Serverless application Repository :
Amazon’s AWS Serverless Application Model (AWS SAM) has been a game changer in this space, making it easy for developers to create, access and deploy applications, thanks to simplified templates and code samples.
AWS Serverless Application Repositor :
The AWS Serverless Application Repository is a searchable ecosystem that allows developers to find serverless applications and their components for deployment. Its helps simplify serverless application development by providing ready-to-use apps.

Here are the basic steps:
- Search and discover. A developer can search the repository for code snippets, functions, serverless applications, and their components.
- Integrate with the AWS Lambda console. Repository components are already available to developers.
- Configure. Before deploying, developers can set environment variables, parameter values, and more. For example, you can go the plug-and-play route by adding repository components to a larger application framework, or you can deconstruct and tinker with the code for further customization. If needed, pull requests can also be submitted to repository authors.
- Deploy. Deployed applications can be managed from the AWS Management Console. A developer can follow prompts to name, describe and upload their serverless applications and components to the ecosystem where they can be shared internally and with other developers across the ecosystem. This feature makes AWS SAM a truly open-source environment
Benefits of programming in AWS SAM :
You can build serverless applications for almost any type of backend service without having to worry about scalability and managing servers. Here are some of the many benefits that building serverless applications in AWS SAM has to offer.
Low cost & efficient :
AWS SAM is low-cost and efficient for developers because of its pay-as-you-go structure. The platform only charges developers for usage, meaning you never pay for more of a service than you use.
Simplified processes :
The overarching goal of AWS SAM is ease-of-use. By design, it’s focused on simplifying application development so that programmers have more freedom to create in the open-source ecosystem.
Quick, scalable deployment :
AWS SAM makes deployment quick and simple by allowing developers to upload code to AWS and letting Amazon handle the rest. They also provide robust testing environments, so developers don’t miss a beat. All of this occurs on a platform that is easy to scale, allowing apps to grow and change to meet business objectives.
Convenient & accessible :
Undoubtedly, AWS SAM offers a convenient solution for developing in the cloud. Its serverless nature also means that it is a universally accessible platform. The wide reach of the internet makes it easy to execute code on-demand from anywhere.
Decreased time to market :
Overall, choosing a serverless application platform saves time and money that would otherwise be spent managing and operating servers or runtimes, whether on-premises or in the cloud. Because developers can create apps in a fraction of the time (think hours—not weeks or months), they are able to focus more of their attention on accelerating innovation in today’s competitive digital economy.
AWS SAM for Serverless Applications :
It’s clear that AWS SAM is a highly efficient, highly scalable, low-cost, and convenient solution for cloud programming.
But for those who haven’t yet made the switch, there are some concerns that arise from developing using AWS SAM, including:
- 1.A general lack of control over the ecosystem that developers are coding in.
- 2.Vendor lock-in that may occur when you sign up for any FaaS.
- 3.Session timeouts that require developers to rewrite code, making it more complex instead of simplifying the process.
- 4.AWS Lambda timeouts: Lambda functions are limited by a timeout value that can be configured from 3 seconds to 900 seconds (15 minutes). Lambda automatically terminates functions running longer than its time-out value.
- AWS Serverless Application Model :
The AWS Serverless Application Model (SAM) is designed to make the creation, deployment, and execution of serverless applications as simple as possible. This can be done using AWS SAM templates with just a few choice code snippets—this way, practically anyone can create a serverless app.
AWS Serverless Application Model (SAM)
- An open-source framework for building serverless applications.
- It provides shorthand syntax to express functions, APIs, databases, and event source mappings.
- You create a JSON or YAML configuration template to model your applications.
- During deployment, SAM transforms and expands the SAM syntax into AWS CloudFormation syntax. Any resource that you can declare in an AWS CloudFormation template you can also declare in an AWS SAM template.
- The SAM CLI provides a Lambda-like execution environment that lets you locally build, test, and debug applications defined by SAM templates. You can also use the SAM CLI to deploy your applications to AWS.
