Match and Link Related Records from Multiple Applications and Data Stores
As organizations grow, the records that contain information about customers, businesses, or products tend to be increasingly fragmented and siloed across applications, channels, and data stores. Because information can be gathered in different ways, there is also the issue of different but equivalent data, such as for street addresses (“5th Avenue” and “5th Ave”). As a consequence, it’s not easy to link related records together to create a unified view and gain better insights.
For example, companies want to run advertising campaigns to reach consumers across multiple applications and channels with personalized messaging. Companies often have to deal with disparate data records that contain incomplete or conflicting information, creating a difficult matching process.
In the retail industry, companies have to reconcile, across their supply chain and stores, products that use multiple and different product codes, such as stock keeping units (SKUs), universal product codes (UPCs), or proprietary codes. This prevents them from analyzing information quickly and holistically.
One way to address this problem is to build bespoke data resolution solutions such as complex SQL queries interacting with multiple databases, or train machine learning (ML) models for record matching. But these solutions take months to build, require development resources, and are costly to maintain.
To help you with that, today we’re introducing AWS Entity Resolution, an ML-powered service that helps you match and link related records stored across multiple applications, channels, and data stores. You can get started in minutes configuring entity resolution workflows that are flexible, scalable, and can seamlessly connect to your existing applications.
AWS Entity Resolution offers advanced matching techniques, such as rule-based matching and machine learning models, to help you accurately link related sets of customer information, product codes, or business data codes. For example, you can use AWS Entity Resolution to create a unified view of your customer interactions by linking recent events (such as ad clicks, cart abandonment, and purchases) into a unique entity ID, or better track products that use different codes (like SKUs or UPCs) across your stores.
With AWS Entity Resolution, you can improve matching accuracy and protect data security while minimizing data movement because it reads records where they already live. Let’s see how that works in practice.
Using AWS Entity Resolution
As part of my analytics platform, I have a comma-separated values (CSV) file containing one million fictitious customers in an Amazon Simple Storage Service (Amazon S3) bucket. These customers come from a loyalty program but can have applied through different channels (online, in store, by post), so it’s possible that multiple records relate to the same customer.
This is the format of the data in the CSV file:
I use an AWS Glue crawler to automatically determine the content of the file and keep the metadata table updated in the data catalog so that it’s available for my analytics jobs. Now, I can use the same setup with AWS Entity Resolution.
In the AWS Entity Resolution console, I choose Get started to see how to set up a matching workflow.

To create a matching workflow, I first need to define my data with a schema mapping.

I choose Create schema mapping, enter a name and description, and select the option to import the schema from AWS Glue. I could also define a custom schema using a step-by-step flow or a JSON editor.
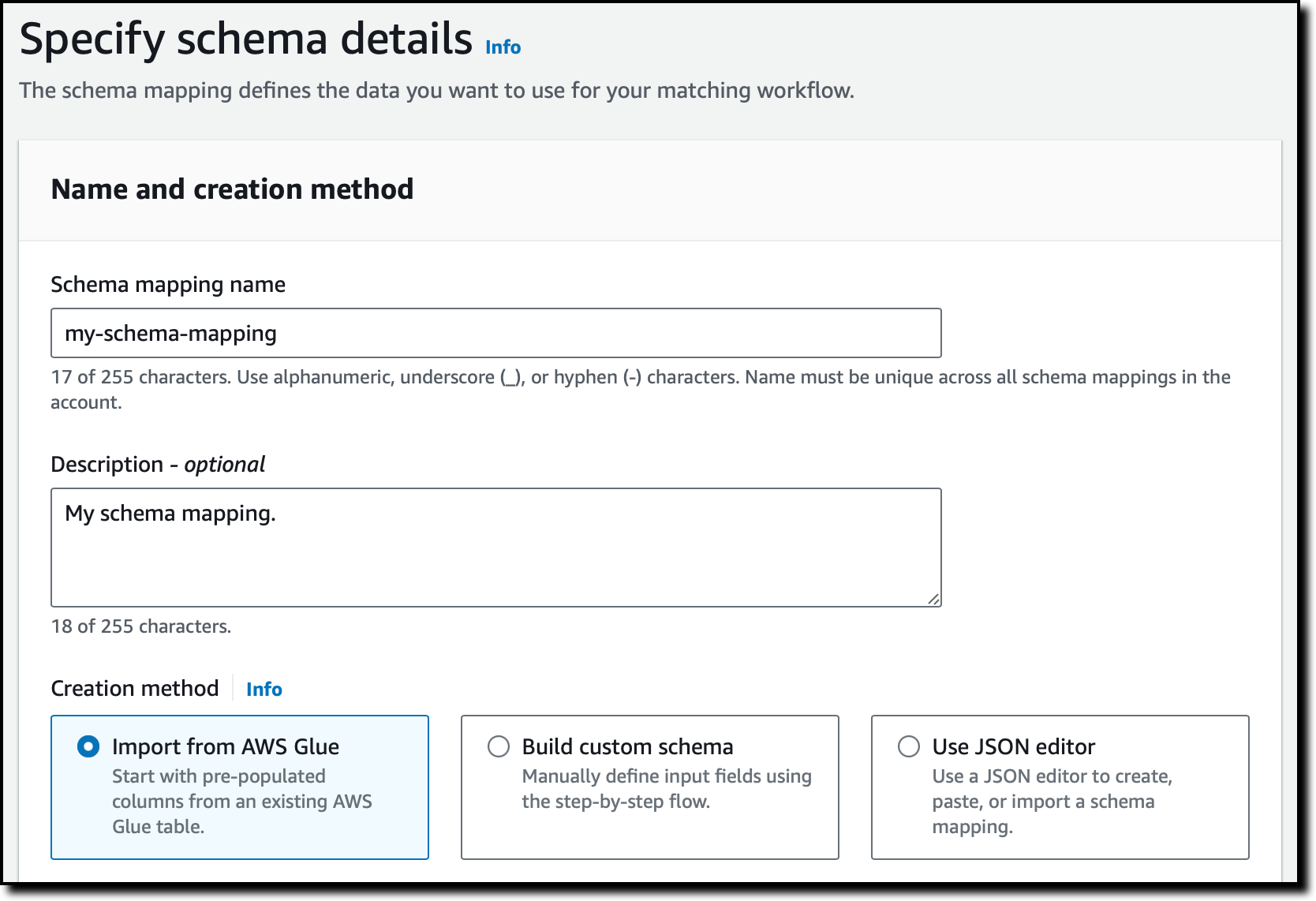
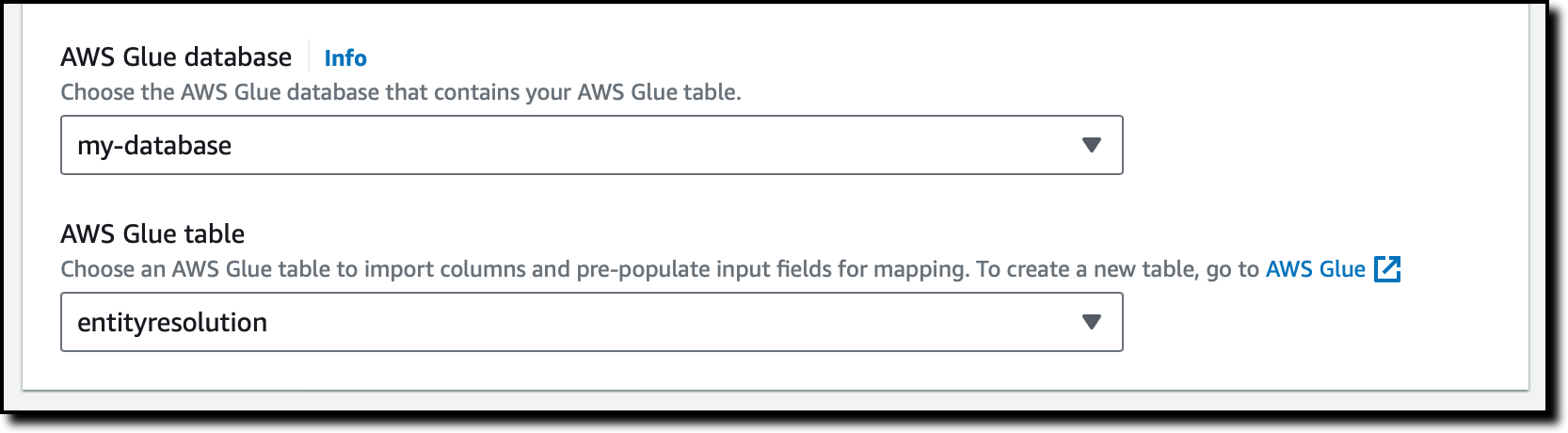
I select the AWS Glue database and table from the two dropdowns to import columns and pre-populate the input fields.
