Microsoft Certified Azure Data Engineer Associate | DP 203 | Step By Step Activity Guides (Hands-On Labs)
- Register For A Free Azure Cloud Account
- Explore Azure Synapse Analytics
- Query Files using a Serverless SQL Pool
- Transform files using a serverless SQL pool
- Analyze data in a lake database
- Analyze data in a data lake with Spark
- Transform data using Spark in Synapse Analytics
- Use Delta Lake with Spark in Azure Synapse Analytics
- Explore a relational data warehouse
- Load Data into a Relational Data Warehouse
- Build a data pipeline in Azure Synapse Analytics
- Use an Apache Spark notebook in a pipeline
- Use Azure Synapse Link for Azure Cosmos DB
- Use Azure Synapse Link for SQL
- Get started with Azure Stream Analytics
- Ingest realtime data with Azure Stream Analytics and Azure Synapse Analytics
- Create a real-time report with Azure Stream Analytics and Microsoft Power BI
- Use Microsoft Purview with Azure Synapse Analytics
- Explore Azure Databricks
- Use Spark in Azure Databricks
- Use Delta Lake in Azure Databricks
- Use a SQL Warehouse in Azure Databricks
- Automate an Azure Databricks Notebook with Azure Data Factory
- Real time-projects
1) Register For A Free Azure Cloud Account
Creating an Azure free account is one way to access Azure services. When you start using Azure with a free account, you get USD2001 credit to spend in the first 30 days after you sign up. In addition, you get free monthly amounts of two groups of services: popular services, which are free for 12 months, and more than 25 other services that are free always.
2) Explore Azure Synapse Analytics
In the competitive world of retail, staying ahead of the curve is essential. As the Sr. Data Engineer of a growing retail company called “Fashion Forward,” you’re faced with the challenge of making data-driven decisions in a rapidly changing market. To meet this challenge, you decide to explore Azure Synapse Analytics, a promising solution in the Azure ecosystem
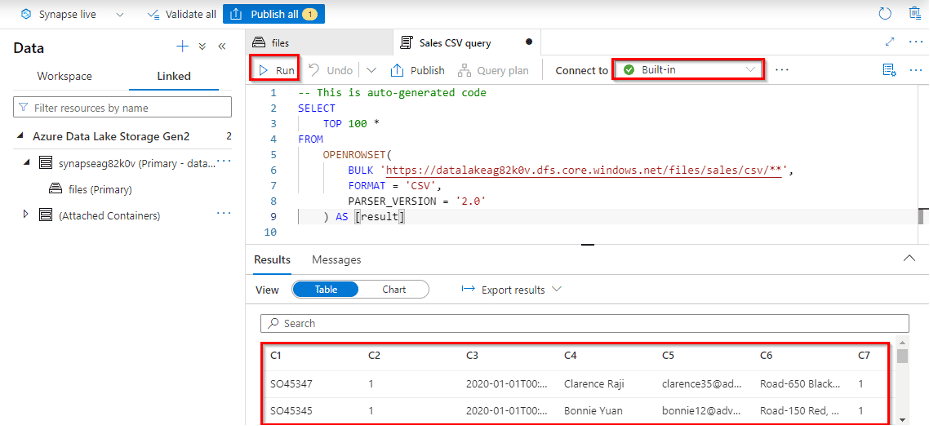
3) Query Files using a Serverless SQL Pool
In today’s data-driven business landscape, organizations rely heavily on data analysis to make informed decisions. As the Head of Data Analytics at “TechCo,” a rapidly expanding technology company, you are tasked with finding an efficient way to analyze large volumes of data without the complexities of managing infrastructure. To address this challenge, you decide to leverage Serverless SQL Pools within Azure Synapse Analytics for querying files and extracting valuable insights.