- You can use AWS SAM to build serverless applications that use any runtime supported by AWS Lambda. You can also use SAM CLI to locally debug Lambda functions written in Node.js, Java, Python, and Go.
- Template Anatomy
- If you are writing an AWS Serverless Application Model template alone and not via CloudFormation, the Transform section is required.
- The Globals section is unique to AWS SAM templates. It defines properties that are common to all your serverless functions and APIs. All the AWS::Serverless::Function, AWS::Serverless::Api, and AWS::Serverless::SimpleTable resources inherit the properties that are defined in the Globals section.
- The Resources section can contain a combination of AWS CloudFormation resources and AWS SAM resources.
- Overview of Syntax
- AWS::Serverless::Api
- This resource type describes an API Gateway resource. It’s useful for advanced use cases where you want full control and flexibility when you configure your APIs.
- AWS::Serverless::Application
- This resource type embeds a serverless application from the AWS Serverless Application Repository or from an Amazon S3 bucket as a nested application. Nested applications are deployed as nested stacks, which can contain multiple other resources.
- AWS::Serverless::Function
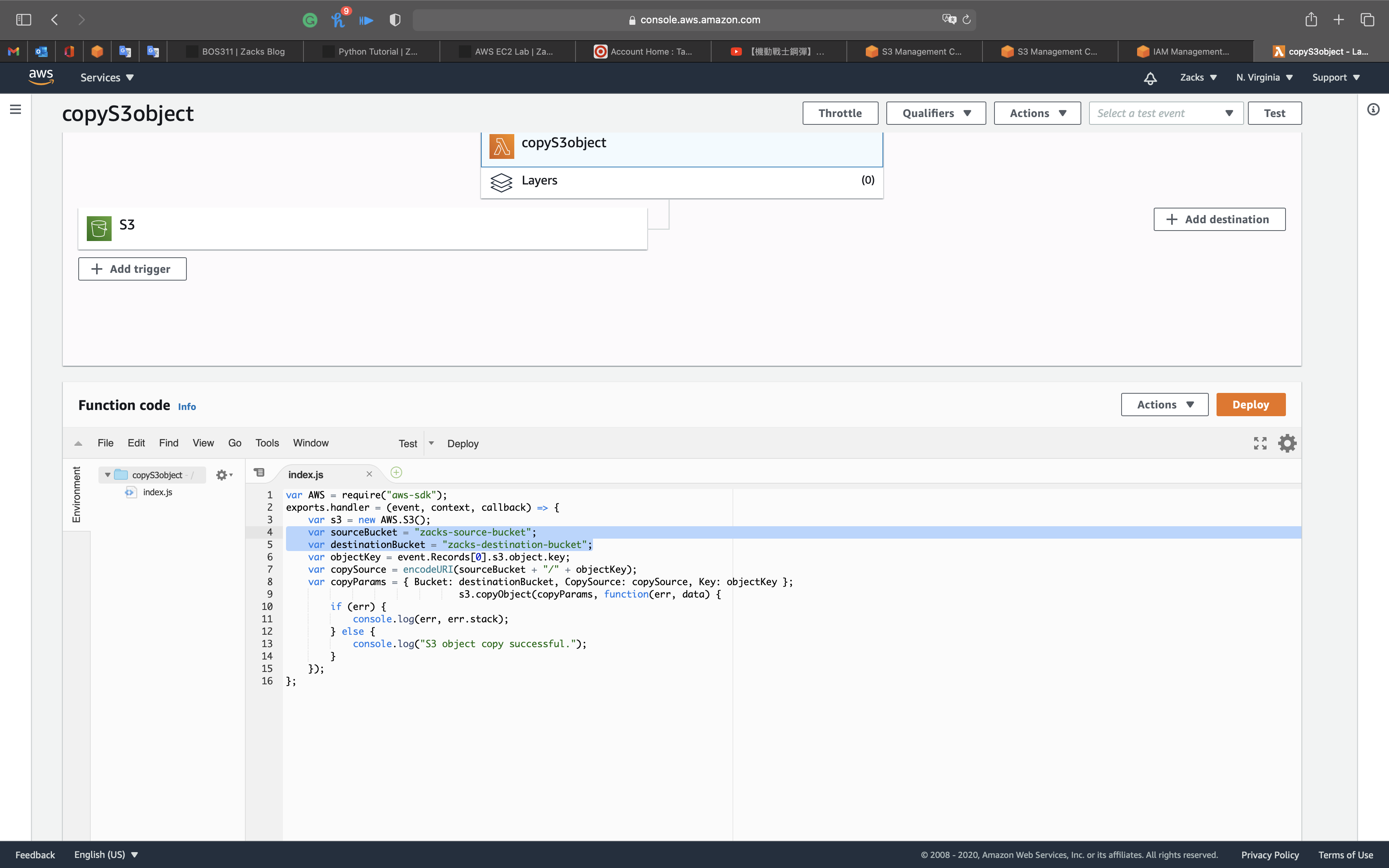
- This resource type describes configuration information for creating a Lambda function. You can describe any event source that you want to attach to the Lambda function—such as Amazon S3, Amazon DynamoDB Streams, and Amazon Kinesis Data Streams.
- AWS::Serverless::Layer Version
- This resource type creates a Lambda layer version that contains library or runtime code needed by a Lambda function. When a serverless layer version is transformed, AWS SAM also transforms the logical ID of the resource so that old layer versions are not automatically deleted by AWS CloudFormation when the resource is updated.
- AWS::Serverless::Simple Table
- This resource type provides simple syntax for describing how to create DynamoDB tables.
- AWS::Serverless::Api
- Commonly used SAM CLI commands
- The sam in it command generates pre-configured AWS SAM templates.
- The sam local command supports local invocation and testing of your Lambda functions and SAM-based serverless applications by executing your function code locally in a Lambda-like execution environment.
- The sam package and sam deploy commands let you bundle your application code and dependencies into a “deployment package” and then deploy your serverless application to the AWS Cloud.