I select the Unique ID from the dropdown. The unique ID is the column that can distinctly reference each row of my data. In this case, it’s the loyalty_id in the CSV file.

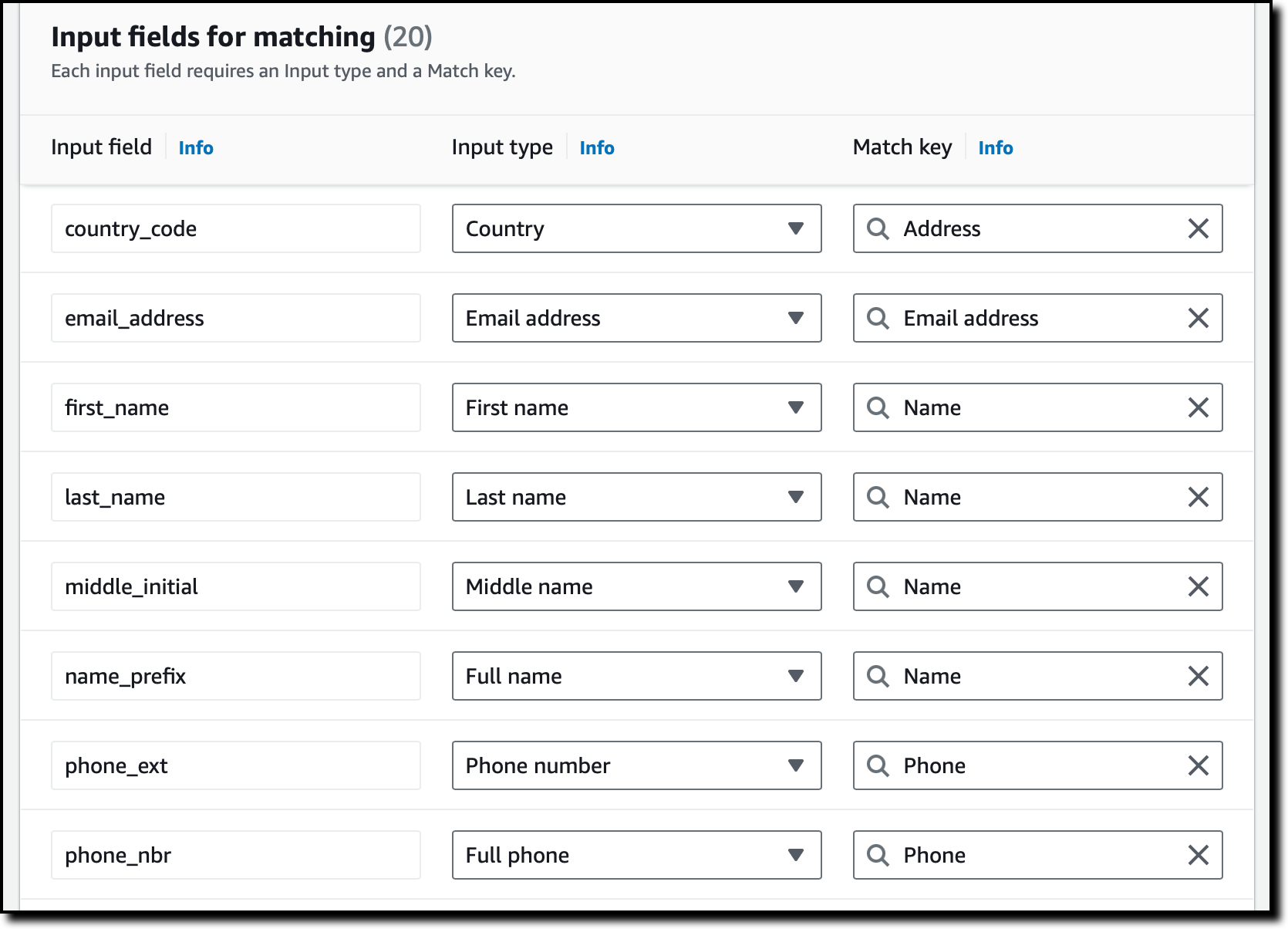
I select the input fields that are going to be used for matching. In this case, I choose the columns from the dropdown that can be used to recognize if multiple records are related to the same customer. If some columns aren’t required for matching but are required in the output file, I can optionally add them as pass-through fields. I choose Next.

