Virtual machine and disk performance
How does disk performance work?
Azure virtual machines have input/output operations per second (IOPS) and throughput performance limits based on the virtual machine type and size. OS disks and data disks can be attached to virtual machines. The disks have their own IOPS and throughput limits.
Your application's performance gets capped when it requests more IOPS or throughput than what is allotted for the virtual machines or attached disks. When capped, the application experiences suboptimal performance. This can lead to negative consequences like increased latency. Let's run through a couple of examples to clarify this concept. To make these examples easy to follow, we'll only look at IOPS. But, the same logic applies to throughput.
Disk IO capping
Setup:
- Standard_D8s_v3
- Uncached IOPS: 12,800
- E30 OS disk
- IOPS: 500
- Two E30 data disks × 2
- IOPS: 500
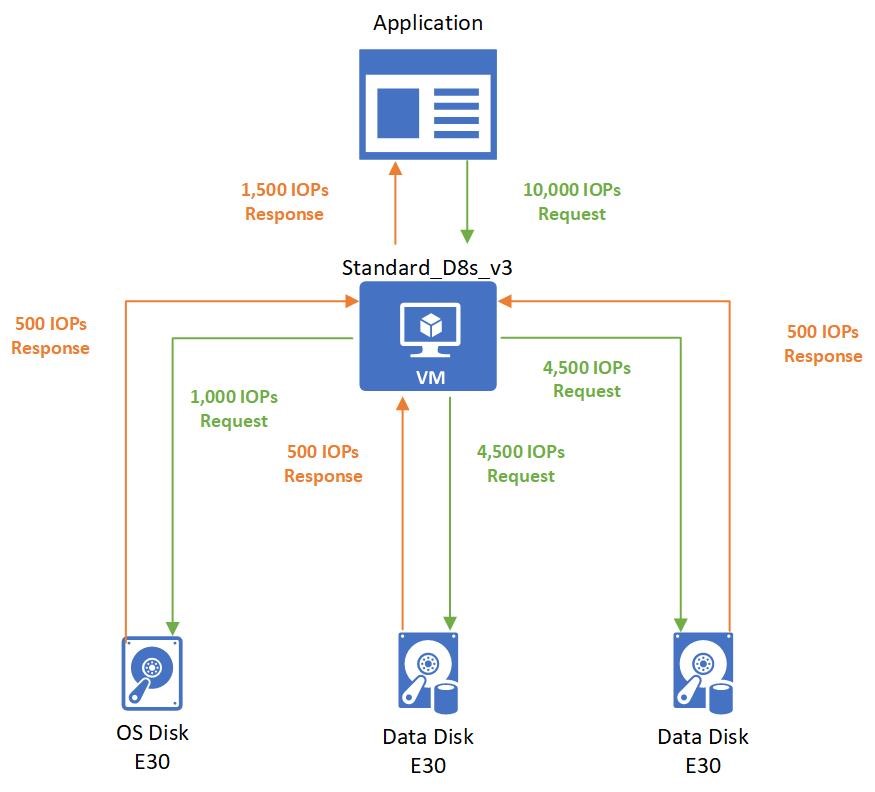
The application running on the virtual machine makes a request that requires 10,000 IOPS to the virtual machine. All of which are allowed by the VM because the Standard_D8s_v3 virtual machine can execute up to 12,800 IOPS.
The 10,000 IOPS requests are broken down into three different requests to the different disks:
- 1,000 IOPS are requested to the operating system disk.
- 4,500 IOPS are requested to each data disk.
All attached disks are E30 disks and can only handle 500 IOPS. So, they respond back with 500 IOPS each. The application's performance is capped by the attached disks, and it can only process 1,500 IOPS. The application could work at peak performance at 10,000 IOPS if better-performing disks are used, such as Premium SSD P30 disks.
