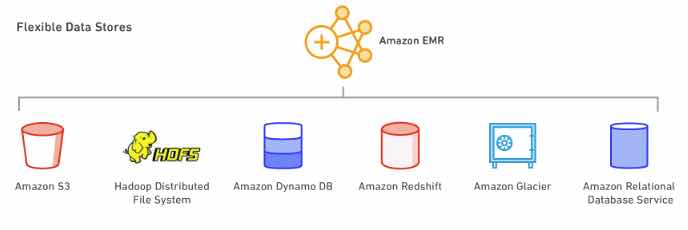
- Allows you to centralize operational data from multiple AWS services and automate tasks across your AWS resources.
Features
- Create logical groups of resources such as applications, different layers of an application stack, or production versus development environments.
- You can select a resource group and view its recent API activity, resource configuration changes, related notifications, operational alerts, software inventory, and patch compliance status.
- Collects information about your instances and the software installed on them.
- Allows you to safely automate common and repetitive IT operations and management tasks across AWS resources.
- Provides a browser-based interactive shell and CLI for managing Windows and Linux EC2 instances, without the need to open inbound ports, manage SSH keys, or use bastion hosts. Administrators can grant and revoke access to instances through a central location by using IAM policies.
- Helps ensure that your software is up-to-date and meets your compliance policies.
- Lets you schedule windows of time to run administrative and maintenance tasks across your instances.
SSM Agent is the tool that processes Systems Manager requests and configures your machine as specified in the request. SSM Agent must be installed on each instance you want to use with Systems Manager. On newer AMIs and instance types, SSM Agent is installed by default. On older versions, you must install it manually.
Capabilities
- Automation
- Allows you to safely automate common and repetitive IT operations and management tasks across AWS resources
- A step is defined as an initiated action performed in the Automation execution on a per-target basis. You can execute the entire Systems Manager automation document in one action or choose to execute one step at a time.
- Concepts
- Automation document – defines the Automation workflow.
- Automation action – the Automation workflow includes one or more steps. Each step is associated with a particular action or plugin. The action determines the inputs, behavior, and outputs of the step.
- Automation queue – if you attempt to run more than 25 Automations simultaneously, Systems Manager adds the additional executions to a queue and displays a status of Pending. When an Automation reaches a terminal state, the first execution in the queue starts.
- You can schedule Systems Manager automation document execution.
- Resource Groups
- A collection of AWS resources that are all in the same AWS region, and that match criteria provided in a query.
- Use Systems Manager tools such as Automation to simplify management tasks on your groups of resources. You can also use groups as the basis for viewing monitoring and configuration insights in Systems Manager.
- Built-in Insights
- Show detailed information about a single, selected resource group.
- Includes recent API calls through CloudTrail, recent configuration changes through Config, Instance software inventory listings, instance patch compliance views, and instance configuration compliance views.
- Systems Manager Activation
- Enable hybrid and cross-cloud management. You can register any server, whether physical or virtual to be managed by Systems Manager.
- Inventory Manager
- Automates the process of collecting software inventory from managed instances.
- You specify the type of metadata to collect, the instances from where the metadata should be collected, and a schedule for metadata collection.
- Configuration Compliance
- Scans your fleet of managed instances for patch compliance and configuration inconsistencies.
- View compliance history and change tracking for Patch Manager patching data and State Manager associations by using AWS Config.
- Customize Systems Manager Compliance to create your own compliance types.
- Run Command
- Remotely and securely manage the configuration of your managed instances at scale.
- Managed Instances – any EC2 instance or on-premises server or virtual machine in your hybrid environment that is configured for Systems Manager.
- Session Manager
- Manage your EC2 instances through an interactive one-click browser-based shell or through the AWS CLI.
- Makes it easy to comply with corporate policies that require controlled access to instances, strict security practices, and fully auditable logs with instance access details, while still providing end users with simple one-click cross-platform access to your Amazon EC2 instances.
- You can use AWS Systems Manager Session Manager to tunnel SSH (Secure Shell) and SCP (Secure Copy) traffic between a client and a server.
- Distributor
- Lets you package your own software or find AWS-provided agent software packages to install on Systems Manager managed instances.
- After you create a package in Distributor, which creates an Systems Manager document, you can install the package in one of the following ways.
- One time by using Systems Manager Run Command.