I map the input fields to their input type and match key. In this way, AWS Entity Resolution knows how to use these fields to match similar records. To continue, I choose Next.
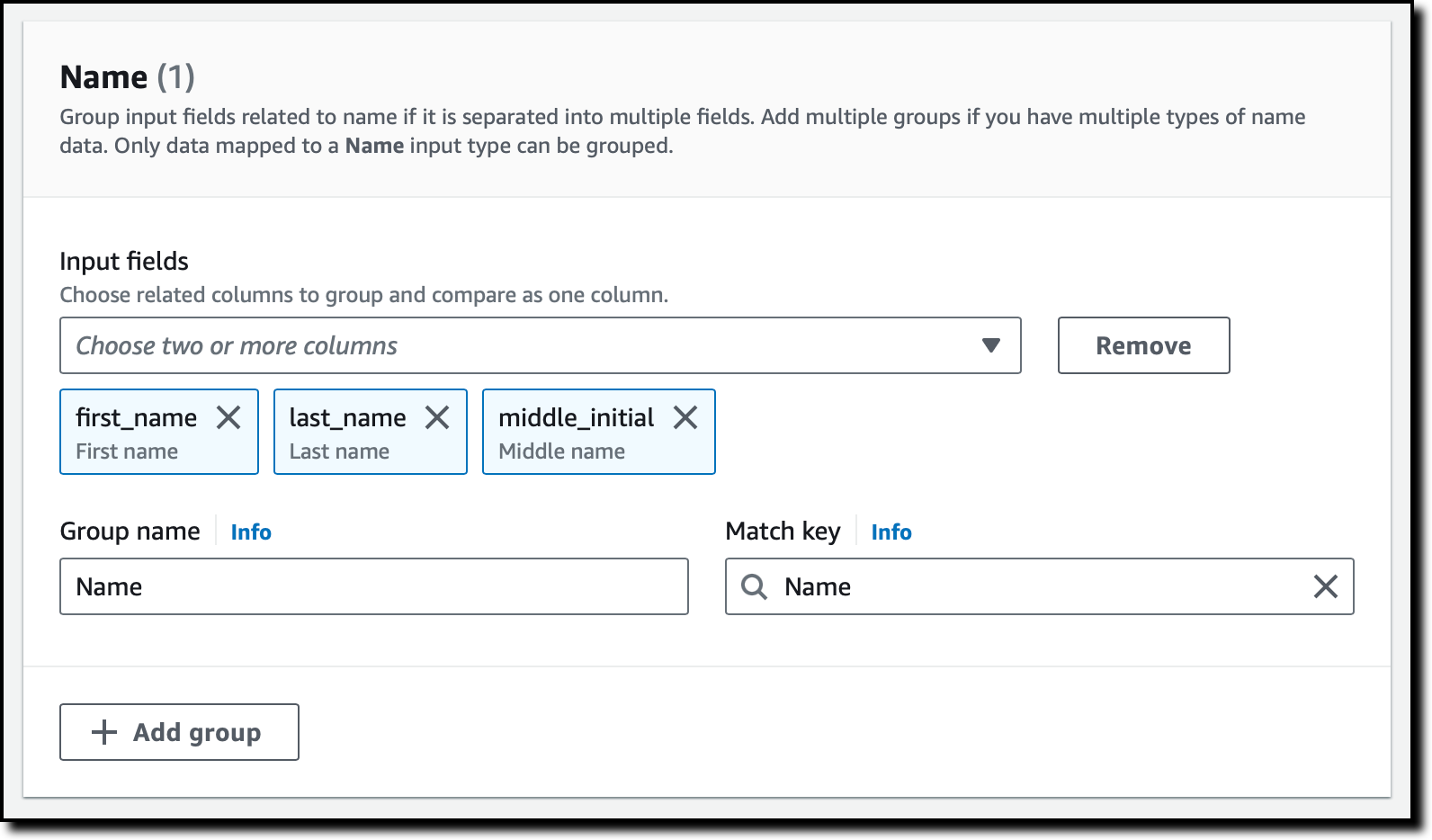
Now, I use grouping to better organize the data I need to compare. For example, the First name, Middle name, and Last name input fields can be grouped together and compared as a Full name.