Virtual machine IO capping
Setup:
- Standard_D8s_v3
- Uncached IOPS: 12,800
- P30 OS disk
- IOPS: 5,000
- Two P30 data disks × 2
- IOPS: 5,000
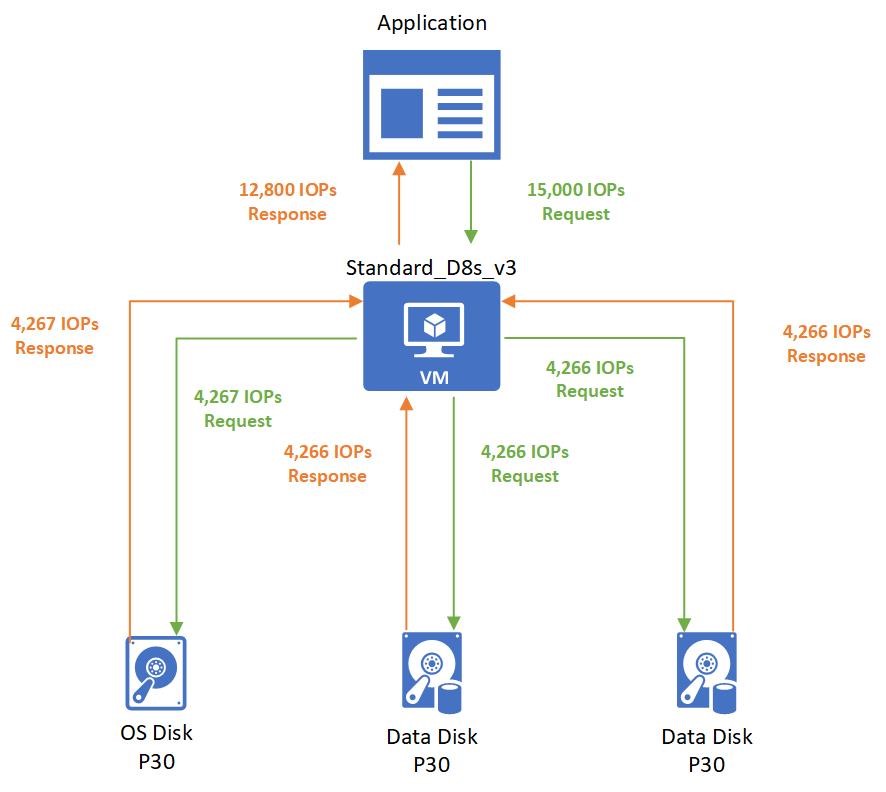
The application running on the virtual machine makes a request that requires 15,000 IOPS. Unfortunately, the Standard_D8s_v3 virtual machine is only provisioned to handle 12,800 IOPS. The application is capped by the virtual machine limits and must allocate the allotted 12,800 IOPS.
Those 12,800 IOPS requested are broken down into three different requests to the different disks:
- 4,267 IOPS are requested to the operating system disk.
- 4,266 IOPS are requested to each data disk.
All attached disks are P30 disks that can handle 5,000 IOPS. So, they respond back with their requested amounts.
Virtual machine uncached vs cached limits
Virtual machines that are enabled for both premium storage and premium storage caching have two different storage bandwidth limits. Let's look at the Standard_D8s_v3 virtual machine as an example. Here is the documentation on the Dsv3-series and the Standard_D8s_v3:
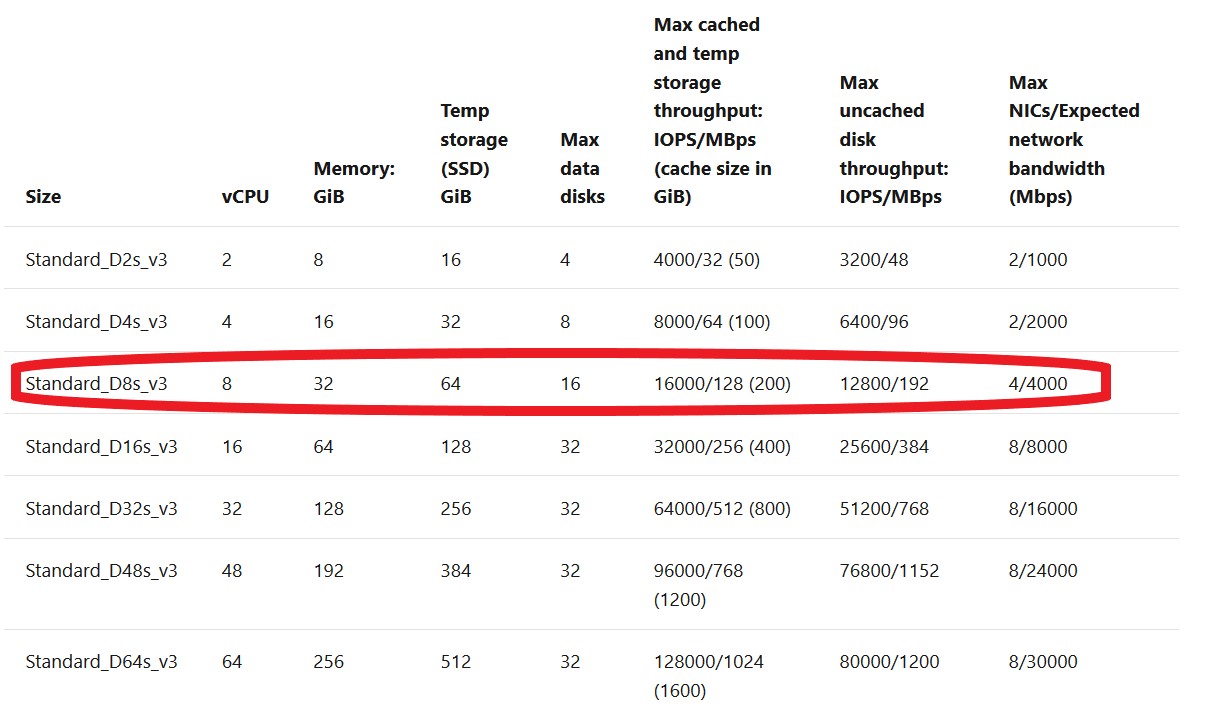
