What is Redshift?
- Redshift is a fast and powerful, fully managed, petabyte-scale data warehouse service in the cloud.
- Customers can use the Redshift for just $0.25 per hour with no commitments or upfront costs and scale to a petabyte or more for $1,000 per terabyte per year.
- Sum of Radios sold in EMEA.
- Sum of Radios sold in Pacific.
- Unit cost of radio in each region.
- Sales price of each radio
- Sales price - unit cost
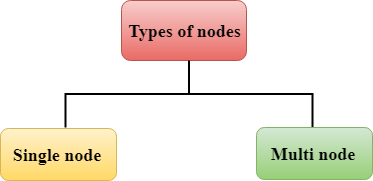
- Single node
- Multi-node
- Leader Node
- It manages the client connections and receives queries. A leader node receives the queries from the client applications, parses the queries, and develops the execution plans. It coordinates with the parallel execution of these plans with the compute node and combines the intermediate results of all the nodes, and then return the final result to the client application.
- Compute Node
- A compute node executes the execution plans, and then intermediate results are sent to the leader node for aggregation before sending back to the client application. It can have up to 128 compute nodes.
OLAP
OLAP is an Online Analytics Processing System used by the Redshift.
OLAP transaction Example:
Suppose we want to calculate the Net profit for EMEA and Pacific for the Digital Radio Product. This requires to pull a large number of records. Following are the records required to calculate a Net Profit:
The complex queries are required to fetch the records given above. Data Warehousing databases use different type architecture both from a database perspective and infrastructure layer.
Redshift consists of two types of nodes:
Single node: A single node stores up to 160 GB.
Multi-node: Multi-node is a node that consists of more than one node. It is of two types:
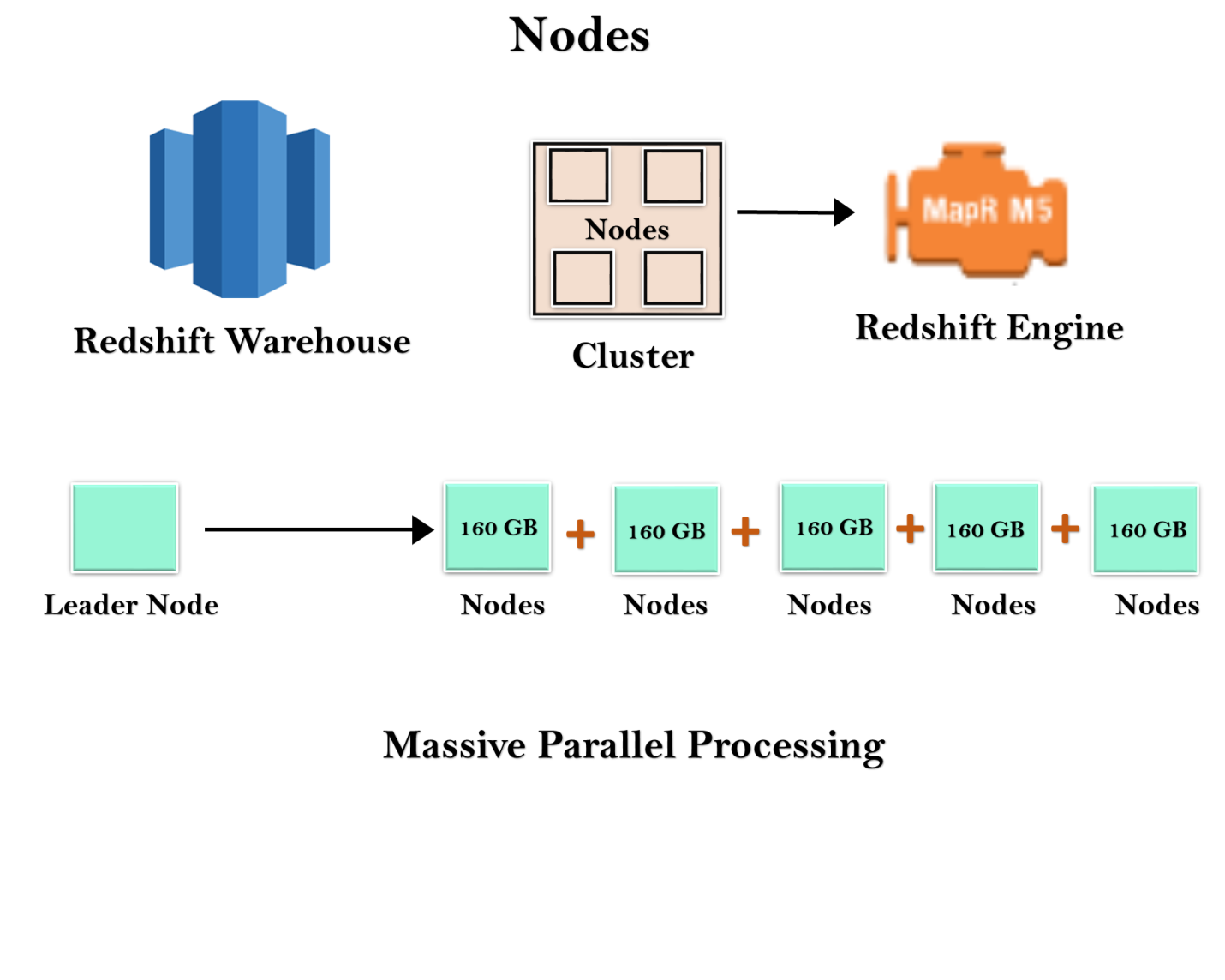
Let's understand the concept of leader node and compute nodes through an example.