I also create a group for the Address fields.
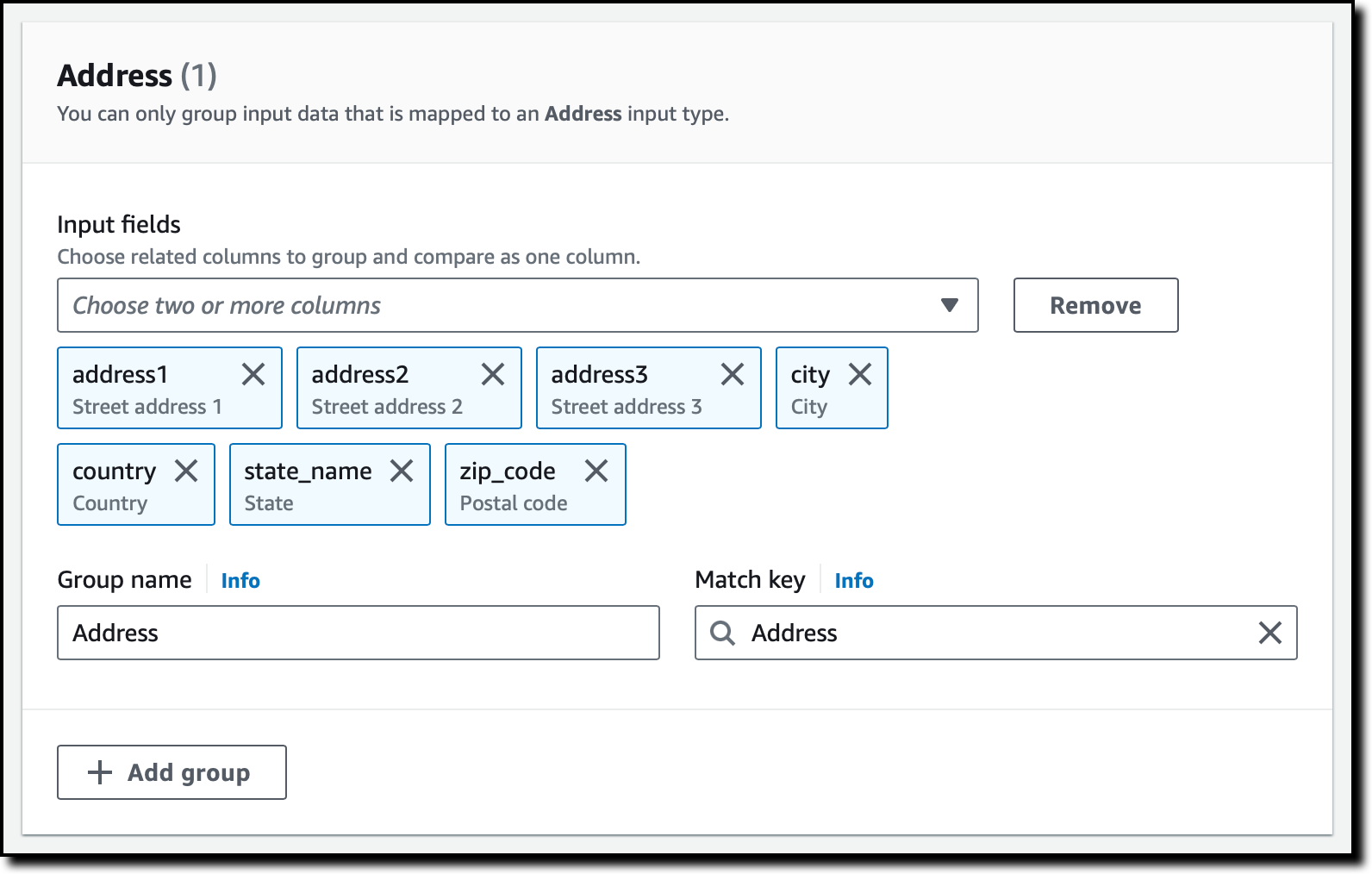
I choose Next and review all configurations. Then, I choose Create schema mapping.
Now that I’ve created the schema mapping, I choose Matching workflows from the navigation pane and then Create matching workflow.