- The max uncached disk throughput is the default storage maximum limit that the virtual machine can handle.
- The max cached storage throughput limit is a separate limit when you enable host caching.
Host caching works by bringing storage closer to the VM that can be written or read to quickly. The amount of storage that is available to the VM for host caching is in the documentation. For example, you can see the Standard_D8s_v3 comes with 200 GiB of cache storage.
You can enable host caching when you create your virtual machine and attach disks. You can also turn on and off host caching on your disks on an existing VM. By default, cache-capable data disks will have read-only caching enabled. Cache-capable OS disks will have read/write caching enabled.
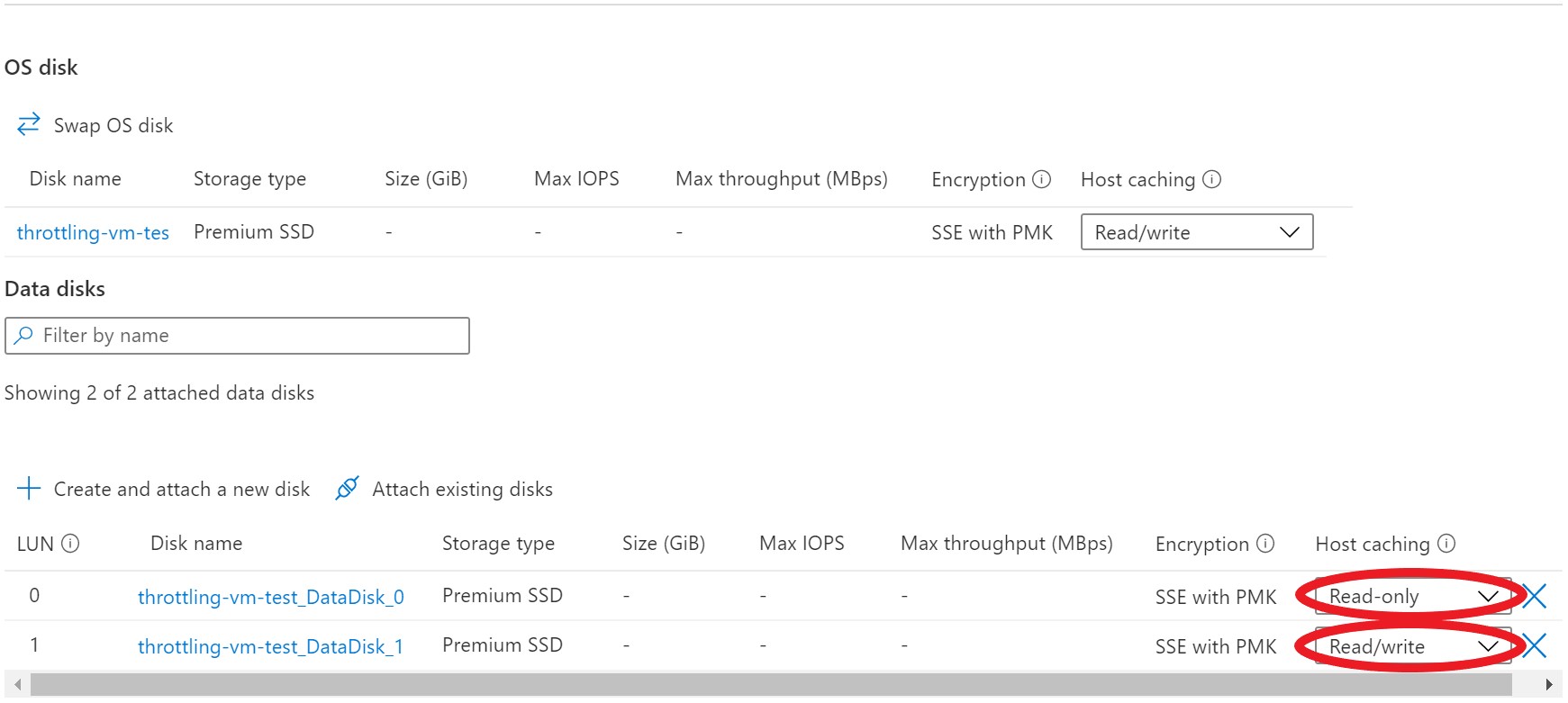
You can adjust the host caching to match your workload requirements for each disk. You can set your host caching to be:
- Read-only: For workloads that only do read operations
- Read/write: For workloads that do a balance of read and write operations
If your workload doesn't follow either of these patterns, we don't recommend that you use host caching.