- The sam logs command enables you to fetch, tail, and filter logs for Lambda functions.
- The output of the sam publish command includes a link to the AWS Serverless Application Repository directly to your application.
- Use sam validate to validate your SAM template.
- Controlling access to APIs
- You can use AWS SAM to control who can access your API Gateway APIs by enabling authorization within your AWS SAM template.
- A Lambda authorizer (formerly known as a custom authorizer) is a Lambda function that you provide to control access to your API. When your API is called, this Lambda function is invoked with a request context or an authorization token that are provided by the client application. The Lambda function returns a policy document that specifies the operations that the caller is authorized to perform, if any. There are two types of Lambda authorizers:
- Token based type receives the caller’s identity in a bearer token, such as a JSON Web Token (JWT) or an OAuth token.
- Request parameter based type receives the caller’s identity in a combination of headers, query string parameters, stage Variables, and $context variables.
- Amazon Cognito user pools are user directories in Amazon Cognito. A client of your API must first sign a user in to the user pool and obtain an identity or access token for the user. Then your API is called with one of the returned tokens. The API call succeeds only if the required token is valid.
- A Lambda authorizer (formerly known as a custom authorizer) is a Lambda function that you provide to control access to your API. When your API is called, this Lambda function is invoked with a request context or an authorization token that are provided by the client application. The Lambda function returns a policy document that specifies the operations that the caller is authorized to perform, if any. There are two types of Lambda authorizers:
- You can use AWS SAM to control who can access your API Gateway APIs by enabling authorization within your AWS SAM template.
- The optional Transform section of a CloudFormation template specifies one or more macros that AWS CloudFormation uses to process your template. Aside from macros you create, AWS CloudFormation also supports the AWS::Serverless transform which is a macro hosted on AWS CloudFormation.
- The AWS::Serverless transform specifies the version of the AWS Serverless Application Model (AWS SAM) to use. This model defines the AWS SAM syntax that you can use and how AWS CloudFormation processes it.
