AWS Batch :
AWS Batch is a set of batch management capabilities that enable developers, scientists, and engineers to easily and efficiently run hundreds of thousands of batch computing jobs on AWS. AWS Batch dynamically provisions the optimal quantity and different types of computing resources, such as CPU or memory-optimized compute resources, based on the volume and specific resource requirements of the batch jobs submitted.
With AWS Batch, there is no need to install and manage batch computing software or server clusters, instead, you focus on analyzing results and solving problems. AWS Batch plans, schedules, and executes your batch computing workloads using Amazon EC2, available with spot instance, and AWS compute resources with AWS Fargate or Fargate Spot.
Features of AWS Batch
The features of Amazon Batch are:
1.Dynamic Compute Resource Provisioning and Scaling
When AWS Batch is used with Farfate or Fargate spot, you will only need to set up a few concepts such as CE, job queue, and job definition. Now, you have a complete queue, scheduler, and compute architecture but you need not worry about managing a single piece of computing infrastructure.
2.AWS Batch with Fargate
When Fargate resources are used with AWS Batch, it allows you to have a completely serverless architecture for the batch jobs you need. Every batch receives the same exact amount of CPU and memory for the requests when you are dealing with Fargate. So, you will not have any wasted resource time and you also need not wait for any EC2 instance launches.
3.Priority-based Job Scheduling
One of the main features of AWS Batch is you can set up a number of queues with different priority levels. Unless the compute resources are available to execute the next job, the batch jobs are stored in queues. The AWS Batch scheduler is responsible for deciding when, where, and how to run the batch jobs that have already been submitted to a queue based on the resource requirements of the job.
4.Support for GPU Scheduling
AWS Batch supports GPU scheduling. It allows you to specify the number and type of accelerator that your jobs require as job definition input variables in AWS Batch. AWS Batch will scale up instances appropriate for your jobs based on the required number of GPUs and isolate the accelerators according to each job’s needs so that only the appropriate containers can access them.
5.Support for Popular Workflow Engines
AWS Batch supports and is integrated with the open-source and commercial workflows and languages such as Pegasus WMS, Luigi, Nextflow, Metaflow, Apache Airflow, and AWS Step Functions. This will enable you to use simple workflow languages to model your batch compute pipeline.
6.Integrated Monitoring and Logging
AWS Batch displays key operational metrics for your batch jobs in AWS Management Console. You can view metrics related to computing capacity as well as running, pending, and completed jobs. Logs for your jobs, e.g., STDERR and STDOUT, are available in AWS Management Console; the logs are also written Amazon CloudWatch Logs.
7.Support for Tightly-coupled HPC Workloads
AWS Batch supports multi-node parallel jobs, which enables you to run single jobs that span multiple EC2 instances. This feature lets you use AWS Batch to easily and efficiently run workloads such as large-scale, tightly-coupled high-performance computing (HPC) applications or distributed GPU model training.
Comparison between AWS Batch and AWS Lambda
AWS Batch
It allows developers, scientists, and engineers to run hundreds of thousands of batch computing operations on AWS quickly and easily. Based on the volume and specific resource requirements of the batch jobs submitted, it dynamically provisions the optimal quantity and kind of compute resources (e.g., CPU or memory optimized instances).
Pros
- Scalable
- Containerized
Cons
- More overhead than lambda
- Image management
AWS Lambda
AWS Lambda is a compute service that automatically maintains the underlying computing resources for you while running your code in response to events. You may use AWS Lambda to add custom logic to other AWS services or build your own back-end services that run on AWS scale, performance, and security.
Pros
- Stateless
- No deploy, no server, great sleep
- Easy to deploy
- Extensive API
- VPC Support
Cons
- Can’t execute ruby or go
- Can’t execute PHP w/o significant effort
Use cases of AWS Batch:
Financial Services: Post-trade Analytics
The use case of this is to automate the analysis of the day’s transaction costs, execution reporting, and market performance. This is achieved by:
- Firstly, send data, files, and applications to Amazon S3 where it sends the post-trade data to AWS object storage.
- AWS Batch configures the resources and schedules the timing of when to run data analytics workloads.
- After that, you have to run big data analytics tools for appropriate analysis and market predictions for the next day’s trading.
- Then, the next big step is to store the analyzed data for long-term purposes or even for further analysis.
Life Sciences: Drug Screening for Biopharma
The main purpose of this use case is to rapidly search libraries of small molecules for drug discovery. This is done by:
- Firstly, the AWS data or files are sent to Amazon S3. which further sends the small molecules and drug targets to AWS.
- The AWS batch then configures the given resources and schedules the timing of when to run high-throughput screens.
- After scheduling, big data will complete your compound screening jobs based on your AWS batch configuration.
- The results are again stored for further analysis.
Digital Media: Visual Effects Rendering
The main purpose of this use case is to automate content rendering workloads and reduce the need for human intervention due to execution dependencies or resource scheduling. This is achieved by:
- Firstly, graphic artists create a blueprint for the work that they have done.
- They schedule render jobs in the pipeline manager.
- After that, they submit the render jobs to AWS Batch. Then, AWS Batch will prefetch content from S3 or any other location.
- In the next step, they either launch the distributed job across the render farm effectively managing the dependencies or they manage the license appropriately.
- The final step is to post write back to Amazon S3 or output location.
Benefits of AWS Batch
- Fully managed: The Batch traces user requests as they travel through your entire application. Since this request aggregates the data generated by various services and resources in your application, you have a chance to get an end-to-end view of how your application is proceeding.
- Ready to use with AWS: It works with many services in AWS. Amazon Batch can be integrated with Amazon EC2, EC2 Container Service, Lambda, and Amazon Elastic Beanstalk.
- Cost-optimized resource provisioning: With AWS Batch, you can obtain insights into how your application is performing and find root causes for any issues. With Batch’s tracking feature, you can find where the issues are that are causing performance dips in your application.
Cost of AWS Batch
Now, let us take a look at the pricing of the Batch.
There is no extra charge for AWS Batch. You just need to pay for AWS resources such as EC2 instances, AWS Lambda, and AWS Fargate that you use to create, store, and run your application. You can use your Reserved Instances, Savings Plan, EC2 Spot Instances, and Fargate with AWS Batch by specifying your compute-type requirements when setting up your AWS Batch compute environments.
















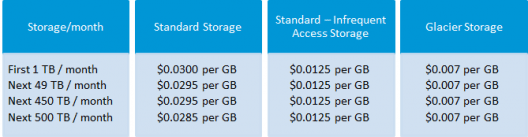
 This is suitable for performance sensitive use cases where the latency should be kept low.
This is suitable for performance sensitive use cases where the latency should be kept low. 
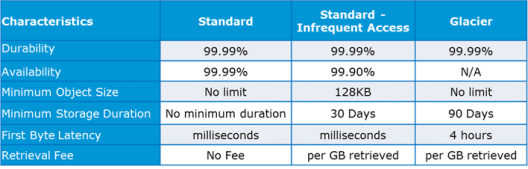

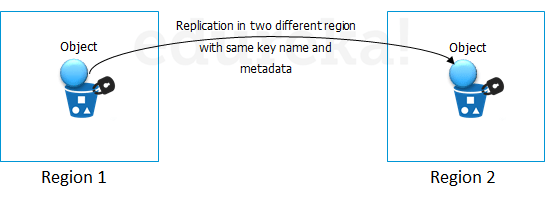

 kindle changes the shipping address back to the AWS headquarters where the Snowball has to be sent.
kindle changes the shipping address back to the AWS headquarters where the Snowball has to be sent.