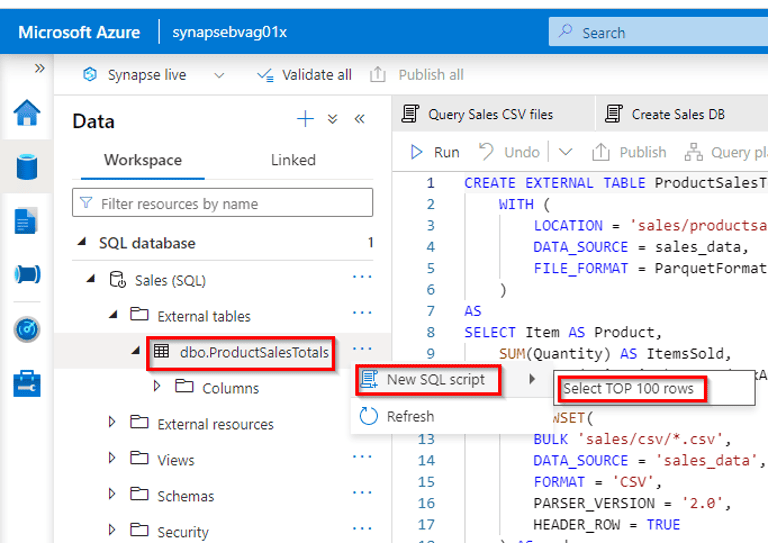
4) Transform files using a serverless SQL pool
In today’s data-centric business environment, organizations often face the challenge of efficiently transforming large volumes of data to extract valuable insights. As the Director of Data Engineering at “DataTech Solutions,” a data-focused company, you are tasked with finding a scalable and cost-effective solution for data transformation. To meet this challenge, you decide to utilize Serverless SQL Pool within Azure Synapse Analytics for transforming files and enhancing data quality.
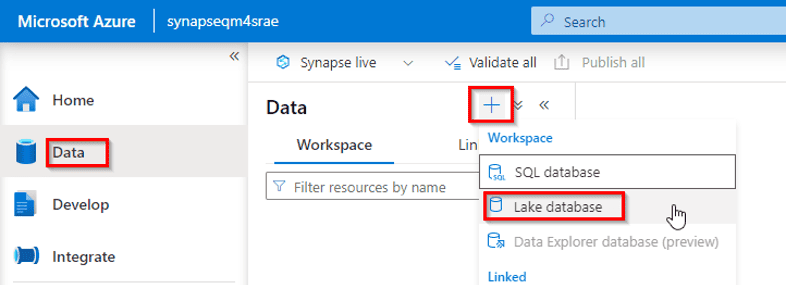
5) Analyze data in a lake database
In today’s data-driven business environment, organizations are continually looking for ways to harness the power of their data for insights and decision-making. As the Chief Analytics Officer (CAO) of a global retail conglomerate called “RetailX,” you recognize the importance of analyzing vast amounts of data stored in your data lake database. To derive valuable insights and drive data-centric strategies, you embark on a journey to analyze data in your data lake database.
6) Analyze data in a data lake with Spark
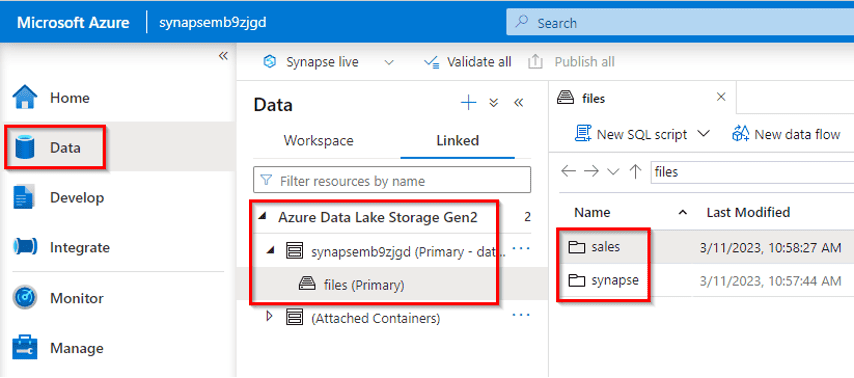
In today’s data-centric business landscape, organizations are continuously seeking ways to unlock the insights hidden within their vast repositories of data. As the Chief Data Officer (CDO) of “DataInsights Corp,” a leading data analytics company, you recognize the importance of harnessing the power of big data technologies. To extract valuable insights and drive data-centric strategies, you embark on a journey to analyze data in your data lake using Apache Spark.