Redshift warehouse is a collection of computing resources known as nodes, and these nodes are organized in a group known as a cluster. Each cluster runs in a Redshift Engine which contains one or more databases.
When you launch a Redshift instance, it starts with a single node of size 160 GB. When you want to grow, you can add additional nodes to take advantage of parallel processing. You have a leader node that manages the multiple nodes. Leader node handles the client connection as well as compute nodes. It stores the data in compute nodes and performs the query.
Why Redshift is 10 times faster
Redshift is 10 times faster because of the following reasons:
- Columnar Data Storage
Instead of storing data as a series of rows, Amazon Redshift organizes the data by column. Row-based systems are ideal for transaction processing while column-based systems are ideal for data warehousing and analytics, where queries often involve aggregates performed over large data sets. Since only the columns involved in the queries are processed and columnar data is stored in a storage media sequentially, column-based systems require fewer I/Os, thus, improving query performance. - Advanced Compression
Columnar data stores can be compressed much more than row-based data stores because similar data is stored sequentially on disk. Amazon Redshift employs multiple compression techniques and can often achieve significant compression relative to traditional relation data stores.
Amazon Redshift does not require indexes or materialized views so, it requires less space than traditional relational database systems. When loading a data into an empty table, Amazon Redshift samples your data automatically and selects the most appropriate compression technique. - Massively Parallel Processing
Amazon Redshift automatically distributes the data and loads the query across various nodes. An Amazon Redshift makes it easy to add new nodes to your data warehouse, and this allows us to achieve faster query performance as your data warehouse grows.
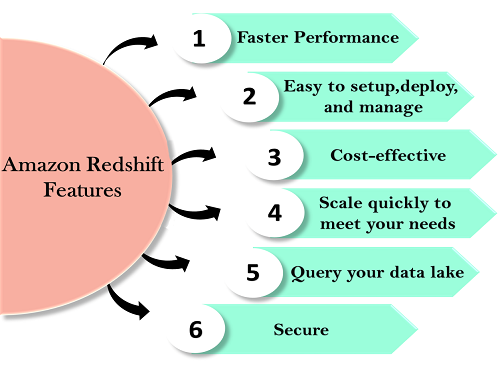
Redshift features
Features of Redshift are given below:
- Easy to setup, deploy and manage
- Automated Provisioning
Redshift is simple to set up and operate. You can deploy a new data warehouse with just a few clicks in the AWS Console, and Redshift automatically provisions the infrastructure for you. In AWS, all the administrative tasks are automated, such as backups and replication, you need to focus on your data, not on the administration. - Automated backups
Redshift automatically backups your data to S3. You can also replicate the snapshots in S3 in another region for any disaster recovery.
- Automated Provisioning
- Cost-effective
- No upfront costs, pay as you go
Amazon Redshift is the most cost-effective data warehouse service as you need to pay only for what you use.
Its costs start with $0.25 per hour with no commitment and no upfront costs and can scale out to $250 per terabyte per year.
Amazon Redshift is the only data warehouse service that offers On Demand pricing with no up-front costs, and it also offers Reserved instance pricing that saves up to 75% by providing 1-3 year term. - Choose your node type.
You can choose either of the two nodes to optimize the Redshift.- Dense compute node
Dense compute node can create a high-performance data warehouses by using fast CPUs, a large amount of RAM, and solid-state disks. - Dense storage node
If you want to reduce the cost, then you can use Dense storage node. It creates a cost-effective data warehouse by using a larger hard disk drive.
- Dense compute node
- No upfront costs, pay as you go
- Scale quickly to meet your needs.
- Petabyte-scale data warehousing
Amazon Redshift automatically scales up or down the nodes according to the need changes. With just a few clicks in the AWS Console or a single API call can easily change the number of nodes in a data warehouse. - Exabyte-scale data lake analytics
It is a feature of Redshift that allows you to run the queries against exabytes of data in Amazon S3. Amazon S3 is a secure and cost-effective data to store unlimited data in an open format. - Limitless concurrency
It is a feature of Redshift means that the multiple queries can access the same data in Amazon S3. It allows you to run the queries across the multiple nodes regardless of the complexity of a query or the amount of data.
- Petabyte-scale data warehousing
- Query your data lake
Amazon Redshift is the only data warehouse which is used to query the Amazon S3 data lake without loading data. This provides flexibility by storing the frequently accessed data in Redshift and unstructured or infrequently accessed data in Amazon S3. - Secure
With a couple of parameter settings, you can set the Redshift to use SSL to secure your data. You can also enable encryption, all the data written to disk will be encrypted. - Faster performance
Amazon Redshift provides columnar data storage, compression, and parallel processing to reduce the amount of I/O needed to perform queries. This improves query performance.