- On a schedule by using Systems Manager State Manager.
- Patch Manager
- Automate the process of patching your managed instances.
- Enables you to scan instances for missing patches and apply missing patches individually or to large groups of instances by using EC2 instance tags.
- For security patches, Patch Manager uses patch baselines that include rules for auto-approving patches within days of their release, as well as a list of approved and rejected patches.
- You can use AWS Systems Manager Patch Manager to select and apply Microsoft application patches automatically across your Amazon EC2 or on-premises instances.
- AWS Systems Manager Patch Manager includes common vulnerability identifiers (CVE ID). CVE IDs can help you identify security vulnerabilities within your fleet and recommend patches.
- You can configure actions to be performed on a managed instance before and after installing patches.
- Maintenance Window
- Set up recurring schedules for managed instances to execute administrative tasks like installing patches and updates without interrupting business-critical operations.
- Supports running four types of tasks:
- Systems Manager Run Command commands
- Systems Manager Automation workflows
- AWS Lambda functions
- AWS Step Functions tasks
- Systems Manager Document (SSM)
- Defines the actions that Systems Manager performs.
- Types of SSM Documents
|
Command document | Run Command, State Manager | Run Command uses command documents to execute commands. State Manager uses command documents to apply a configuration. These actions can be run on one or more targets at any point during the lifecycle of an instance. |
Policy document | State Manager | Policy documents enforce a policy on your targets. If the policy document is removed, the policy action no longer happens. |
Automation document | Automation | Use automation documents when performing common maintenance and deployment tasks such as creating or updating an AMI. |
Package document | Distributor | In Distributor, a package is represented by a Systems Manager document. A package document includes attached ZIP archive files that contain software or assets to install on managed instances. Creating a package in Distributor creates the package document. |
- Can be in JSON or YAML.
- You can create and save different versions of documents. You can then specify a default version for each document.
- If you want to customize the steps and actions in a document, you can create your own.
- You can tag your documents to help you quickly identify one or more documents based on the tags you’ve assigned to them.
- State Manager
- A service that automates the process of keeping your EC2 and hybrid infrastructure in a state that you define.
- A State Manager association is a configuration that is assigned to your managed instances. The configuration defines the state that you want to maintain on your instances. The association also specifies actions to take when applying the configuration.
- Parameter Store
- Provides secure, hierarchical storage for configuration data and secrets management.
- You can store values as plain text or encrypted data with SecureString.
- Parameters work with Systems Manager capabilities such as Run Command, State Manager, and Automation.
- OpsCenter
- OpsCenter helps you view, investigate, and resolve operational issues related to your environment from a central location.
- OpsCenter complements existing case management systems by enabling integrations via Amazon Simple Notification Service (SNS) and public AWS SDKs. By aggregating information from AWS Config, AWS CloudTrail logs, resource descriptions, and Amazon CloudWatch Events, OpsCenter helps you reduce the mean time to resolution (MTTR) of incidents, alarms, and operational tasks.
- Change Manager
- An enterprise change management framework for requesting, approving, implementing, and reporting on operational changes to your application configuration and infrastructure.
- From a single delegated administrator account, if you use AWS Organizations, you can manage changes across multiple AWS accounts and across AWS Regions. Alternatively, using a local account, you can manage changes for a single AWS account.
- Can be used for both AWS and on-premises resources.
- For each change template, you can add up to five levels of approvers. When it’s time to implement an approved change, Change Manager runs the Automation runbook that is specified in the associated change request.
Monitoring
- SSM Agent writes information about executions, scheduled actions, errors, and health statuses to log files on each instance. For more efficient instance monitoring, you can configure either SSM Agent itself or the CloudWatch Agent to send this log data to CloudWatch Logs.
- Using CloudWatch Logs, you can monitor log data in real-time, search and filter log data by creating one or more metric filters, and archive and retrieve historical data when you need it.
- Log System Manager API calls with CloudTrail.
Security
- Systems Managers is linked directly to IAM for access controls.
Pricing
- For your own packages, you pay only for what you use. Upon transferring a package into Distributor, you will be charged based on the size and duration of storage for that package, the number of Get and Describe API calls made, and the amount of out-of-Region and on-premises data transfer out of Distributor for those packages.
- You are charged based on the number and type of Automation steps.