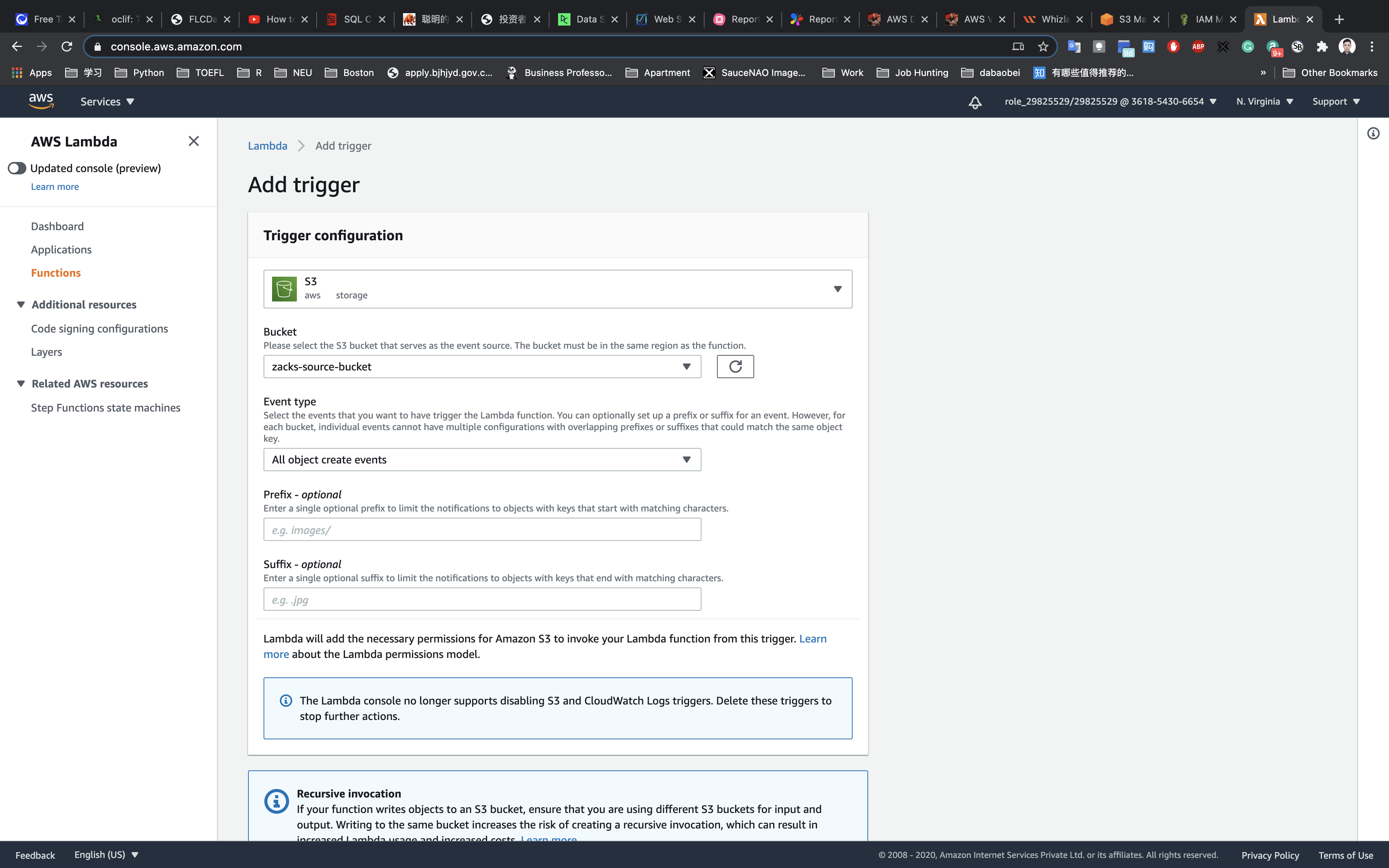
