Hadoop is a free, open-source and Java-based software framework used for storage and processing of large datasets on clusters of machines. It uses HDFS to store its data and process these data using MapReduce. It is an ecosystem of Big Data tools that are primarily used for data mining and machine learning. It has four major components such as Hadoop Common, HDFS, YARN, and MapReduce.
In this guide, we will explain how to install Apache Hadoop on RHEL/CentOS 8.
Step 1 – Disable SELinux
Before starting, it is a good idea to disable the SELinux in your system.
To disable SELinux, open the /etc/selinux/config file:
Change the following line:
Save the file when you are finished. Next, restart your system to apply the SELinux changes.
Step 2 – Install Java
Hadoop is written in Java and supports only Java version 8. You can install OpenJDK 8 and ant using DNF command as shown below:
Once installed, verify the installed version of Java with the following command:
You should get the following output:
Step 3 – Create a Hadoop User
It is a good idea to create a separate user to run Hadoop for security reasons.
Run the following command to create a new user with name hadoop:
Next, set the password for this user with the following command:
Provide and confirm the new password as shown below:
Step 4 – Configure SSH Key-based Authentication
Next, you will need to configure passwordless SSH authentication for the local system.
First, change the user to hadoop with the following command:
Next, run the following command to generate Public and Private Key Pairs:
You will be asked to enter the filename. Just press Enter to complete the process:
Next, append the generated public keys from id_rsa.pub to authorized_keys and set proper permission:
Next, verify the passwordless SSH authentication with the following command:
You will be asked to authenticate hosts by adding RSA keys to known hosts. Type yes and hit Enter to authenticate the localhost:
Step 5 – Install Hadoop
First, change the user to hadoop with the following command:
Next, download the latest version of Hadoop using the wget command:
Once downloaded, extract the downloaded file:
Next, rename the extracted directory to hadoop:
Next, you will need to configure Hadoop and Java Environment Variables on your system.
Open the ~/.bashrc file in your favorite text editor:
Append the following lines:
Save and close the file. Then, activate the environment variables with the following command:
Next, open the Hadoop environment variable file:
Update the JAVA_HOME variable as per your Java installation path:
Save and close the file when you are finished.
Step 6 – Configure Hadoop
First, you will need to create the namenode and datanode directories inside Hadoop home directory:
Run the following command to create both directories:
Next, edit the core-site.xml file and update with your system hostname:
Change the following name as per your system hostname:
Save and close the file. Then, edit the hdfs-site.xml file:
Change the NameNode and DataNode directory path as shown below:
Save and close the file. Then, edit the mapred-site.xml file:
Make the following changes:
Save and close the file. Then, edit the yarn-site.xml file:
Make the following changes:
Save and close the file when you are finished.
Step 7 – Start Hadoop Cluster
Before starting the Hadoop cluster. You will need to format the Namenode as a hadoop user.
Run the following command to format the hadoop Namenode:
You should get the following output:
After formating the Namenode, run the following command to start the hadoop cluster:
Once the HDFS started successfully, you should get the following output:
Next, start the YARN service as shown below:
You should get the following output:
You can now check the status of all Hadoop services using the jps command:
You should see all the running services in the following output:
Step 8 – Configure Firewall
Hadoop is now started and listening on port 9870 and 8088. Next, you will need to allow these ports through the firewall.