7) Transform data using Spark in Synapse Analytics
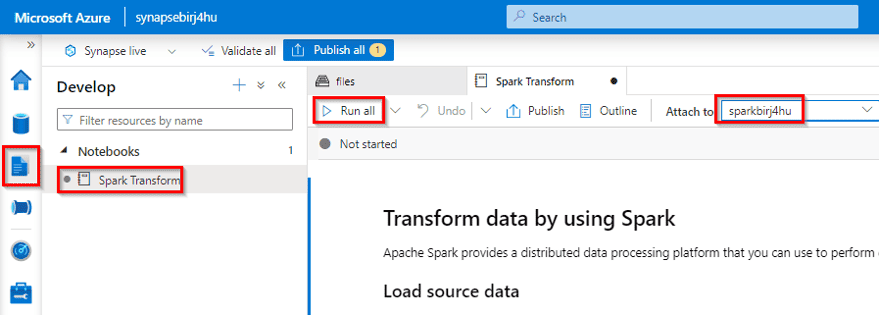
Data engineers often use Spark notebooks as one of their preferred tools to perform extract, transform, and load (ETL) or extract, load, and transform (ELT) activities that transform data from one format or structure to another
As the Chief Data Officer (CDO) of “TechSolutions Inc.,” a prominent technology firm, you recognize the importance of efficient data transformation. To address this need, you embark on a journey to transform data using Apache Spark within Azure Synapse Analytics, a powerful platform for data integration and analytics.
In this exercise, you’ll use a Spark notebook in Azure Synapse Analytics to transform data in files
8) Use Delta Lake with Spark in Azure Synapse Analytics
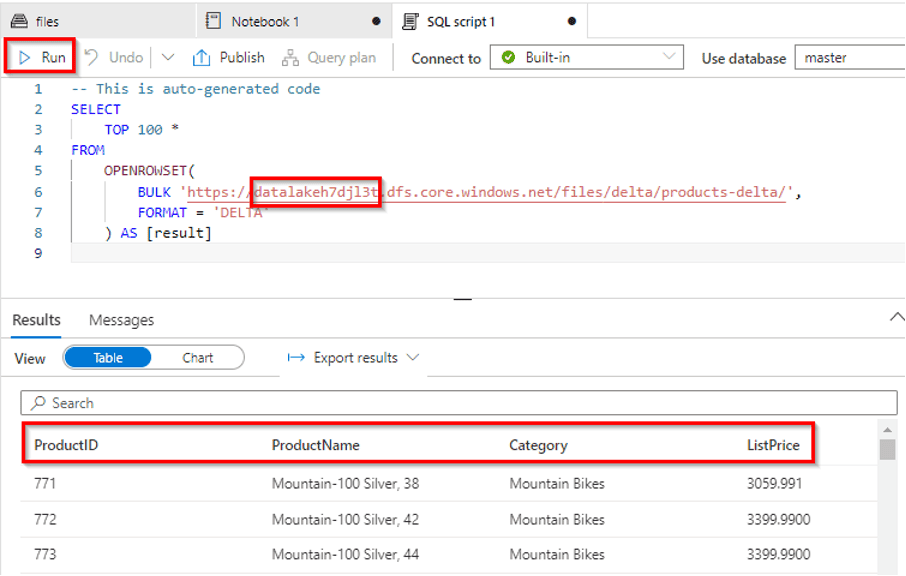
In the era of data-driven decision-making, companies are constantly seeking ways to improve data processing, storage, and analytics. As the Chief Data Officer (CDO) of a global financial institution named “FinTechCorp,” you face the challenge of managing vast volumes of financial data securely and efficiently. To address these needs, you decide to leverage Delta Lake with Spark within Azure Synapse Analytics, a powerful combination for modern data processing.
9) Explore a relational data warehouse
Azure Synapse Analytics is built on a scalable set capability to support enterprise data warehousing; including file-based data analytics in a data lake as well as large-scale relational data warehouses and the data transfer and transformation pipelines used to load them.
