Amazon Simple storage service (S3) it is an object oriented storage service which provides the features such as data availability data scalability, security, and also used for enhance the performance. S3 also allows you to store as many objects as you’d like with an individual object size limit of five terabytes. With cost-effective storage classes and easy-to-use management features, you can optimize costs, organize data, and configure fine-tuned access controls to meet specific business, organizational, and compliance requirements.
An organization relies on services that give them security, reliability, performance, and data availability. AWS provides an S3 feature which is basically a storage class that gives all such features and also promotes scalability of the organization as well as stores data and protects them. Now let’s understand what is S3 Versioning, in layman’s term suppose in the S3 storage class, someone uploads a picture of ID:113, and suppose after some time he/she updates the picture or replace it with ID:112. Now, suppose that he/she feels that the previous one was better and wants to roll back to picture ID:113. How to get that? The S3 Versioning comes into the picture now.
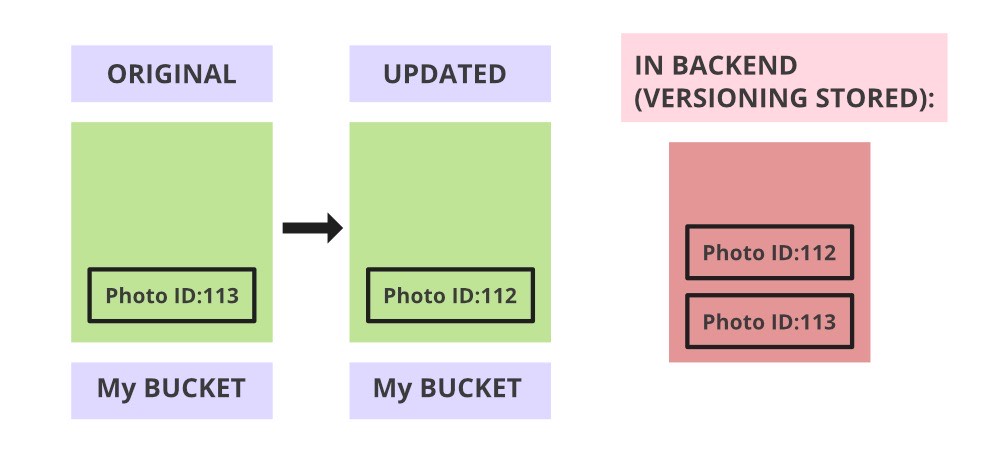
Pictorial representation of S3-Versioning
It allows storing of different versions or forms of the object. Versioning makes it easier to preserve and roll back old updates of objects, whenever needed. Moreover, it helps to restore back the object from any unintended user activity such as deleting the object unintentionally.
Implementation:
Let’s demonstrate it with step by step procedure:
Step 1: Log in to your Amazon Web Services Account>> In your console search bar, search “S3”>>then select the S3.
Step 2: Then on the Amazon S3 page click on create a bucket.

Step 3: In create bucket page, Give the bucket a Name
NOTE: name must be unique and should not contain any space or uppercase letter)>>Select any region>>Enable ACL (Access Control List basically helps to manage access to created buckets and it’s a different version of object)>>Un-tick Block all public access option (If you want to give it public access)>>Click on “I acknowledge” >> Enable Bucket Versioning>>Keep default encryption disabled>>Click on Create Bucket





Step 4: Click on your created bucket>>Click on upload>>Upload any file

Step 5: Here I have uploaded a txt file named Text1 (Content of Text1-“This is my text1”)>>Click on the file you uploaded>>Below you will find object URL>>try to hit the link in a browser, you won’t be able to access the content. Now, go to object action>>Click on the public using ACL.

Step 6: In make public page>>Click on Make Public option.

Step 7: Again, click on your uploaded file>>now copy on the object URL present below>>Try to hit on your browser.

After hitting the URL in the browser:

Step 8: Now, go to your bucket where your file is present, make some changes, and upload it again. My updated file content is “This is my updated text1”. Then follow Steps 5,6,7 again. This time you can see your updated version of the file.

Step 9: Now to get the previous content of the file or to roll back-Go to your created bucket>>Click on show version option>>You can find all your previous contents.


Step 10: To get your deleted content- Go to your bucket>>select the file>>click on delete option present on top>>Type delete in delete screen.
Step 11: Go back to the same bucket>>Click on show version
You can find your deleted file with type as “Delete marker”. To recover the deleted object, delete the “Delete marker”.

This rollback of versions of objects is what makes versioning popular.
In above we created bucket with versioning enabled
Steps To Create S3 bucket with versioning Disabled
STEP 1: Create or login to your AWS account and then you will land on AWS management console and Go to services and select S3.

STEP 3: click on create bucket and A new window will pope up, where you have to enter the details and configure your bucket
STEP 4: Configure public access settings for your bucket.
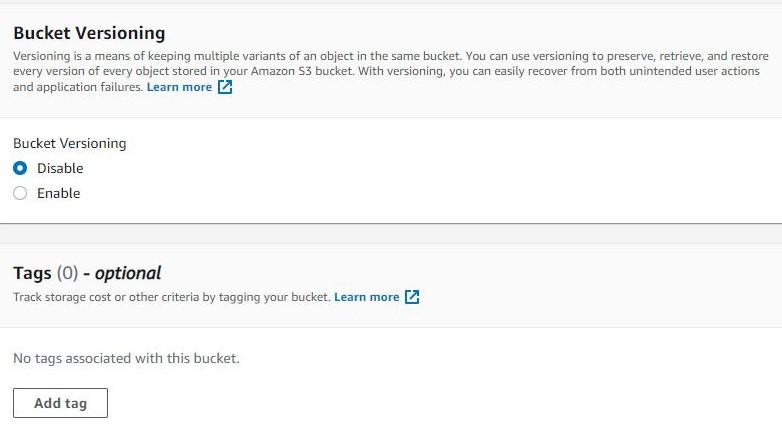
STEP 5: Configure Bucket Versioning (let it be disabled as of now) and add Tags to your bucket.
Versioning in AWS is used to store the “multiple variant of object ” inside the same bucket
STEP 6: Click on Create bucket

So we have created bucket with Versioning off in this part.