Run the following command to allow Hadoop connections through the firewall:
Next, reload the firewalld service to apply the changes:
Step 9 – Access Hadoop Namenode and Resource Manager
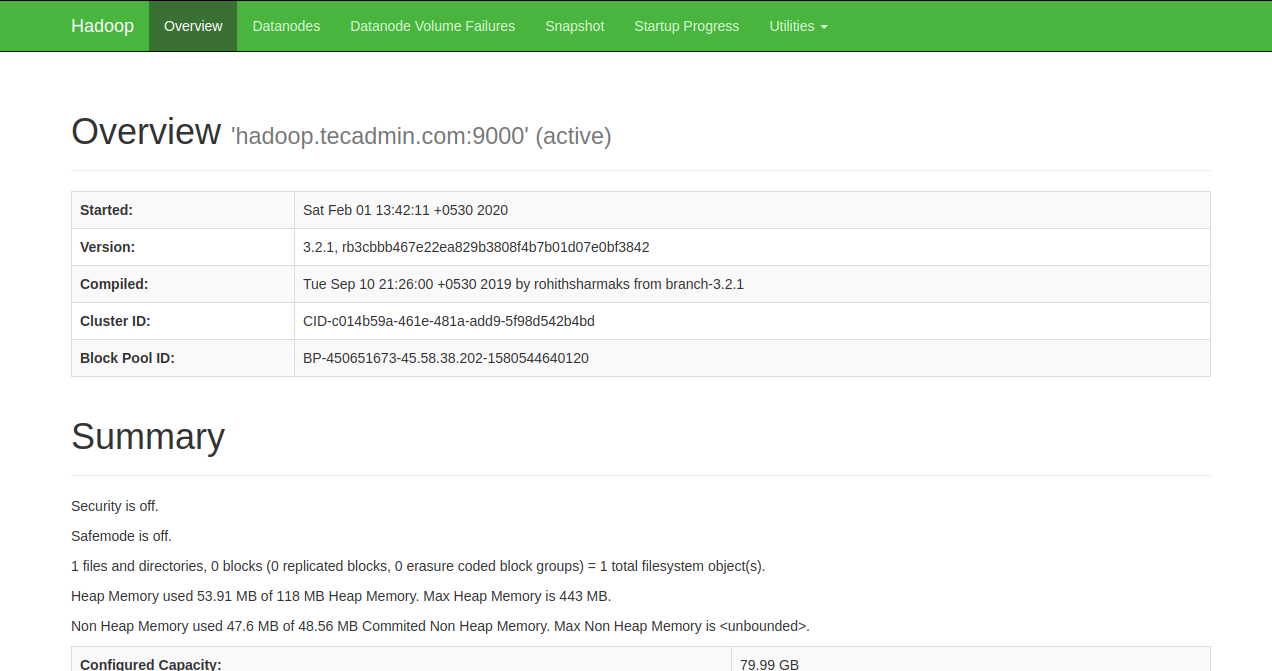
To access the Namenode, open your web browser and visit the URL http://your-server-ip:9870. You should see the following screen:
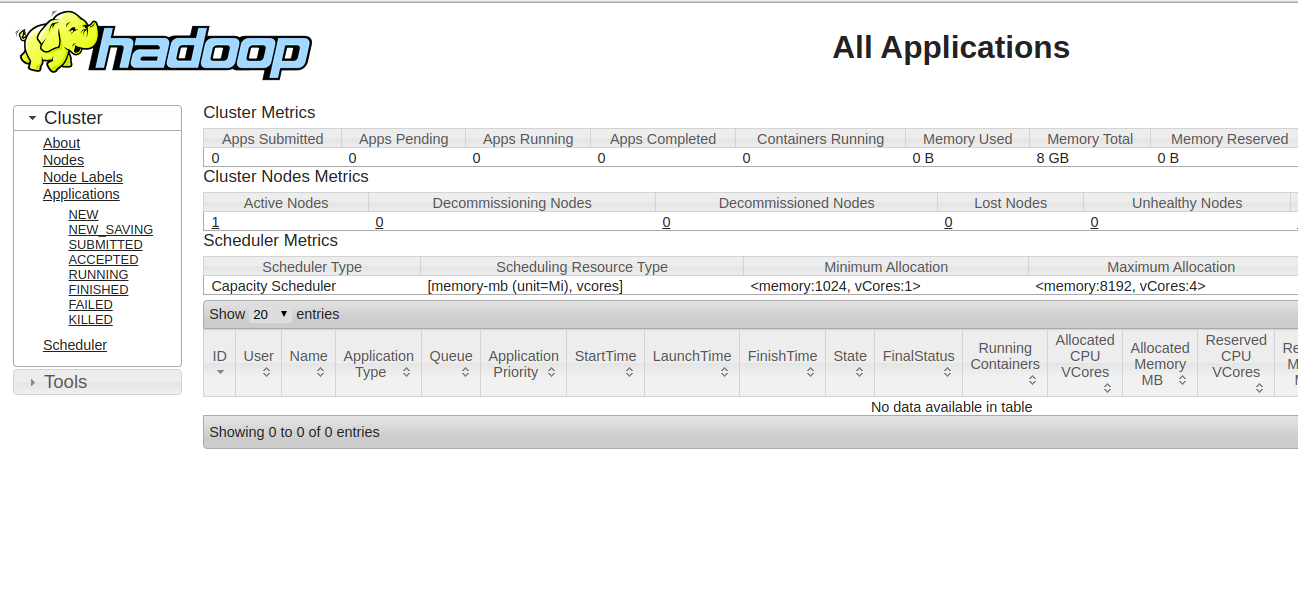
To access the Resource Manage, open your web browser and visit the URL http://your-server-ip:8088. You should see the following screen:
Step 10 – Verify the Hadoop Cluster
At this point, the Hadoop cluster is installed and configured. Next, we will create some directories in HDFS filesystem to test the Hadoop.