I enter a name and a description. Then, to configure the input data, I select the AWS Glue database and table and the schema mapping.

To give the service access to the data, I select a service role that I configured previously. The service role gives access to the input and output S3 buckets and the AWS Glue database and table. If the input or output buckets are encrypted, the service role can also give access to the AWS Key Management Service (AWS KMS) keys needed to encrypt and decrypt the data. I choose Next.
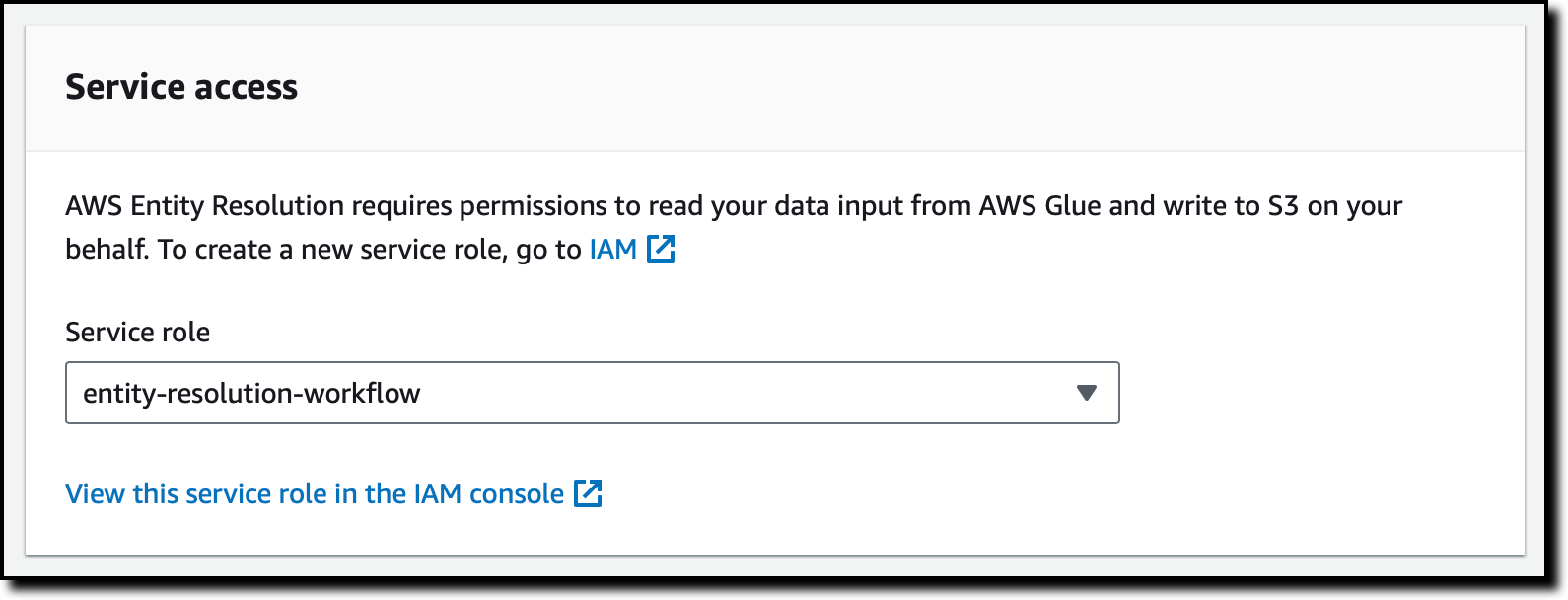
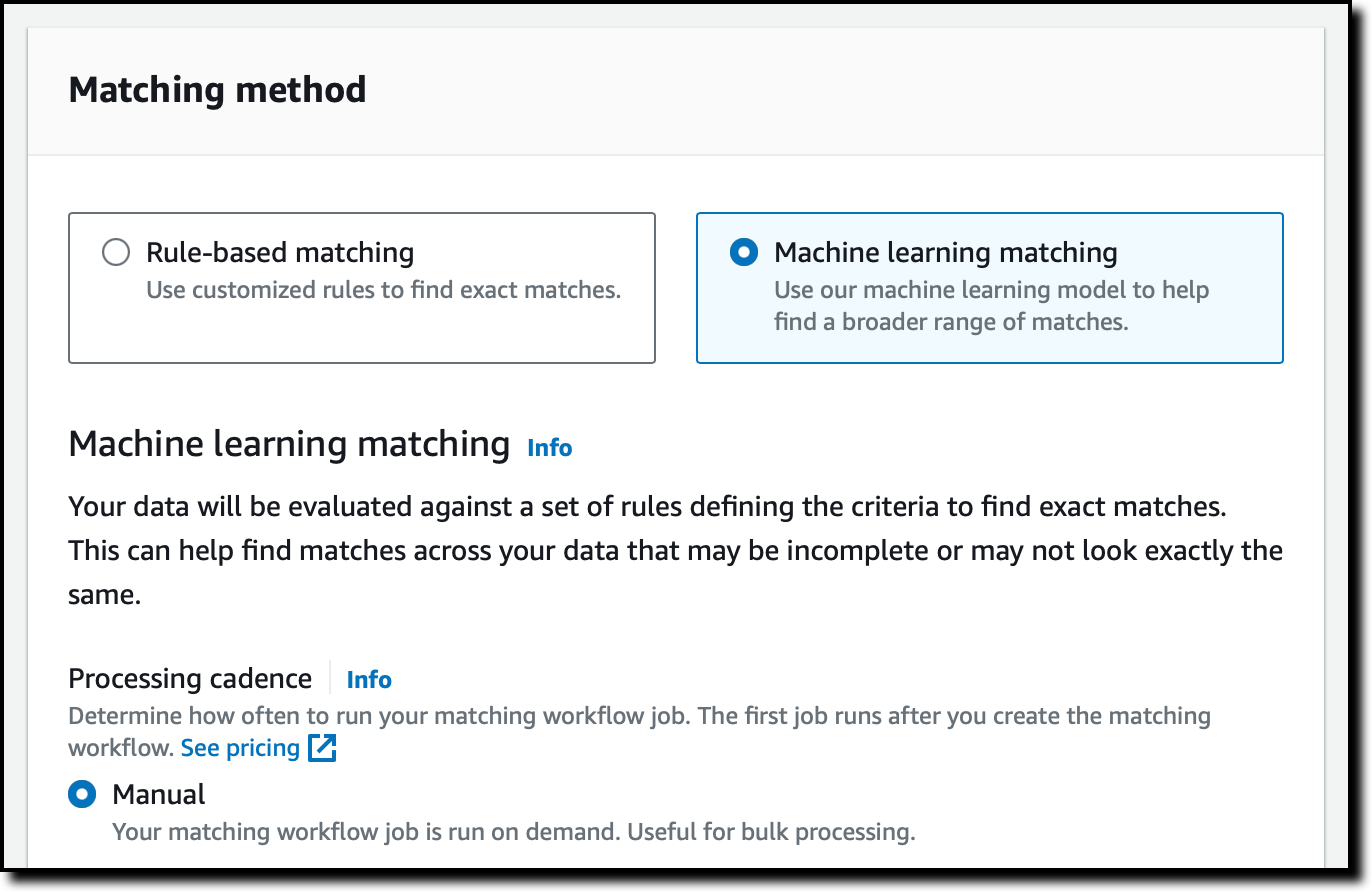
I have the option to use a rule-based or ML-powered matching method. Depending on the method, I can use a manual or automatic processing cadence to run the matching workflow job. For now, I select Machine learning matching and Manual for the Processing cadence, and then choose Next.
I configure an S3 bucket as the output destination. Under Data format, I select Normalized data so that special characters and extra spaces are removed, and data is formatted to lowercase.
