AWS Storage Services: AWS offers a wide range of storage services that can be provisioned depending on your project requirements and use case. AWS storage services have different provisions for highly confidential data, frequently accessed data, and the not so frequently accessed data. You can choose from various storage types namely, object storage, file storage, block storage services, backups, and data migration options. All of which fall under the AWS Storage Services list.
AWS Elastic File System: From the aforementioned list, EFS falls under the file storage category. EFS is a file-level, fully managed, storage provided by AWS that can be accessed by multiple EC2 instances concurrently. Just like the AWS EBS, EFS is specially designed for high throughput and low latency applications.
Different Storage Classes in AWS EFS:
Standard storage class:
- This is the default storage class for EFS.
- The user is only charged for the amount of storage used.
- This is recommended for storing frequently accessed files.
Infrequently Accessed storage class(One Zone):
- Cheaper storage space.
- Recommended for rarely accessed files.
- Increased latency when reading or writing files.
- The user is charged not only for the storage of files but also charged for read and write operations.

Different Performance Modes in EFS:
General-purpose:
- Offers low latency.
- Supports a maximum of 7000 IOPS.
- As a cloudwatch metric, you can view the amount of IOPS your architecture uses and can switch to Max IOPS if required.
Max I/O:
- This is recommended when EFS needs over 7000 IOPS
- Theoretically, this mode has an unlimited I/O speed.

Different Throughput Modes in EFS:
- Burst Mode: Allows 100MBPS of burst speed per TB of storage.
- Provisioned Mode: Users can decide the max burst speed of the EFS but are charged more when speeds go beyond the default limit.

Connecting to EFS:
- Create an EFS from the AWS console. Choose the correct VPC and configuration that suits your use case.

- Create one or more EC2 servers from the EC2 dashboard as needed for your use case.

- Allow the EC2 security group to access EFS.
- Connect To EFS from your EC2 servers. Primarily there are 2 methods of connecting to EFS from EC2 servers:
- Linux NFS Client: This is the old traditional method of connecting to file systems.
- EFS Mount Helper: This is the AWS recommended and simpler solution to connect to EFS.


- Once you have connected to AWS EFS from your EC2 instances you will have a folder of any name (say EFS-Folder) which will hold all the files in the EFS. Any file created in this directory can be seen or edited from any EC2 instances that have access to the EFS.
Features of AWS EFS:
- Storage capacity: Theoretically EFS provides an infinite amount of storage capacity. This capacity grows and shrinks as required by the user.
- Fully Managed: Being an AWS managed service, EFS takes the overhead of creating, managing, and maintaining file servers and storage.
- Multi EC-2 Connectivity: EFS can be shared between any number of EC-2 instances by using mount targets.
- Note-: A mount target is an Access point for AWS EFS that is further attached to EC2 instances, allowing then access to the EFS.
- Availability: AWS EFS is region specific., however can be present in multiple availability zones in a single region.
- EC-2 instances across different availability zones can connect to EFS in that zone for a quicker access
- EFS LifeCycle Management: Lifecycle management moved files between storage classes. Users can select a retention period parameter (in number of days). Any file in standard storage which is not accessed for this time period is moved to Infrequently accessed class for cost-saving.
- Note that the retention period of the file in standard storage resets each time the file is accessed
- Files once accessed in the IA EFS class are them moved to Standard storage.
- Note that file metadata and files under 128KB cannot be transferred to the IA storage class.
- LifeCycle management can be turned on and off as deemed fit by the users.
- Durability: Multi availability zone presence accounts for the high durability of the Elastic File System.
- Transfer: Data can be transferred from on-premise to the EFS in the cloud using AWS Data Sync Service. Data Sync can also be used to transfer data between multiple EFS across regions.\
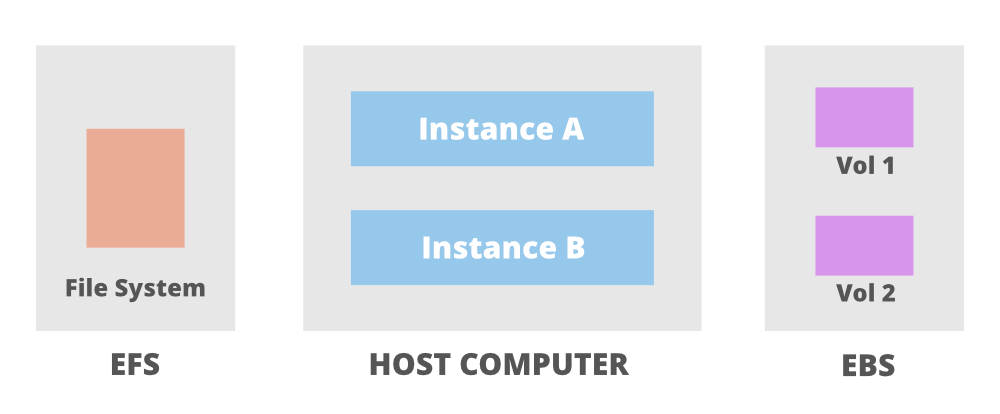
The above image shows an Elastic File System shared between two instances which are further connected to their own EBS volumes. The following are some use cases of EFS:
- Multiple server architectures: In AWS only EFS provides a shared file system. So all the applications that require multiple servers to share one single file system have to use EFS.
- Big Data Analytics: Virtually infinite capacity and extremely high throughput makes EFS highly suitable for storing files for Big data analysis.
- Reliable data file storage: EBS data is stored redundantly in a single Availability Zone however EFS data is stored redundantly in multiple Availability Zones. Making it more robust and reliable than EBS.
- Media Processing: High capacity and high throughput make EFS highly favorable for processing big media files.
Limitations of AWS Elastic File System(EFS):
There are a few limitations to consider when using AWS Elastic File System (EFS):
- EFS only supports the Network File System (NFS) protocol, so it can only be mounted and accessed by devices that support NFS.
- EFS does not support file locking, so it is not suitable for applications that require file locking for concurrent access.
- EFS does not support hard links or symbolic links.
- EFS has a maximum file size of 47.9 TB.
- EFS has a maximum throughput of 1000 MB/s per file system, and a maximum of 16,000 IOPS per file system.
- EFS has a maximum number of files and directories that can be created within a single file system, which is determined by the size of the file system. For example, a 1 TB file system can support up to about 20 million files and directories.
- EFS is only available in certain regions, and it is not possible to migrate data between regions.





