What is Elasticache?
Elasticache is a web service used to deploy, operate, and scale an in-memory cache in the cloud.
- It improves the performance of web applications by allowing you to retrieve information from fast, managed in-memory cache instead of relying entirely on slower disk-based databases.
- For example, if you are running an online business, customers continuously asking for the information of a particular product. Instead of front-end going and always asking information for a product, you can cache the data using Elasticache.
- It is used to improve latency and throughput for many read-heavy application workloads (such as social networking, gaming, media sharing, and Q&A portals) or compute intensive workloads (such as a recommendation engine).
- Caching improves application performance by storing critical pieces of data in memory for low latency access.
- Cached information may include the results of I/O-intensive database queries or the results of computationally-intensive calculations.
 Types of Elasticache
Types of ElasticacheMemcached
- Amazon Elastic cache for Memcached is a Memcached-compatible in-memory key-value store service which will be used as a cache.
- It is an easy-to-use, high performance, in-memory data store.
- It can be used as a cache or session store.
- It is mainly used in real-time applications such as Web, Mobile Apps, Gaming, Ad-Tech, and E-Commerce.
- Databases are used to store the data on disk or SSDs while Memcached keeps its data in memory by eliminating the need to access the disk.
- Memcached uses the in-memory key-value store service that avoids the seek time delays and can access the data in microseconds.
- It is a distributed service means that it can be scaled out by adding new nodes.
- It is a multithreaded service means that it can be scaled up its compute capacity. As a result of this, its speed, scalability, simple design, efficient memory management and API support for most popular languages make Memcached a popular choice for caching use cases.
- Sub-millisecond response times
- Simplicity
- Scalability
- Community
- Caching
- Session store
Redis
- Redis stands for Remote Dictionary Server.
- It is a fast, open-source, and in-memory key-value data store.
- Its response time is in a millisecond, and also serves the millions of requests per second for real-time applications such as Gaming, AdTech, Financial services, Health care, and IoT.
- It is used for caching, session management, gaming, leaderboards, real-time analytics, geospatial, etc.
- Redis keeps its data in-memory instead of storing the data in disk or SSDs. Therefore, it eliminates the need for accessing the data from the disk.
- It avoids seek time delays, and data can be accessed in microseconds.
- It is an open-source in-memory key-value data store that supports data structures such as sorted sets and lists.
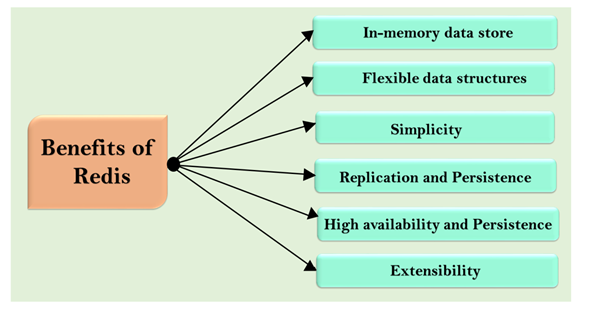
- In-memory data store
- Redis stores the data in-memory while the databases such as PostgreSQL, MongoDB, etc store the data in the disk.
- It does not store the data in a disk. Therefore, it has a faster response time.
- It takes less than a millisecond for read and write operations, and supports millions of requests per second.
- Flexible data structures
- It supports a variety of data structures to meet your application needs. The following are the data structures supported by Redis:
| Data type | Description |
|---|---|
| Strings | It is a text with up to 512MB in size. |
| Lists | It is a collection of strings. |
| Sets | It is an unordered collection of strings with the ability to intersect, union. |
| Sorted sets | The sets which are ordered by value. |
| Hashes | It is a data structure used for storing the fields and its associated values. |
| Bitmaps | It is a data type that provides bit-level operations. |
| HyperLogLogs | It is a probabilistic data structure used to estimate the unique items in a data set. |
- Simplicity
- It allows you to write fewer lines of code to store, access, and use data in your applications.
- For example, if the data of your application is stored in a Hashmap, and you want to store in a data store, then you can use the Redis hash data structure to store the data. If you store the data without any hash data structure, then you need to write many lines of code to convert from one format to another.
- Replication and Persistence
- It provides a primary-replica architecture in which data is replicated to multiple servers.
- It improves read performance and faster recovery when any server experiences failure.
- It also supports persistence by providing point-in-time backups, i.e., copying the data set to disk.
- High availability and scalability
- It builds highly available solutions with consistent performance and reliability.
- There are various options available which can adjust your cluster size such as scale in, scale out or scale up. In this way, cluster size can be changed according to the demands.
- Extensibility
- It is an open-source project supported by a vibrant community.
Differences between Memcached and Redis
| Basis for Comparison | Memcached | Redis |
|---|---|---|
| Sub-millisecond latency | Its response time is in sub-millisecond as it stores the data in memory which reads the data more quickly than disk. | Its response time is in sub-millisecond as it stores the data in memory which read the data more quickly than disk. |
| Developer ease of use | Its syntax is simple to understand and use. | Its syntax is simple to understand and use. |
| Distributed architecture | Its distributed architecture distributes the data across multiple nodes which allows to scale out more data when demand grows. | Its distributed architecture distributes the data across multiple nodes which allows to scale out more data when demand grows. |
| Supports many different programming languages | It supports languages such as C, C++, java, python, etc. | It supports languages such as C, C++, java, python, etc. |
| Advanced data structure | It does not support advanced data structures. | It supports various advanced data structures such as sets, sorted set, hashes, bit arrays, etc. |
| Multithreaded Architecture | It supports multithreaded architecture means that it has multiple processing cores. This allows you to handle multiple operations by scaling up the compute capacity. | It does not support multithreaded architecture. |
| Snapshots | It does not support the snapshots. | Redis also keeps the data in a disk as a point-in-time backup to recover from the fault. |
| Replication | It does not replicate the data. | It provides a primary replica architecture that replicates the data across multiple servers and scales the database reads. |
| Transactions | It does not support transactions. | It supports transactions that let to execute a group of commands. |
| Lua Scripting | It does not support Lua Scripting. | It allows you to execute Lua Scripts which boost performance and simplify the application. |
| Geospatial support | It does not provide Geospatial support. | It has purpose-built commands that work with geospatial data, i.e, you can find the distance between two elements or finding all the elements within a given distance. |
There are two types of Elasticache:
Since, Memcached store the data in the server's main memory, and in-memory stores don't have to go to disk for the data. Therefore, it has a faster response time and also supports millions of operations per second.
The design of Memcached is very simple that makes it powerful and easy to use in application development. It supports many languages such as Java, Ruby, Python, C, C++, etc.
An architecture of Memcached is distributed and multithreaded that makes easy to scale. You can split the data among a number of nodes that enables you to scale out the capacity by adding new nodes. It is multithreaded means that you can scale up the compute capacity.
A Community is an open-source supported by a vibrant community. Applications such as WordPress and Django use Memcached to improve performance.
It implements the high-performance in-memory cache which decreases the data access latency, increases latency, ease the load of your back-end system. It serves the cached items in less than a millisecond and also enables you to easily and cost-effectively scale your higher loads.
It is commonly used by application developers to store and manage the session data for internet-based applications. It provides sub-millisecond latency and also scales required to manage session states such as user profiles, credentials, and session state.