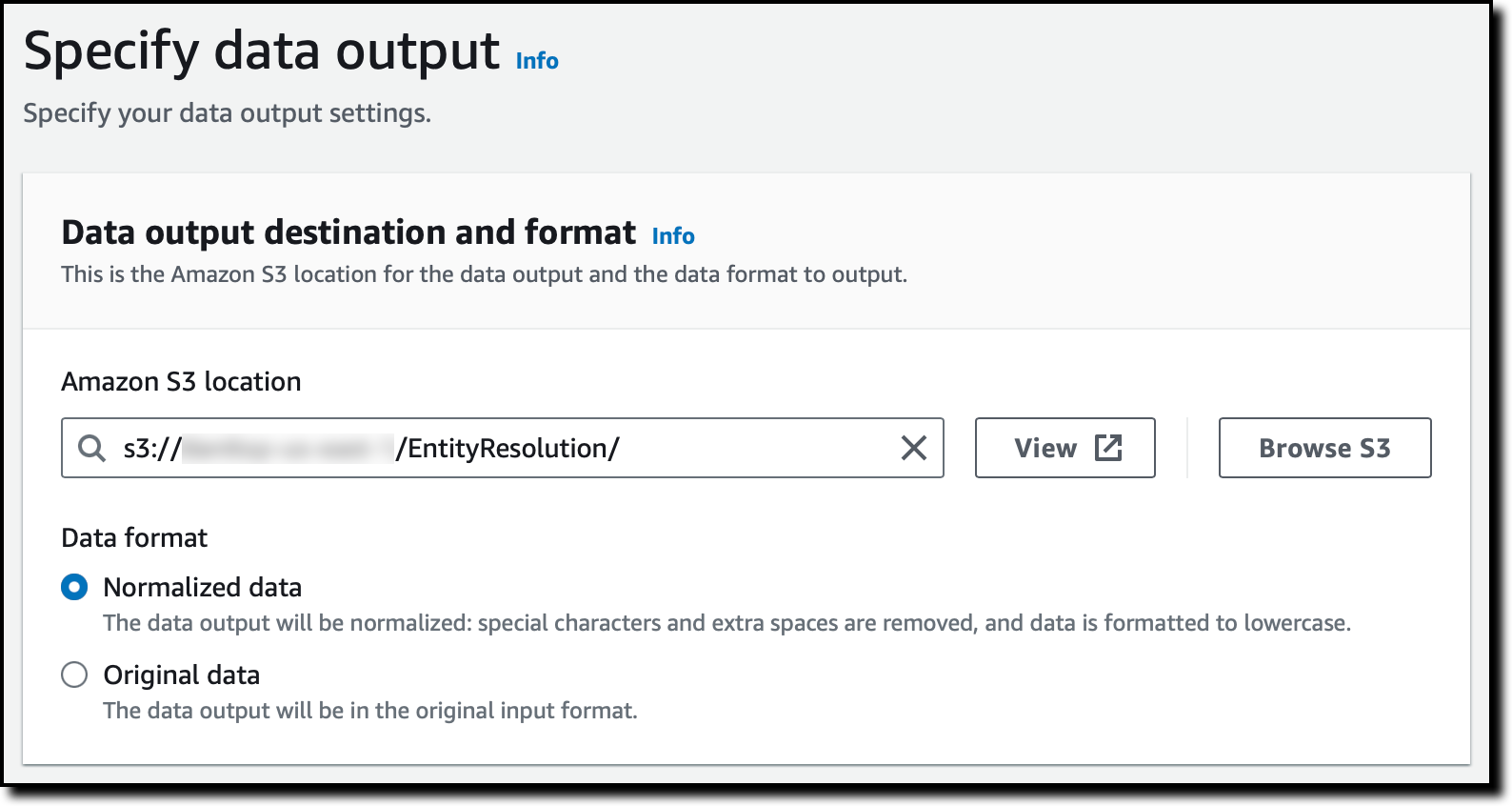
I use the default Encryption settings. For Data output, I use the default so that all input fields are included. For security, I can hide fields to exclude them from output or hash fields I want to mask. I choose Next.
I review all settings and choose Create and run to complete the creation of the matching workflow and run the job for the first time.
After a few minutes, the job completes. According to this analysis, of the 1 million records, only 835 thousand are unique customers. I choose View output in Amazon S3 to download the output files.

In the output files, each record has the original unique ID (loyalty_id in this case) and a newly assigned MatchID. Matching records, related to the same customers, have the same MatchID. The ConfidenceLevel field describes the confidence that machine learning matching has that the corresponding records are actually a match.
I can now use this information to have a better understanding of customers who are subscribed to the loyalty program.
Availability and Pricing
AWS Entity Resolution is generally available today in the following AWS Regions: US East (Ohio, N. Virginia), US West (Oregon), Asia Pacific (Seoul, Singapore, Sydney, Tokyo), and Europe (Frankfurt, Ireland, London).
With AWS Entity Resolution, you pay only for what you use based on the number of source records processed by your workflows. Pricing doesn’t depend on the matching method, whether it’s machine learning or rule-based record matching. For more information, see AWS Entity Resolution pricing.
No comments:
Post a Comment