|
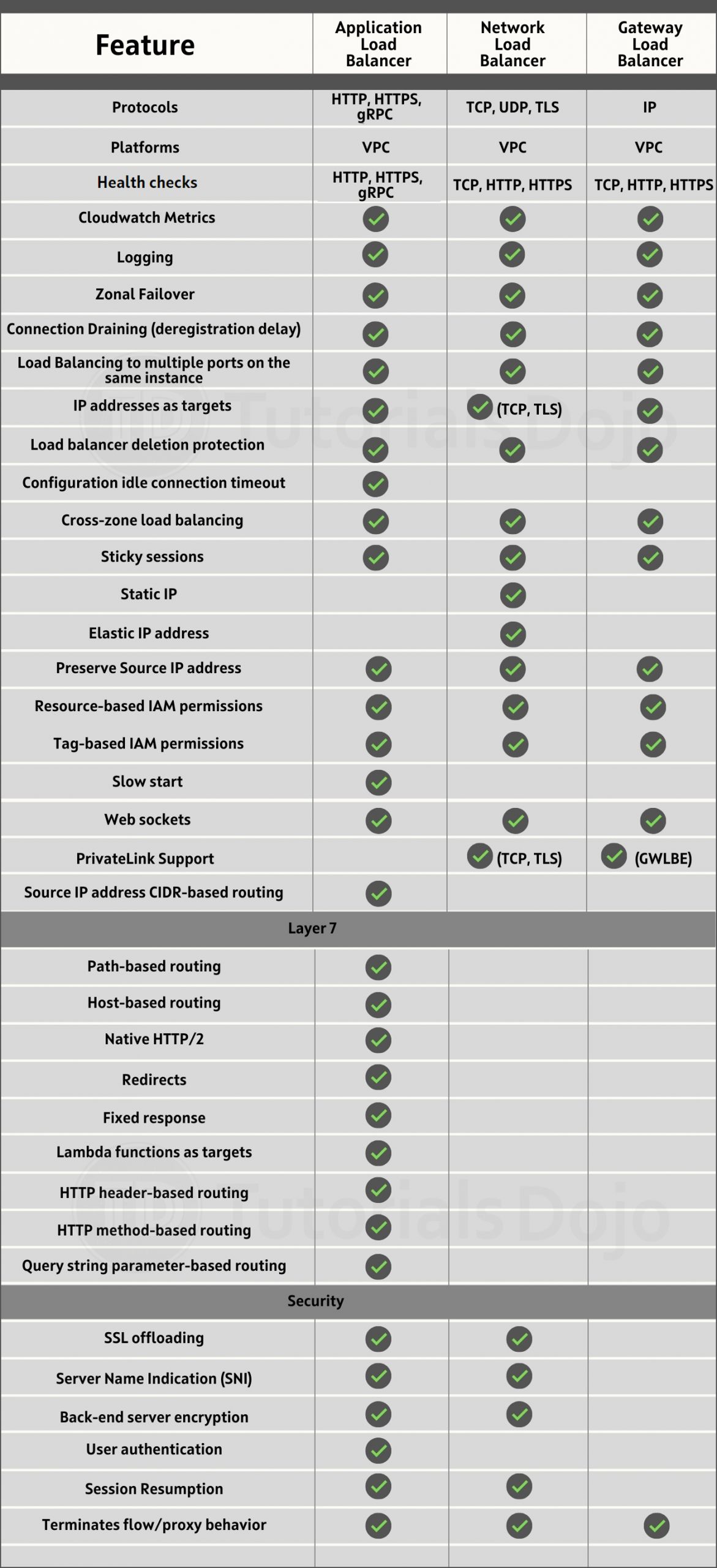
Type of storage | Object storage. You can store virtually any kind of data in any format. | Persistent block level storage for EC2 instances. | POSIX-compliant file storage for EC2 instances. |
Features | Accessible to anyone or any service with the right permissions | Deliver performance for workloads that require the lowest-latency access to data from a single EC2 instance | Has a file system interface, file system access semantics (such as strong consistency and file locking), and concurrently-accessible storage for multiple EC2 instances |
Max Storage Style | Virtually unlimited | 16 TiB for one volume | Unlimited system size |
Max File Size | Individual Amazon S3 objects can range in size to a maximum of 5 terabytes. | Equivalent to the maximum size of your volumes | 47.9 TiB for a single file |
Performance (Latency) | Low, for mixed request types, and integration with CloudFront | Lowest, consistent; SSD-backed storages include the highest performance Provisioned OPS SSD and General Purpose SSD that balance price and performance. | Low, consistent; use Max I/O mode for higher performance |
Performance (Throughput) | Multiple GBs per second; supports multi-part upload | Up to 2 GB per second. HDD-backed volumes include throughput intensive workloads and Cold HDD for less frequently accessed data. | 10+ GB per second. Bursting Throughput mode scales with the scales with the size of the file system. Provisioned throughput mode offers higher dedicated throughput than bustring throughput |
Durability | Stored redundantly across multiple AZs; has 99.999999999% durability | Stored redundantly in a single AZ | Stored redundantly across multiple AZs |
Availability | S3 Standard – 99.99% availability S3 Standard-IA – 99.9% availability S3 One Zone-IA – 99.5% availability. S3 Intelligent Tiering – 99.9% | Has 99.999% availability | 99.9% SLA. Runs in multi – AZ |
Scalability | Highly scalable | Manually increase/decrease your memory size. Attach and detach additional volumes to and from your EC2 instance to scale. | EFS file systems are elastic, and automatically grow and shrink as you add and remove files. |
Data Accessing | One to millions of connections over the wed; S3 provides a REST web services interface | Single EC2 instance in a single AZ Amazon EBS Multi-Attach a single Provisioned IOPS SSD (io1 or io2) volume to up to 16 Nitro-based instances that are in the same Availability Zone. | One to thousands of EC2 instances or on-premises servers, from multiple AZs, regions, VPCs, and accounts concurrently |
Access Control | Uses bucket policies and IAM user policies. Has Block Public Access settings to help manage public access to resources. | IAM Policies, Roles, and Security Groups | Only resources that can access endpoints in your VPC, called a mount target, can access your file system; POSIX-compliant user and group-level permissions. |
Encryption Methods | Supports SSL endpoints using the HTTPS protocol, Client-Side and Server-Side Encryption (SSE-S3, SSE-C, SSE – KMS) | Encrypts both data-at-rest and data-in-transit through EBS encryption that uses AWS KMS CMKs. | Encrypt data at rest and in transit. Data at rest encryption uses AWS KMS. Data in transit uses TLS. |
Backup and Restoration | Use versioning or cross-region replication | All EBS volume types offer durable snapshot capabilities. | EFS to EFS replication through third party tools or AWS DataSynch |
Pricing | Billing prices are based on the location of your bucket. Lower costs equals lower prices. You get cheaper prices the more you use S3 storage. | You pay Gb-month of provisioned storage, provisioned IOPS-month, GB-month of snapshot data stored in S3 | You pay more the amount of file system storage used per month. When using the Provisioned Throughput mode you pay for the throughput you provision per month. |
Use Cases | Web serving and content management, media and entertainment, backups, big data analytics, data lake | Boot volumes, transactional and NoSQL databases, data warehousing & ETL | Web serving and content management,enterprise applications, media and entertainment, home directories, database backups, developer tools, container storage, big data analytics |
Service endpoint | Can be accessed within and outside a VPC ( via S3 bucket URL) | Accessed within one’s VPC | Accessed within one’s VPC |