As the Data Engineer of “DataTech Enterprises,” a leading data-driven company, you recognize the importance of exploring a relational data warehouse to unlock valuable insights for informed decision-making and strategic planning.
In this lab, you’ll explore how to use a dedicated SQL pool in Azure Synapse Analytics to store and query data in a relational data warehouse.
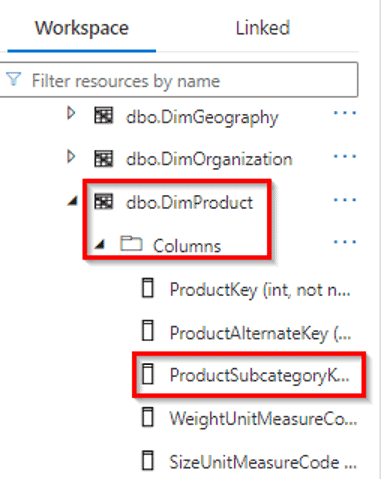
10) Load Data into a Relational Data Warehouse
Extract, Load, and Transform (ELT) is a process by which data is extracted from a source system, loaded into a dedicated SQL pool, and then transformed.
To centralize and manage data effectively, you initiate a project to load data into a relational data warehouse for comprehensive analytics.
In this exercise, you’re going to load data into a dedicated SQL Pool.
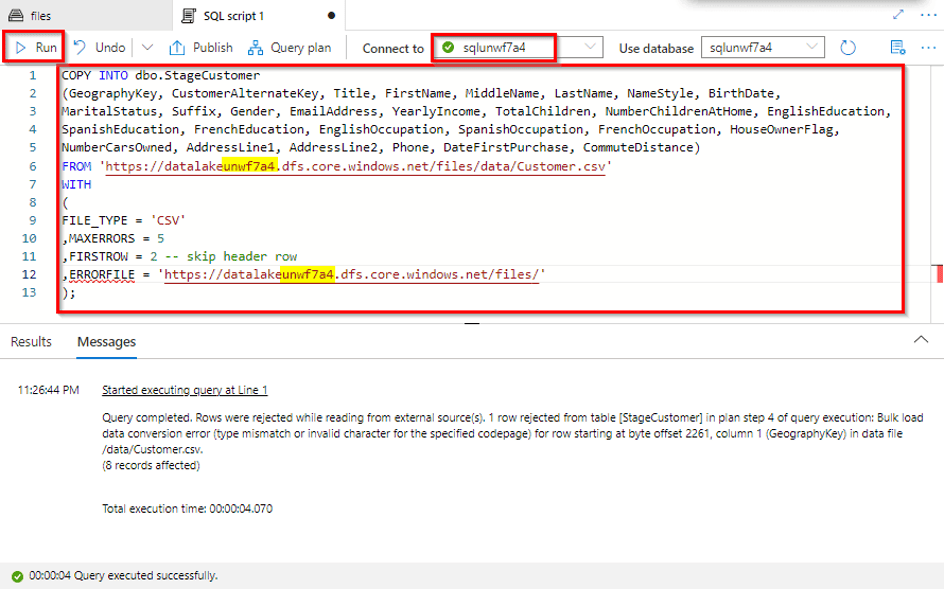
11) Build a data pipeline in Azure Synapse Analytics
In this exercise, you’ll load data into a dedicated SQL Pool using a pipeline in Azure Synapse Analytics Explorer. The pipeline will encapsulate a data flow that loads product data into a table in a data warehouse.