Let's run through a couple examples of different host cache settings to see how it affects the data flow and performance. In this first example, we'll look at what happens with IO requests when the host caching setting is set to Read-only.
Setup:
- Standard_D8s_v3
- Cached IOPS: 16,000
- Uncached IOPS: 12,800
- P30 data disk
- IOPS: 5,000
- Host caching: Read-only
When a read is performed and the desired data is available on the cache, the cache returns the requested data. There is no need to read from the disk. This read is counted toward the VM's cached limits.
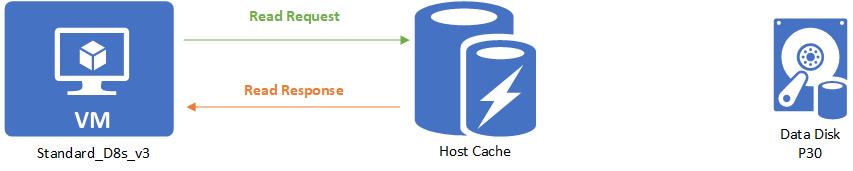
When a read is performed and the desired data is not available on the cache, the read request is relayed to the disk. Then the disk surfaces it to both the cache and the VM. This read is counted toward both the VM's uncached limit and the VM's cached limit.
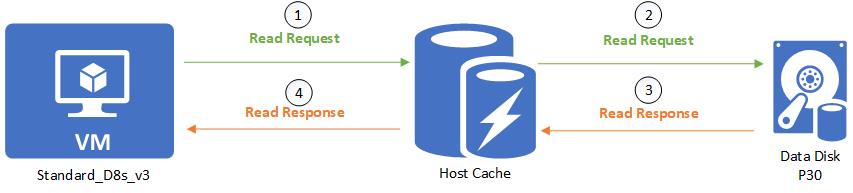
When a write is performed, the write has to be written to both the cache and the disk before it is considered complete. This write is counted toward the VM's uncached limit and the VM's cached limit.
Next let's look at what happens with IO requests when the host cache setting is set to Read/write.