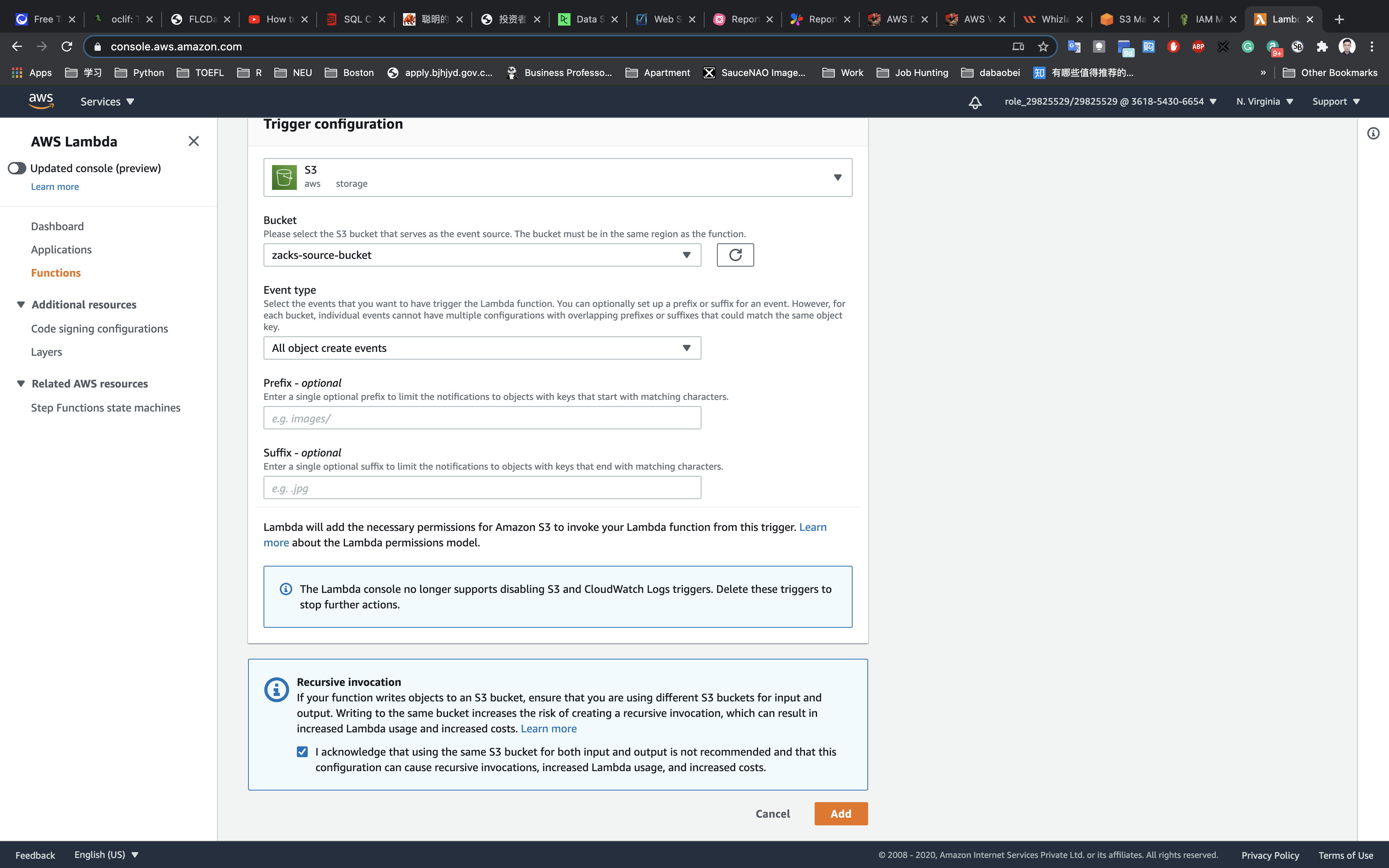