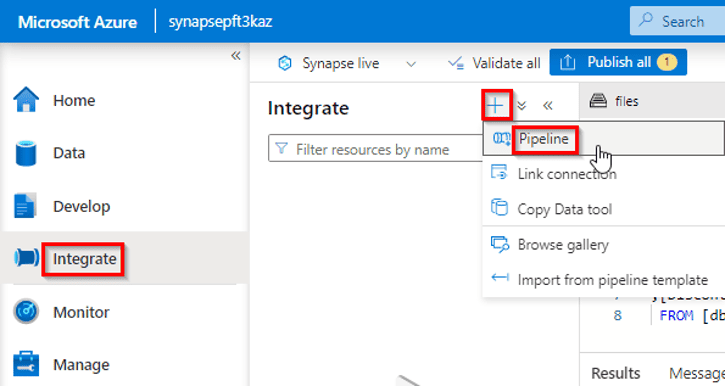
12) Use an Apache Spark notebook in a pipeline
The Synapse Notebook activity enables you to run data processing code in Spark notebooks as a task in a pipeline; making it possible to automate big data processing and integrate it into extract, transform, and load (ETL) workloads.
In this exercise, we’re going to create an Azure Synapse Analytics pipeline that includes an activity to run an Apache Spark notebook.
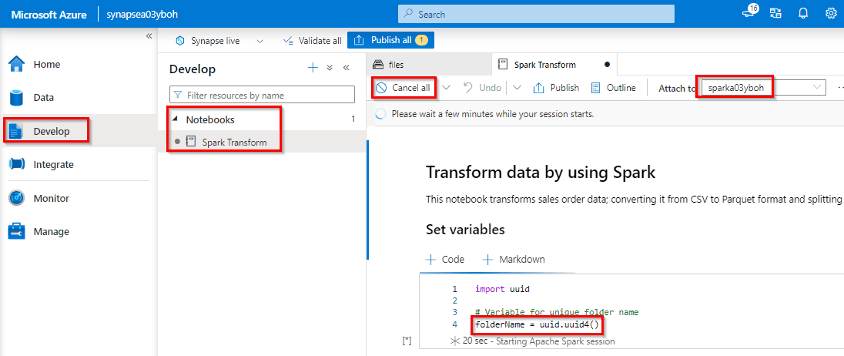
13) Use Azure Synapse Link for Azure Cosmos DB
As a Sr. Data Engineer of “CloudData Enterprises,” a forward-thinking technology company, you understand the importance of real-time data analytics. To meet this need, you initiate a project to leverage Azure Synapse Link for Azure Cosmos DB, a powerful solution for enhancing real-time analytics and decision-making.
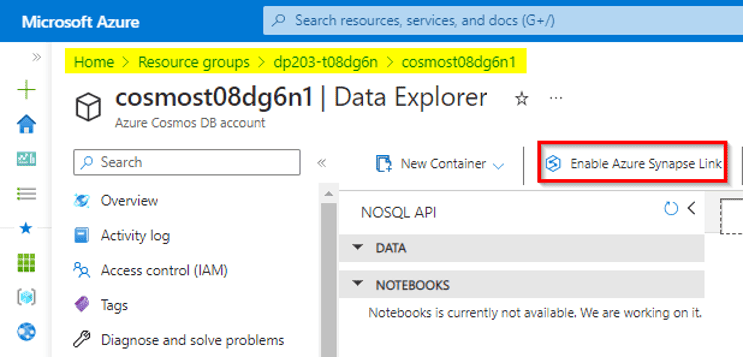
14) Use Azure Synapse Link for SQL
As the Data Engineer of “DataXcellence Corp,” a cutting-edge data-focused company, you recognize the importance of real-time analytics. To meet this need, you initiate a project to leverage Azure Synapse Link for SQL, a powerful solution that enables real-time access to data stored in Azure Synapse Analytics.
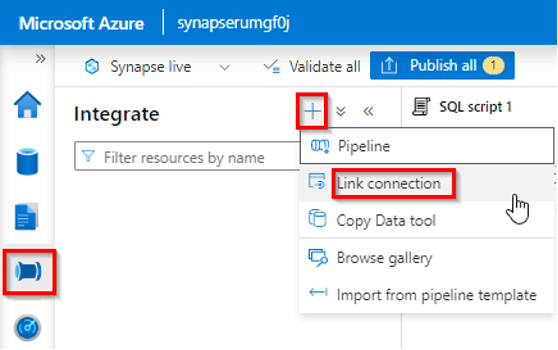
15) Get started with Azure Stream Analytics
In today’s fast-paced business environment, organizations need to harness the power of real-time data processing to gain actionable insights and respond swiftly to changing conditions. As the Data Engineer of “StreamTech Innovations,” a forward-thinking technology company, you recognize the importance of real-time analytics. To stay ahead in the market and drive data-driven strategies, you initiate a project to get started with Azure Stream Analytics, a powerful platform for processing and analyzing streaming data.