Setup:
- Standard_D8s_v3
- Cached IOPS: 16,000
- Uncached IOPS: 12,800
- P30 data disk
- IOPS: 5,000
- Host caching: Read/write
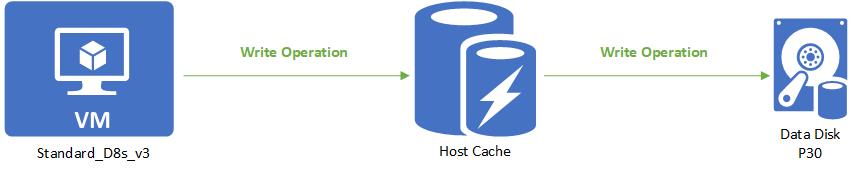
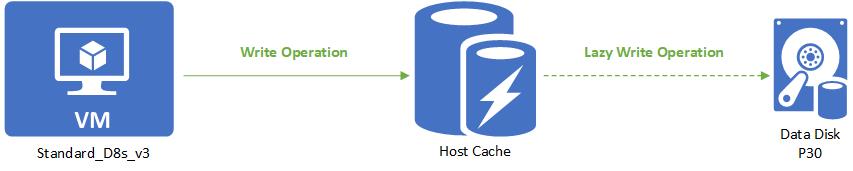
A read is handled the same way as a read-only. Writes are the only thing that's different with read/write caching. When writing with host caching is set to Read/write, the write only needs to be written to the host cache to be considered complete. The write is then lazily written to the disk when the cache is flushed periodically. Customers can additionally force a flush by issuing an f/sync or fua command. This means that a write is counted toward cached IO when it is written to the cache. When it is lazily written to the disk, it counts toward the uncached IO.
Let’s continue with our Standard_D8s_v3 virtual machine. Except this time, we'll enable host caching on the disks. This makes the VM's IOPS limit 16,000 IOPS. Attached to the VM are three underlying P30 disks that can each handle 5,000 IOPS.
Setup:
- Standard_D8s_v3
- Cached IOPS: 16,000
- Uncached IOPS: 12,800
- P30 OS disk
- IOPS: 5,000
- Host caching: Read/write
- Two P30 data disks × 2
- IOPS: 5,000
- Host caching: Read/write
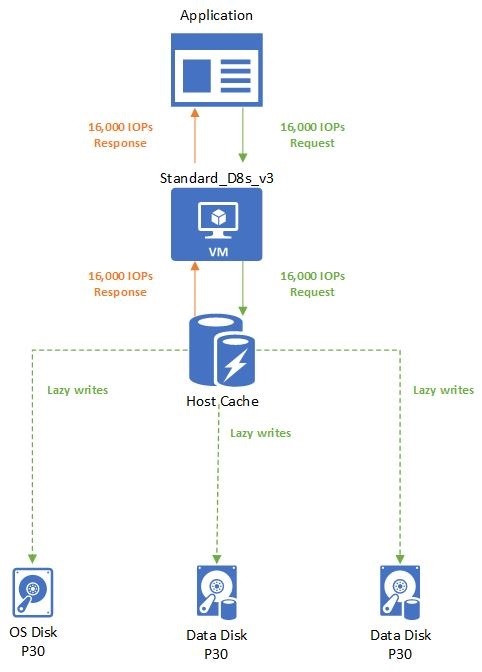
The application uses a Standard_D8s_v3 virtual machine with caching enabled. It makes a request for 16,000 IOPS. The requests are completed as soon as they are read or written to the cache. Writes are then lazily written to the attached Disks.
Combined uncached and cached limits
A virtual machine's cached limits are separate from its uncached limits. This means you can enable host caching on disks attached to a VM while not enabling host caching on other disks. This configuration allows your virtual machines to get a total storage IO of the cached limit plus the uncached limit.
Let's run through an example to help you understand how these limits work together. We'll continue with the Standard_D8s_v3 virtual machine and premium disks attached configuration.