Let’s create some directory in the HDFS filesystem using the following command:
Next, run the following command to list the above directory:
You should get the following output:
You can also verify the above directory in the Hadoop Namenode web interface.
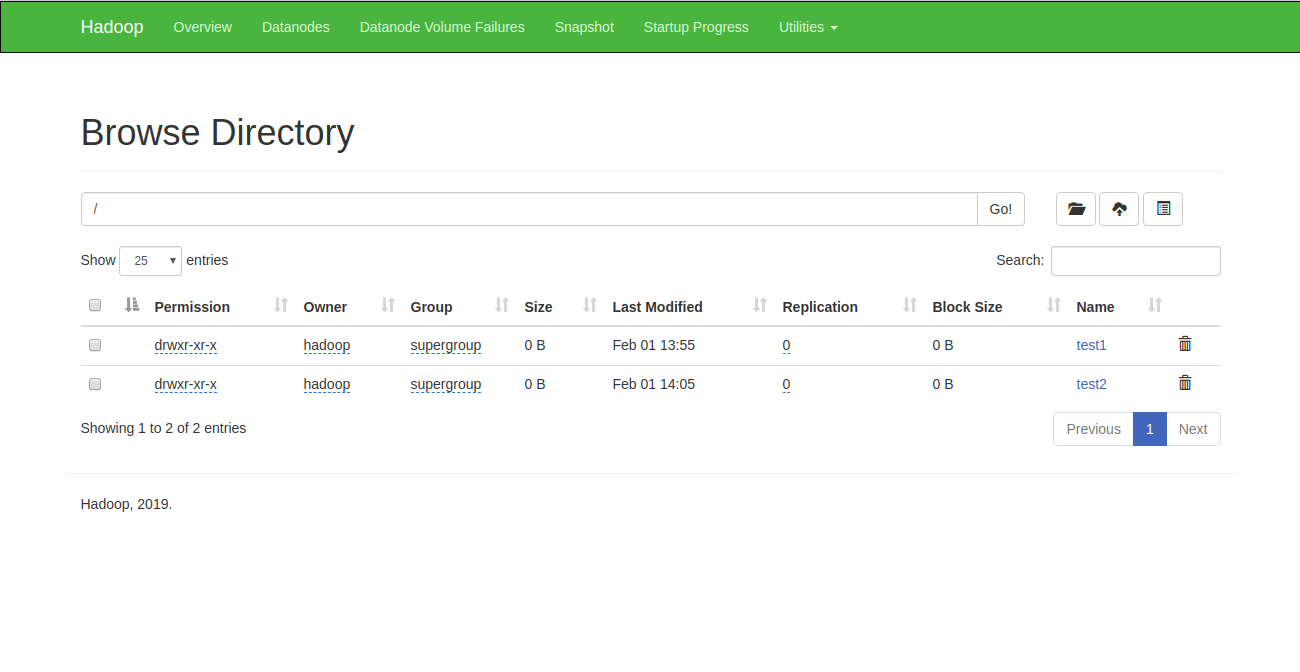
Go to the Namenode web interface, click on the Utilities => Browse the file system. You should see your directories which you have created earlier in the following screen:
Step 11 – Stop Hadoop Cluster
You can also stop the Hadoop Namenode and Yarn service any time by running the stop-dfs.sh and stop-yarn.sh script as a Hadoop user.
To stop the Hadoop Namenode service, run the following command as a hadoop user:
To stop the Hadoop Resource Manager service, run the following command:
Conclusion
In the above tutorial, you learned how to set up the Hadoop single node cluster on CentOS 8. I hope you have now enough knowledge to install the Hadoop in the production environment.
No comments:
Post a Comment