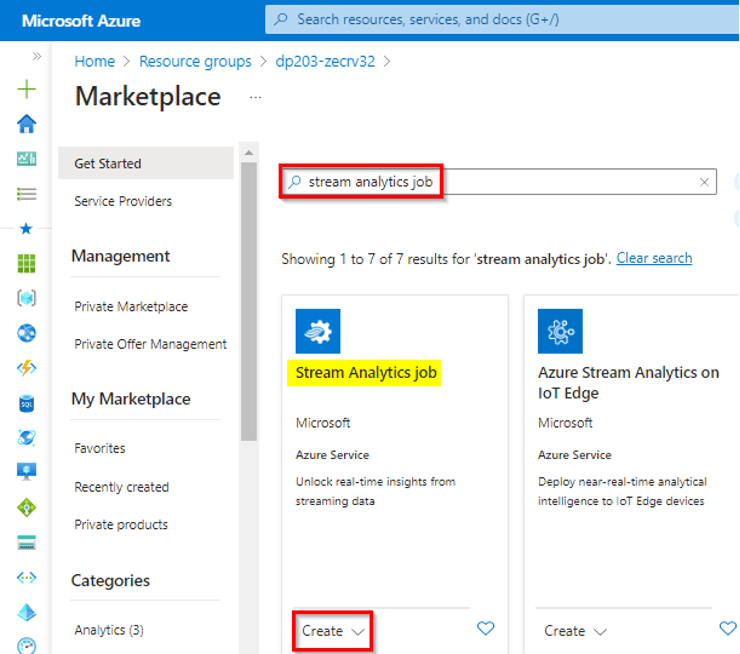
16) Ingest realtime data with Azure Stream Analytics and Azure Synapse Analytics
In this exercise, you’ll use Azure Stream Analytics to process a stream of sales order data, such as might be generated from an online retail application. The order data will be sent to Azure Event Hubs, from where your Azure Stream Analytics jobs will read the data and ingest it into Azure Synapse Analytics.
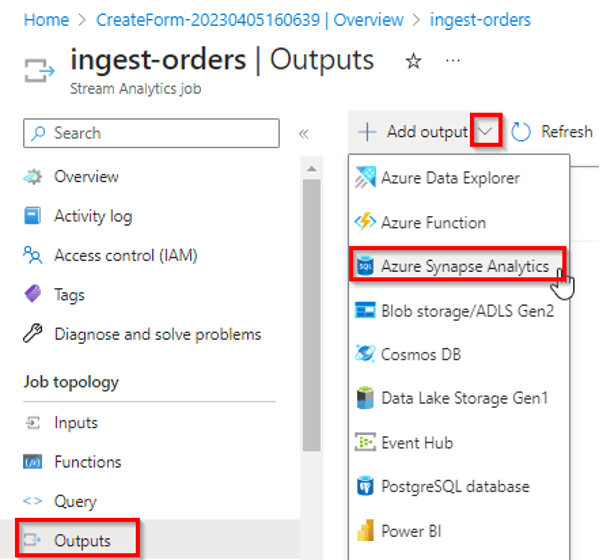
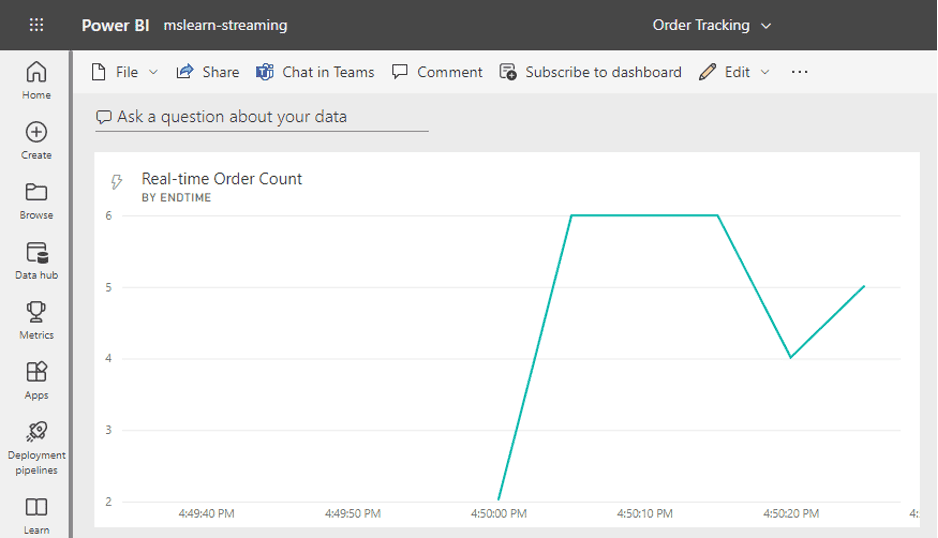
17) Create a real-time report with Azure Stream Analytics and Microsoft Power BI
In this exercise, you’ll use Azure Stream Analytics to process a stream of sales order data, such as might be generated from an online retail application. The order data will be sent to Azure Event Hubs, from where your Azure Stream Analytics job will read and summarize the data before sending it to Power BI, where you will visualize the data in a report.
18) Use Microsoft Purview with Azure Synapse Analytics
In today’s data-driven business landscape, organizations are constantly seeking ways to efficiently integrate and process data from various sources. As the Data Engineer of “DataTech Solutions,” a prominent data-focused company, you recognize the importance of a robust data pipeline to streamline data ingestion and transformation. To meet this need, you initiate a project to build a data pipeline in Azure Synapse Analytics, a powerful data integration and analytics platform.
19) Explore Azure Databricks
In today’s data-driven business landscape, organizations are constantly seeking ways to gain deeper insights from their data. As the Data Engineer of “TechInsights,” a dynamic technology company, you recognize the need for a robust platform to analyze and derive value from diverse datasets. To address this need, you decide to explore Azure Databricks, a powerful analytics platform that combines the best of Apache Spark with Azure cloud capabilities.
 20) Use Spark in Azure Databricks
20) Use Spark in Azure Databricks
