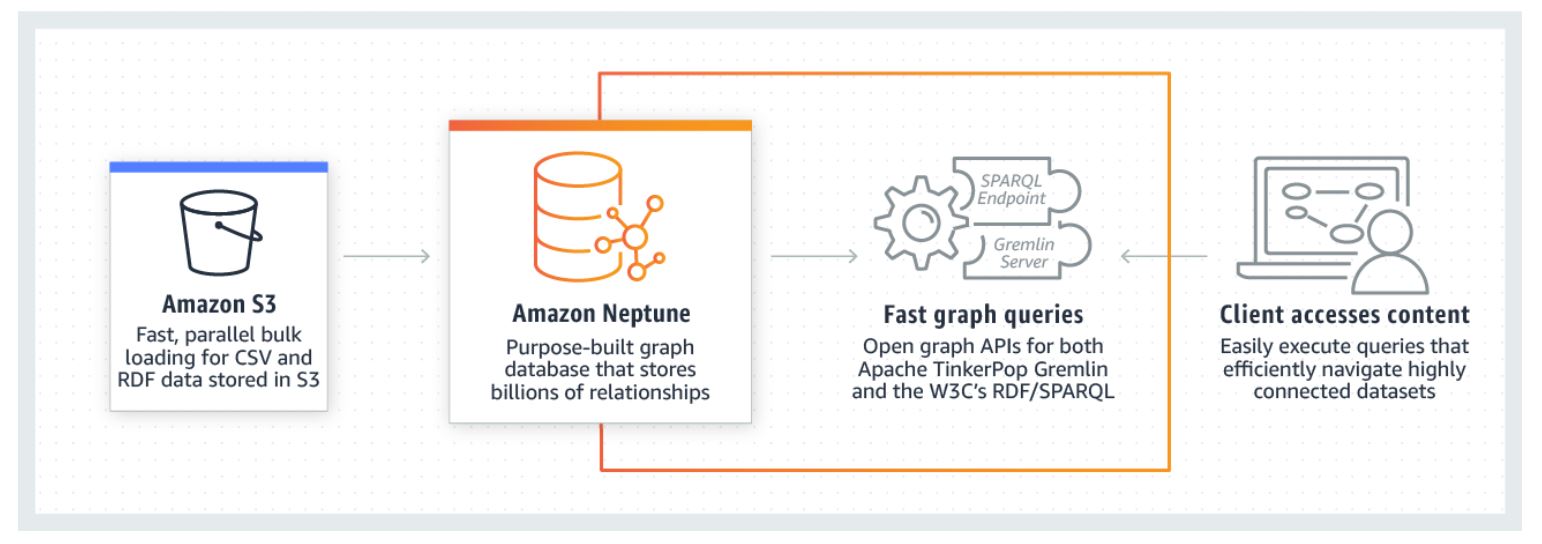
- Amazon Neptune
- Apache Kafka
|
AWS Schema Conversion Tool (SCT)
- The AWS Schema Conversion Tool makes heterogeneous database migrations predictable by automatically converting the source database schema and a majority of the database code objects, including views, stored procedures, and functions, to a format compatible with the target database.
- SCT can also scan your application source code for embedded SQL statements and convert them as part of a database schema conversion project.
- Supported migrations
|
| Microsoft SQL Server | Amazon Aurora with MySQL or PostgreSQL, MariaDB, Microsoft SQL Server, MySQL, PostgreSQL |
MySQL | Aurora PostgreSQL, MySQL, PostgreSQL You can migrate schema and data from MySQL to an Aurora MySQL DB cluster without using AWS SCT. |
Oracle Database | Aurora MySQL or PostgreSQL, MariaDB, MySQL, Oracle, PostgreSQL |
PostgreSQL | Aurora MySQL, MySQL, PostgreSQL, Aurora PostgreSQL |
| IBM Db2 LUW | Aurora MySQL, MariaDB, MySQL, PostgreSQL, Aurora PostgreSQL |
| Sybase ASE | Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
Oracle Data Warehouse, Microsoft SQL Server, Teradata, IBM Netezza, Greenplum, HPE Vertica | Amazon Redshift |
Apache Cassandra | Amazon DynamoDB |
Basic Schema Copy
- To quickly migrate a database schema to your target instance you can rely on the Basic Schema Copy feature of AWS Database Migration Service.
- Basic Schema Copy will automatically create tables and primary keys in the target instance if the target does not already contain tables with the same names.
- It will not migrate secondary indexes, foreign keys or stored procedures. When you need to use a more customizable schema migration process, use AWS SCT.
Pricing
- You only pay for the compute resources used during the migration process and any additional log storage. Each database migration instance includes storage sufficient for swap space, replication logs, and data cache for most replications and inbound data transfer is free.