Setup:
- Standard_D8s_v3
- Cached IOPS: 16,000
- Uncached IOPS: 12,800
- P30 OS disk
- IOPS: 5,000
- Host caching: Read/write
- Two P30 data disks × 2
- IOPS: 5,000
- Host caching: Read/write
- Two P30 data disks × 2
- IOPS: 5,000
- Host caching: Disabled
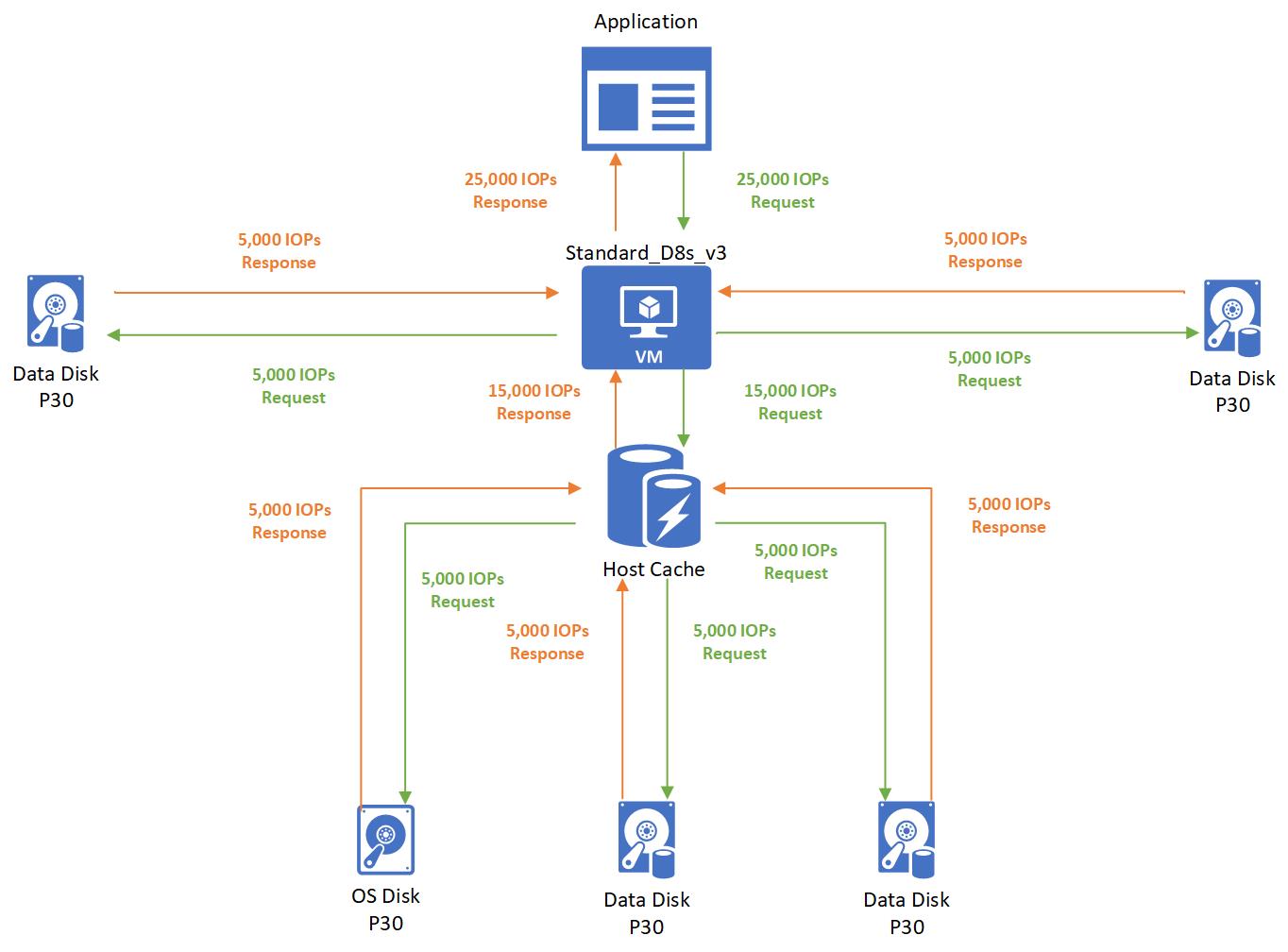
In this case, the application running on a Standard_D8s_v3 virtual machine makes a request for 25,000 IOPS. The request is broken down as 5,000 IOPS to each of the attached disks. Three disks use host caching and two disks don't use host caching.
- Since the three disks that use host caching are within the cached limits of 16,000, those requests are successfully completed. No storage performance capping occurs.
- Since the two disks that don't use host caching are within the uncached limits of 12,800, those requests are also successfully completed. No capping occurs.