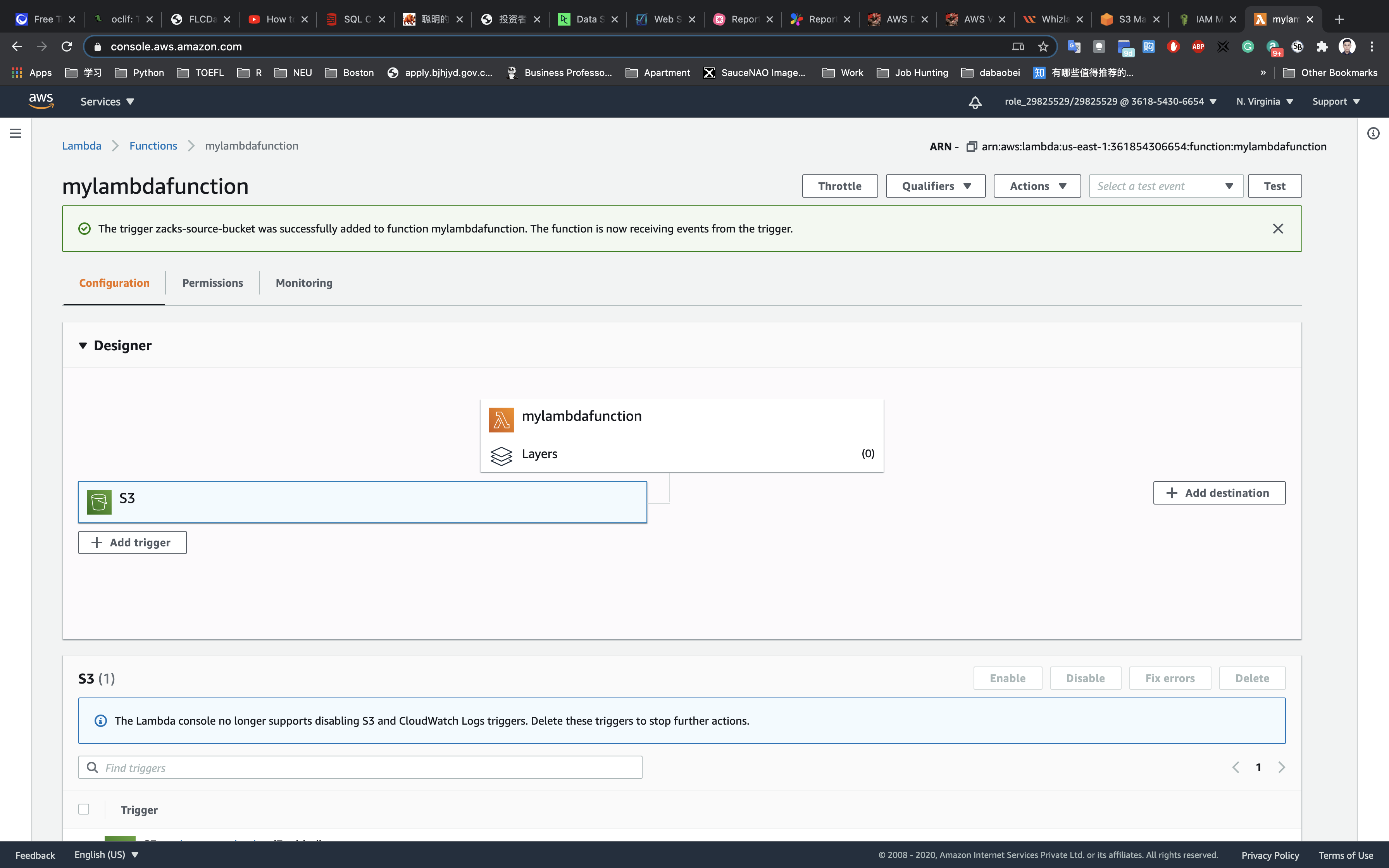
.png)
.png)