In today’s data-driven landscape, organizations are continually seeking ways to unlock the insights hidden within their massive datasets. As the Data Engineer of “DataTech Enterprises,” a dynamic data-focused company, you recognize the importance of leveraging cutting-edge technologies for data analytics. To meet this demand, you decide to utilize Apache Spark within Azure Databricks, a high-performance analytics platform, to empower your data analytics team.
21) Use Delta Lake in Azure Databricks
In today’s data-driven world, organizations are continually seeking ways to streamline data management, improve data quality, and enhance analytics capabilities. As the Chief Technology Officer (CTO) of a fast-growing e-commerce company named “ShopifyX,” you’re faced with the challenge of managing and analyzing diverse data sources. To address these challenges, you decide to implement Delta Lake within Azure Databricks, a powerful combination for data lake management and analytics.
22) Use a SQL Warehouse in Azure Databricks
In today’s data-driven business landscape, organizations need to make informed decisions in real-time to stay competitive and responsive. As the Chief Data Officer (CDO) of “DataInsights Corp,” a forward-thinking data-driven company, you recognize the importance of real-time reporting and analytics. To empower your organization with immediate business insights, you initiate a project to create real-time reports using Azure Stream Analytics in conjunction with Microsoft Power BI, enabling real-time data visualization and decision-making.
23) Automate an Azure Databricks Notebook with Azure Data Factory
In today’s data-centric world, organizations rely on efficient data processing to extract insights and drive informed decision-making. As the Chief Data Officer (CDO) of “DataOps Solutions,” an innovative data-focused company, you understand the importance of automating data workflows. To enhance productivity and enable seamless data processing, you initiate a project to automate an Azure Databricks Notebook with Azure Data Factory, streamlining data transformation and analysis.
No comments:
Post a Comment