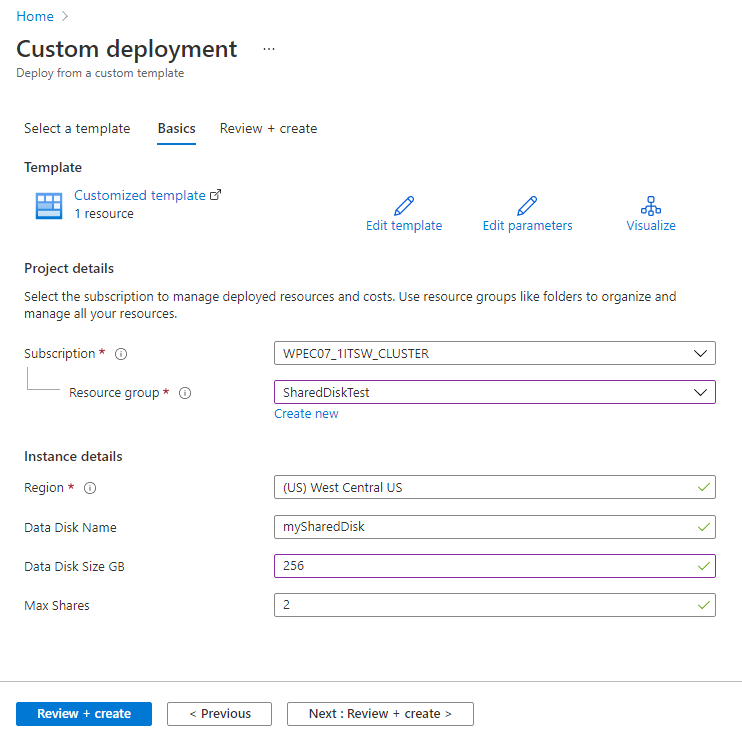
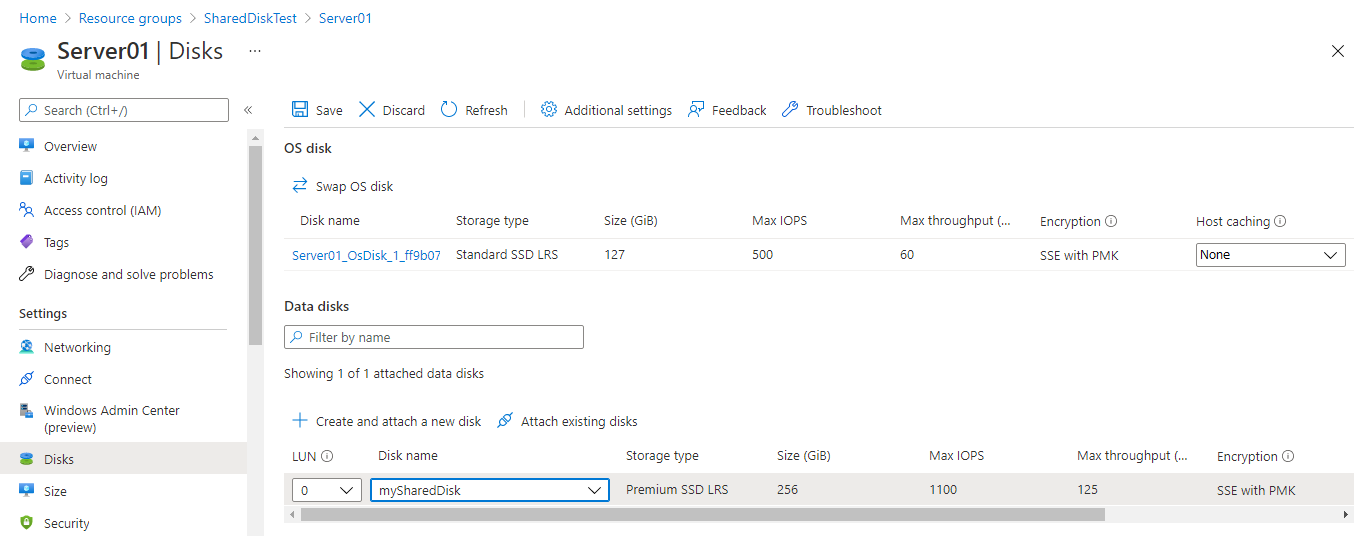
 Share an Azure managed disk
Share an Azure managed disk